pytorch代码阅读、代码学习
本博客是学习中遇到问题的查阅记录,以下每个部分均摘自各部分的参考链接,有时可能会用自己的理解来记录。感谢各位前辈大佬!
目录
一、argparse.ArgumentParser()用法解析
二、torch.manual_seed(1)
三、python的class(类)中有object什么含义
四、SummaryWriter
五、Datasets与DataLoader
六、requires_grad
七、 torch.optim
八、深度学习各种学习率
九、Pytorch的nn.DataParallel
十、tqdm介绍及常用方法
十一、with torch.no_grad()的使用
十二、模型保存相关
十三、torchvision.transforms.Compose()类
十三、model.state_dict()、model.named_parameters()、model.parameters()
十四、named_children()、named_modules()
十五、nn.Sequential、nn.ModuleList和nn.ModuleDict
十六、Pytorch apply函数
一、argparse.ArgumentParser()用法解析
参考链接:https://www.cnblogs.com/yibeimingyue/p/13800159.html
argparse是python用于解析命令行参数和选项的标准模块,用于代替已经过时的optparse模块。argparse模块的作用是用于解析命令行参数。我们很多时候,需要用到解析命令行参数的程序,目的是在终端窗口(ubuntu是终端窗口,windows是命令行窗口)输入训练的参数和选项。
argparse的使用可以简化为下面四个步骤:
1、import argparse 模块导入
2、parser = argparse.ArgumentParser() 创建一个解析对象
eg. parser = argparse.ArgumentParser(description="PyTorch DeeplabV3Plus Training")
3、parser.add_argument() 向该对象中添加你要关注的命令行参数和选项,每一个add_argument方法对应一个你要关注的参数或选项
eg.parser.add_argument('--backbone', type=str, default='resnet',
choices=['resnet', 'xception', 'drn', 'mobilenet'],
help='backbone name (default: resnet)')
4、parser.parse_args() 调用parse_args()方法进行解析
eg. args = parser.parse_args()
这几步之后,使用args.backbone就可以直接获取该参数值。
如果上边例子代码是arg.py文件,那么使用python arg.py -h 时,可以获得帮助命令,-h是默认参数。
二、torch.manual_seed(1)
参考链接:https://www.zhihu.com/question/288350769
在神经网络中,参数默认是进行随机初始化的,那么如何初始化可以保证初始化每次都相同以保证结果确定。括号里的数字写多少没有影响,但是要保证每次都相同。这样比方说,别人跑你的代码,也用这个固定值初始化,然后就能得到和你跑的差不多的结果。
三、python的class(类)中有object什么含义
参考链接:https://blog.csdn.net/mao_hui_fei/article/details/83905296
https://www.cnblogs.com/chengd/articles/7287528.html
python中类的写法中有的直接在class后加个名称如:

但有的却在 标识符后边加上一个括号,里边再加一个object,如下:
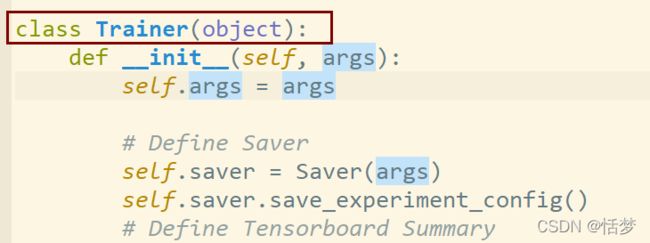
object是继承的意思,在python2.7中,如果不写object,那么这个类的命名空间只有几个对象可以操作。而写了object的因为继承了object对象会拥有很多可以操作的对象,属于类中的高级特性。具体参照这部分的第一个链接,其中有详细的解释。与此同时,该链接中也指出在python3中会默认加载object,不写也没关系。
四、SummaryWriter
参考链接:https://www.jianshu.com/p/46eb3004beca
https://blog.csdn.net/m0_46653437/article/details/111052361
from tensorboardX import SummaryWriter 主要是Pytorch利用tensorboardX创建SummaryWriter对象。PyTorch可以使用tensorboardX可视化。
TensorboardX它支持scalar, image, figure, histogram, audio, text, graph,onnx_graph, embedding,
pr_curve and videosummaries等不同的可视化展示方式。
使用方法如下:
(1)from tensorboardX import SummaryWriter 首先导入
(2)定义SummaryWriter()实例
eg.writer = SummaryWriter() 建立一个summaryWriter自动建立文件夹名字
writer = SummaryWriter("my_experiment") 指定文件名为my_experiment
writer=SummaryWriter((comment="LR_0.01_BATCH_4") 文件名带LR_0.01_BATCH_4后缀。
(3)writer.add_scalar('scalar/test', np.random.rand(), epoch),这句代码的作用就是,将我们所需要的数据保存在文件里面供可视化使用。 这里是Scalar类型,所以使用writer.add_scalar(),其他的对应使用对应的函数。第一个参数可以简单理解为保存图的名称,第二个参数是可以理解为Y轴数据,第三个参数可以理解为X轴数据。当Y轴数据不止一个时,可以使用writer.add_scalars().
