Pytorch学习笔记----RNN/LSTM/GRU
Pytorch学习笔记-----RNN
- RNN
-
- RNNCell
- How to use RNNCell
- How to use RNN
- Using RNNCell
- one-hot编码
-
- python列表解析
-
- 基本列表解析
- 条件列表解析
- 嵌套列表解析
- Long Short-Term Memory(LSTM)
-
- LSTM的基本信息
- LSTM的计算过程
- 双向RNN(Bidirectional RNNS)
- GRU
- Example of GRU
-
- 过程
-
- Preparing Data
- Result
- Preference
RNN
Recurrent Neural Network : RNN.
隐藏层之间有连接,是主要用于序列数据的分类,预测等处理的神经网络。
RNNCell
RNN的运行模式是左侧的图,拆分开来为右侧
h(t-1)送入RNNCell求h(t),h(0)代表先验

RNNCell的本质是一个Linear Layer
for x in X:
h=Linear(x,h)
#h(1)=linear(x1,h0)
#h(2)=linear(x2,h1)
可以将两次线性运算转化为一次线性运算,将w_hh和w_ih拼接成一个矩阵,x和h拼接成一个矩阵,做矩阵乘法即可

How to use RNNCell


import torch
batch_size=1
seq_len=3 #输入序列长度为3
input_size=4 #输入数据是3维向量
hidden_size=2 #隐藏层是2维向量
cell=torch.nn.RNNCell(input_size=input_size,hidden_size=hidden_size)
#(seq,batch,features)
#randn()从标准正态分布(均值为0,方差为1)中抽取的一组随机数。返回一个张量
dataset=torch.randn(seq_len,batch_size,input_size)
#返回一个全0的所给维度的张量h0
hidden=torch.zeros(batch_size,hidden_size)
for idx,input in enumerate(dataset):
print('='*20,idx,'='*20)
print("Input size: ",input.shape)
hidden=cell(input,hidden)
print('outputs size: ',hidden.shape)
print(hidden)
How to use RNN
 out中的input_size变为hidden_size
out中的input_size变为hidden_size


Using RNNCell

one-hot编码
One-Hot 编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
One-Hot 编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。


python列表解析
列表推导式提供了一个创建链表的简单途径,每一个列表推导式包括在一个 for 语句之后的表达式,零或多个 for 或 if 语句。返回值是由 for 或 if 子句之后的表达式得到的元素组成的列表。如果想要得到一个元组,必须要加上括号。
基本列表解析
data=[12,2,3,4]
c=[x for x in data] #[12, 2, 3, 4]
d=[x**2 for x in data] #[144, 4, 9, 16]
e=[(x,x**2) for x in data]
#[(12, 144), (2, 4), (3, 9), (4, 16)]
条件列表解析
f=[x*3 for x in data if x%2==0] #[36, 6, 12]
嵌套列表解析
x_data=[1,0,2,2,3]
one_hot_lookup=[[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]]
x_one_hot=[one_hot_lookup[x] for x in x_data]
# [[0, 1, 0, 0], [1, 0, 0, 0], [0, 0, 1, 0], [0, 0, 1, 0], [0, 0, 0, 1]]
Long Short-Term Memory(LSTM)
LSTM的基本信息

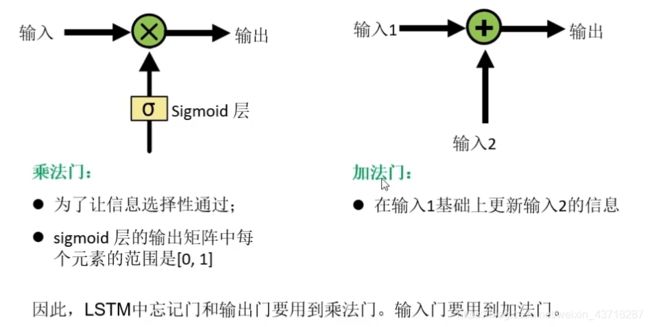 LSTM基本结构
LSTM基本结构
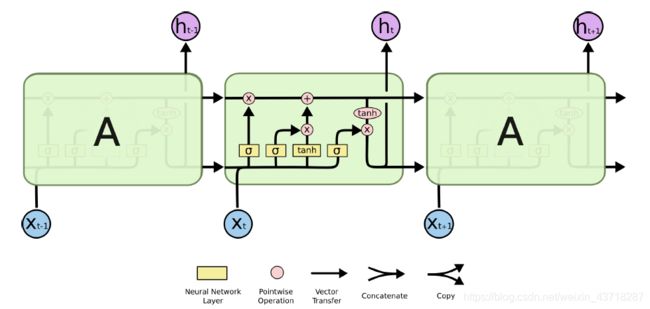
LSTM的计算过程
(1)忘记信息

(2)新记忆信息