(4)生成文件之后,在上边建立文件夹下的同级目录,使用 tensorboard --logdir 文件夹名可以获得最终结果
(5)write.close() 关闭
五、Datasets与DataLoader
参考资料:https://www.cnblogs.com/leokale-zz/p/11275800.html
https://zhuanlan.zhihu.com/p/35698470
先看下pytorch中Datasets的源码:
class Dataset(object):
"""An abstract class representing a Dataset.
All other datasets should subclass it. All subclasses should override
``__len__``, that provides the size of the dataset, and ``__getitem__``,
supporting integer indexing in range from 0 to len(self) exclusive.
"""
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])可以看到成员方法:_getitem__和__len__都是未实现的。我们要实现自定义Datasets类来完成数据的读取,则只需要完成这两个成员方法的重写。首先,__getitem__()方法用来从datasets中读取一条数据,这条数据包含训练图片(已CV距离)和标签,参数index表示图片和标签在总数据集中的Index。 __len__()方法返回数据集的总长度(训练集的总数)。
DataLoader:
train_loader = DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)datasets.MNIST()是一个torch.utils.data.Datasets对象,batch_size表示我们定义的batch大小(即每轮训练使用的批大小),shuffle表示是否打乱数据顺序(对于整个datasets里包含的所有数据)。对于batch_size和shuffle都是根据业务需求来人为指定的,对于Datasets对象来说,可以根据自己的数据类型来自定义,自己定义一个类,继承Datasets类。
DataLoader的完整参数表:
参考链接:https://zhuanlan.zhihu.com/p/361830892
DataLoader完整的参数表如下:
class torch.utils.data.DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None) DataLoader在数据集上提供单进程或多进程的迭代器,几个关键的参数意思:
shuffle:设置为True的时候,打乱数据集。collate_fn:如何取样本的,我们可以定义自己的函数来准确地实现想要的功能。drop_last:告诉如何处理数据集长度除于batch_size余下的数据。True就抛弃,否则保留。
collate_fn这个参数的详细解读,参考链接https://blog.csdn.net/weixin_44878336/article/details/124554884
collate_fn默认是对数据(图片)通过torch.stack()进行简单的拼接。对于分类网络来说,默认方法是可以的(因为传入的就是数据的图片),但是对于目标检测来说,train_dataset返回的是一个tuple,即(image, target)。如果我们还是采用默认的合并方法,那么就会出错,所以我们需要自定义一个方法,即collate_fn=train_dataset.collate_fn.其代码如下:
@staticmethod
def collate_fn(batch):
return tuple(zip(*batch))
上述参考链接中有具体的例子便于理解。
六、requires_grad
参考链接:https://blog.csdn.net/weixin_44696221/article/details/104269981
https://zhuanlan.zhihu.com/p/85506092
链接1中指出:requires_grad是pytorch中通用数据结构Tensor的一个属性,用于说明当前量是否需要在计算中保留对应的梯度信息。
规则是如果某个输入需要相关梯度值,则输出也需要保存相关梯度信息,这样可以保证这个输入的梯度回传。而相反的,如果所有的输入都不需要保存梯度,那么输出的requires_grad会自动设置为false。此时没有了相关的梯度值,所以在进行反向传播时会将这部分子图从计算中剔除。
requires_grad=False :误差仍然反向传播,但是梯度不更新,也就是偏置和权重不更新。
七、 torch.optim
参考链接:https://blog.csdn.net/qq_34690929/article/details/79932416
神经网络优化器,主要用于优化神经网络。pytorch中提供了torch.optim用来优化我们的神经网络,torch.optim是实现各种优化算法的包。最常用的方法都已经支持,接口很常规,以后也可以很容易地集成更复杂的方法。
要构建优化器,需要给它参数进行优化,然后可以指定优化器的参数选项,比如学习率,权重衰减等。
如:optimizer = optim.SGD(model.parameters(), lr = 0.001, momentum=0.9) 括号里分别是参数、学习率、动量。
优化器主要有:SGD、Adam、RMSProp、Momentum、AdaGrad。常用的是前两种。SGD 是最普通的优化器, 也可以说没有加速效果, 而 Momentum 是 SGD 的改良版, 它加入了动量原则. 后面的 RMSprop 又是 Momentum 的升级版. 而 Adam 又是 RMSprop 的升级版。不过并不是越先进的优化器, 结果越佳. 我们在自己的试验中可以尝试不同的优化器, 找到那个最适合你数据/网络的优化器。
参考链接:http://events.jianshu.io/p/196e0af2543d
该链接描述了torch.optim优化器的使用流程。摘录该链接中的一部分:
# torch.optim优化器的使用
'''
步骤:
1、自定义神经网络模型
1)初始化模型参数
2)重载前向传播forward()
2、定义优化器,并使用优化器实现参数优化
1)创建优化器实例(有多种优化器类型,常用SGD和Adam)
2)优化参数:
1.清空梯度 ###optimizer.zero_grad()
2.前向传播
3.计算loss
4.反向传播(根据loss来计算梯度)###loss.backward()
5.参数更新(根据梯度来更新参数)八、深度学习各种学习率
参考链接: https://blog.csdn.net/ChuanshengWang/article/details/122762668
以下均摘自这个博客:
在深度学习中,如何快速找到局部最小值非常重要,因此有很多学习率下降的方法,以图像的形式展现如下:
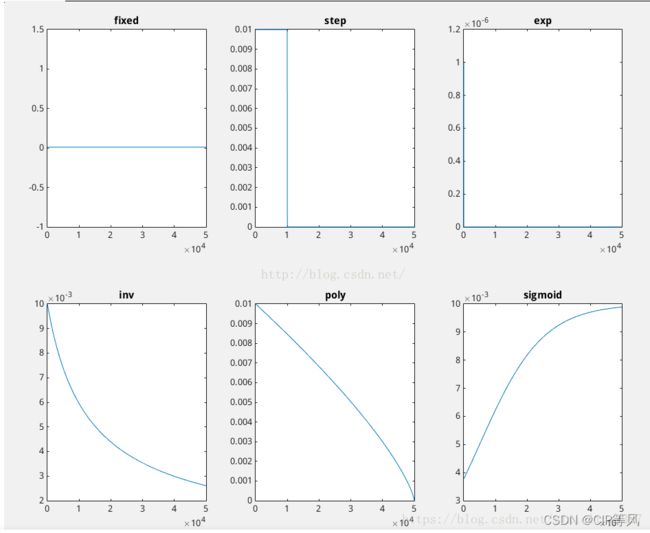
九、Pytorch的nn.DataParallel
参考链接:https://zhuanlan.zhihu.com/p/102697821
在配备多卡的GPU服务器上,当我们在上面跑程序的时候,当迭代次数或者epoch足够大的时候,我们通常会使用nn.DataParallel函数来用多个GPU来加速训练。
使用方法如下:
device_ids = [0, 1]
net = torch.nn.DataParallel(net, device_ids=device_ids)使用之后,会使用多个GPU(例子里是0和1两块)来并行训练,但是第一块的卡的显存会占用的多一些。因为Class torch.nn.Dataparallel(
module, device_ids=None, output_device=None, dim=0)
可以看到有output_device这个参数表示输出结果的device,而这最后一个参数output_device这个参数表示输出结果的device,而这个参数一般不写,它默认就是在第一块卡上,所以它的显存会占用的比其它卡要多一些。(进一步说也就是当你调用nn.DataParallel的时候,只是在你的input数据是并行的,但是你的output loss却不是这样的,每次都会在第一块GPU相加计算,这就造成了第一块GPU的负载远远大于剩余其他的显卡。)
DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总。
十、tqdm介绍及常用方法
参考链接:https://blog.csdn.net/zkp_987/article/details/81748098
Tqdm是一个快速,可扩展的Python进度条,可以在python长循环中添加一个进度提示信息。
具体可查阅上述链接。
十一、with torch.no_grad()的使用
参考链接:https://zhuanlan.zhihu.com/p/386454263
被with torch.no_grad()包住的代码,不用跟踪反向梯度计算。具体例子看原链接。
十二、模型保存相关
摘自链接:https://blog.csdn.net/sailist/article/details/103862438
https://blog.csdn.net/qq_38276972/article/details/114524315
https://blog.csdn.net/qq_40714949/article/details/115300506
只保存模型用于以后的推断的话使用.pth或.pt,这样可以直接加载模型:
torch.save(model, "model.pth") # or .pt
model = torch.load("model.pth")
断点保存的话则使用.tar,加载的时候模型需要使用load_state_dict()方法:
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
...
}, "checkpoint.tar")
...
checkpoint = torch.load("checkpoint.tar")
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
# 1.只保存和加载模型参数,在加载模型参数需要先搭建网络结构
torch.save(model.state_dict(), PATH) # 推荐的文件后缀名是pt或pth
model = TheModelClass()#搭建网络结构
model.load_state_dict(torch.load(PATH))
# 2.保存和加载整个模型 ,在加载模型前不需要重新搭建网络结构
torch.save(model, PATH)
model = torch.load(PATH)
注意:
(1)只保存网络中的参数速度快, 占内存少,推荐使用。但是调用网络的参数时,新网络需要自己定义网络,再使用上面的调用指令。其中的参数名称与结构要与保存模型中的一致,可以是部分网络比如只使用VGG的前几层,相对灵活,便于对网络进行修改。
(2)调用整个网络则无需自定义网络可以直接调用。保存时已把网络结构保存,比较死板,不能调整网络结构。
在pytorch中保存中途训练的模型时,如果只保留参数能进行测试,但是不方便恢复训练。
实际上还需要保存优化器的状态,以及一些其他有助于恢复训练的信息(如loss等):
def save_checkpoint(epoch, epochs_since_improvement, model, optimizer, loss, is_best):
state = {'epoch': epoch,
'epochs_since_improvement': epochs_since_improvement,
'loss': loss,
'model': model,
'optimizer': optimizer}
filename = 'checkpoint_' + str(epoch) + '_' + str(loss) + '.tar'
torch.save(state, filename)
if is_best:
torch.save(state, 'BEST_checkpoint.tar')
十三、torchvision.transforms.Compose()类
参考资料:https://blog.csdn.net/wangkaidehao/article/details/104520022/
https://blog.csdn.net/weixin_43135178/article/details/115133115
这个类的主要作用是串联多个图片变换的操作,把多个步骤整合在一起。
class torchvision.transforms.Compose(transforms):
# Composes several transforms together.
# Parameters: transforms (list of Transform objects) – list of transforms to compose.
例如:
transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomScaleCrop(513,513),
transforms.RandomGaussianBlur(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
transforms.ToTensor()])transforms中的函数:
__all__ = ["Compose", "ToTensor", "PILToTensor", "ConvertImageDtype", "ToPILImage", "Normalize", "Resize", "Scale","CenterCrop", "Pad", "Lambda", "RandomApply", "RandomChoice", "RandomOrder", "RandomCrop","RandomHorizontalFlip", "RandomVerticalFlip", "RandomResizedCrop", "RandomSizedCrop", "FiveCrop", "TenCrop","LinearTransformation", "ColorJitter", "RandomRotation", "RandomAffine", "Grayscale", "RandomGrayscale","RandomPerspective", "RandomErasing", "GaussianBlur", "InterpolationMode", "RandomInvert", "RandomPosterize",
"RandomSolarize", "RandomAdjustSharpness", "RandomAutocontrast", "RandomEqualize"]
常用的有:
Resize 把给定的图片resize到given size
Normalize 用均值和标准差归一化张量图像
ToTensor convert a PIL image to tensor (H*W*C) in range [0,255] to a torch.Tensor(C*H*W) in the range [0.0,1.0]
CenterCrop 在图片的中间区域进行裁剪
RandomCrop 在一个随机的位置进行裁剪
FiceCrop 把图像裁剪为四个角和一个中心
RandomResizedCrop 将PIL图像裁剪成任意大小和纵横比
ToPILImage convert a tensor to PIL image
RandomHorizontalFlip 以0.5的概率水平翻转给定的PIL图像
RandomVerticalFlip 以0.5的概率竖直翻转给定的PIL图像
Grayscale 将图像转换为灰度图像
RandomGrayscale 将图像以一定的概率转换为灰度图像
ColorJitter 随机改变图像的亮度对比度和饱和度
十三、model.state_dict()、model.named_parameters()、model.parameters()
学习参考链接:https://blog.csdn.net/weixin_41712499/article/details/110198423
model.named_parameters()与model.parameters(),这两者唯一的差别在于named_parameters()返回的list中,每个元组打包了2个内容,分别是layer-name和layer-param,而parameters()只有后者。
import torch
from torchvision import models
from torchvision.ops import misc
body = models.resnet.__dict__['resnet50'](
pretrained=False, norm_layer=misc.FrozenBatchNorm2d)
for name, parameter in body.named_parameters():
print(name)
# print(parameter)
# for parameter in body.parameters():
# print(parameter)结果:
conv1.weight
layer1.0.conv1.weight
layer1.0.conv2.weight
layer1.0.conv3.weight
layer1.0.downsample.0.weight
layer1.1.conv1.weight
layer1.1.conv2.weight
layer1.1.conv3.weight
layer1.2.conv1.weight
layer1.2.conv2.weight
layer1.2.conv3.weight
layer2.0.conv1.weight
layer2.0.conv2.weight
layer2.0.conv3.weight
layer2.0.downsample.0.weight
layer2.1.conv1.weight
layer2.1.conv2.weight
layer2.1.conv3.weight
layer2.2.conv1.weight
layer2.2.conv2.weight
layer2.2.conv3.weight
layer2.3.conv1.weight
layer2.3.conv2.weight
layer2.3.conv3.weight
layer3.0.conv1.weight
layer3.0.conv2.weight
layer3.0.conv3.weight
layer3.0.downsample.0.weight
layer3.1.conv1.weight
layer3.1.conv2.weight
layer3.1.conv3.weight
layer3.2.conv1.weight
layer3.2.conv2.weight
layer3.2.conv3.weight
layer3.3.conv1.weight
layer3.3.conv2.weight
layer3.3.conv3.weight
layer3.4.conv1.weight
layer3.4.conv2.weight
layer3.4.conv3.weight
layer3.5.conv1.weight
layer3.5.conv2.weight
layer3.5.conv3.weight
layer4.0.conv1.weight
layer4.0.conv2.weight
layer4.0.conv3.weight
layer4.0.downsample.0.weight
layer4.1.conv1.weight
layer4.1.conv2.weight
layer4.1.conv3.weight
layer4.2.conv1.weight
layer4.2.conv2.weight
layer4.2.conv3.weight
fc.weight
fc.bias上边代码中注释掉的第一个print(parameter)以及
for parameter in body.parameters():
print(parameter)
的结果是一致的。
如果直接使用
for namepara in body.named_parameters():
print(namepara)其结果如下:

model.state_dict()与model.named_parameters()间的差别:
(1)它们返回值类型不同。model.state_dict()是将layer_name : layer_param的键值信息存储为dict形式,而model.named_parameters()则是打包成一个元组然后再存到list当中。
(2)存储的模型参数的种类不同。model.state_dict()存储的是该model中包含的所有layer中的所有参数;而model.named_parameters()则只保存可学习、可被更新的参数
(3)返回的值的require_grad属性不同。model.state_dict()所存储的模型参数tensor的require_grad属性都是False,而model.named_parameters()的require_grad属性都是True。
十四、named_children()、named_modules()
参考链接:https://blog.csdn.net/watermelon1123/article/details/98036360
named_children( ),返回包含子模块的迭代器,同时产生模块的名称以及模块本身。
named_modules( ),返回网络中所有模块的迭代器,同时产生模块的名称以及模块本身。
访问方法:model=testmodel()
for name, module in model.named_children():
print('children module:', name)
for name, module in model.named_modules():
print('modules:', name)
import torch
from torchvision import models
from torchvision.ops import misc
body = models.resnet.__dict__['resnet50'](
pretrained=False, norm_layer=misc.FrozenBatchNorm2d)
for name, module in body.named_children():
print('children module:', name)
for name, module in body.named_modules():
print('modules:', name)children module: conv1
children module: bn1
children module: relu
children module: maxpool
children module: layer1
children module: layer2
children module: layer3
children module: layer4
children module: avgpool
children module: fc
modules:
modules: conv1
modules: bn1
modules: relu
modules: maxpool
modules: layer1
modules: layer1.0
modules: layer1.0.conv1
modules: layer1.0.bn1
modules: layer1.0.conv2
modules: layer1.0.bn2
modules: layer1.0.conv3
modules: layer1.0.bn3
modules: layer1.0.relu
modules: layer1.0.downsample
modules: layer1.0.downsample.0
modules: layer1.0.downsample.1
modules: layer1.1
modules: layer1.1.conv1
modules: layer1.1.bn1
modules: layer1.1.conv2
modules: layer1.1.bn2
modules: layer1.1.conv3
modules: layer1.1.bn3
modules: layer1.1.relu
modules: layer1.2
modules: layer1.2.conv1
modules: layer1.2.bn1
modules: layer1.2.conv2
modules: layer1.2.bn2
modules: layer1.2.conv3
modules: layer1.2.bn3
modules: layer1.2.relu
modules: layer2
modules: layer2.0
modules: layer2.0.conv1
modules: layer2.0.bn1
modules: layer2.0.conv2
modules: layer2.0.bn2
modules: layer2.0.conv3
modules: layer2.0.bn3
modules: layer2.0.relu
modules: layer2.0.downsample
modules: layer2.0.downsample.0
modules: layer2.0.downsample.1
modules: layer2.1
modules: layer2.1.conv1
modules: layer2.1.bn1
modules: layer2.1.conv2
modules: layer2.1.bn2
modules: layer2.1.conv3
modules: layer2.1.bn3
modules: layer2.1.relu
modules: layer2.2
modules: layer2.2.conv1
modules: layer2.2.bn1
modules: layer2.2.conv2
modules: layer2.2.bn2
modules: layer2.2.conv3
modules: layer2.2.bn3
modules: layer2.2.relu
modules: layer2.3
modules: layer2.3.conv1
modules: layer2.3.bn1
modules: layer2.3.conv2
modules: layer2.3.bn2
modules: layer2.3.conv3
modules: layer2.3.bn3
modules: layer2.3.relu
modules: layer3
modules: layer3.0
modules: layer3.0.conv1
modules: layer3.0.bn1
modules: layer3.0.conv2
modules: layer3.0.bn2
modules: layer3.0.conv3
modules: layer3.0.bn3
modules: layer3.0.relu
modules: layer3.0.downsample
modules: layer3.0.downsample.0
modules: layer3.0.downsample.1
modules: layer3.1
modules: layer3.1.conv1
modules: layer3.1.bn1
modules: layer3.1.conv2
modules: layer3.1.bn2
modules: layer3.1.conv3
modules: layer3.1.bn3
modules: layer3.1.relu
modules: layer3.2
modules: layer3.2.conv1
modules: layer3.2.bn1
modules: layer3.2.conv2
modules: layer3.2.bn2
modules: layer3.2.conv3
modules: layer3.2.bn3
modules: layer3.2.relu
modules: layer3.3
modules: layer3.3.conv1
modules: layer3.3.bn1
modules: layer3.3.conv2
modules: layer3.3.bn2
modules: layer3.3.conv3
modules: layer3.3.bn3
modules: layer3.3.relu
modules: layer3.4
modules: layer3.4.conv1
modules: layer3.4.bn1
modules: layer3.4.conv2
modules: layer3.4.bn2
modules: layer3.4.conv3
modules: layer3.4.bn3
modules: layer3.4.relu
modules: layer3.5
modules: layer3.5.conv1
modules: layer3.5.bn1
modules: layer3.5.conv2
modules: layer3.5.bn2
modules: layer3.5.conv3
modules: layer3.5.bn3
modules: layer3.5.relu
modules: layer4
modules: layer4.0
modules: layer4.0.conv1
modules: layer4.0.bn1
modules: layer4.0.conv2
modules: layer4.0.bn2
modules: layer4.0.conv3
modules: layer4.0.bn3
modules: layer4.0.relu
modules: layer4.0.downsample
modules: layer4.0.downsample.0
modules: layer4.0.downsample.1
modules: layer4.1
modules: layer4.1.conv1
modules: layer4.1.bn1
modules: layer4.1.conv2
modules: layer4.1.bn2
modules: layer4.1.conv3
modules: layer4.1.bn3
modules: layer4.1.relu
modules: layer4.2
modules: layer4.2.conv1
modules: layer4.2.bn1
modules: layer4.2.conv2
modules: layer4.2.bn2
modules: layer4.2.conv3
modules: layer4.2.bn3
modules: layer4.2.relu
modules: avgpool
modules: fc可以看到named_children只输出了子module,而named_modules输出了包括named_children结果以及下面所有的modules。
十五、nn.Sequential、nn.ModuleList和nn.ModuleDict
学习参考链接:https://blog.csdn.net/QLeelq/article/details/115208866
nn.Sequential:顺序性,各网络层之间严格按顺序执行,常用于block构建。内部实现了forward函数,因此可以不用写forward函数。因为各网络层严格按顺序进行排列,所以必须确保一个模块的输出大小和下一个模块的输入大小一致。nn.Sequential中可以使用OrderedDict来指定每个module的名字。
nn.ModuleList:迭代性,常用于大量重复网络构建,通过for循环实现重复构建。nn.ModuleLIst内部没有实现forward函数。nn.ModuleList里面储存了不同 module,并自动将每个 module 的 parameters 添加到网络之中的容器(注册),里面的module是按照List的形式顺序存储的,但是在forward中调用的时候可以随意组合。可以任意将 nn.Module 的子类 (比如 nn.Conv2d, nn.Linear 之类的) 加到这个 list 里面,方法和 Python 自带的 list 一样,也就是说它可以使用 extend,append 等操作。
nn.ModuleDict:迭代性,常用于可选择的网络层。nn.ModuleDict内部没有实现forward函数。ModuleDict可以像常规Python字典一样索引,同样自动将每个 module 的 parameters 添加到网络之中的容器(注册)。同样的它可以使用OrderedDict、dict或者ModuleDict对它进行update,也就是追加。
十六、Pytorch apply函数
学习参考链接:https://blog.csdn.net/hxxjxw/article/details/119725864
pytorch中的model.apply(fn)会递归地将函数fn应用到父模块的每个子模块submodule,也包括model这个父模块自身。经常用于初始化init_weights的操作,也就是说fn经常是一个初始化权重的函数。
参考链接中有具体的例子。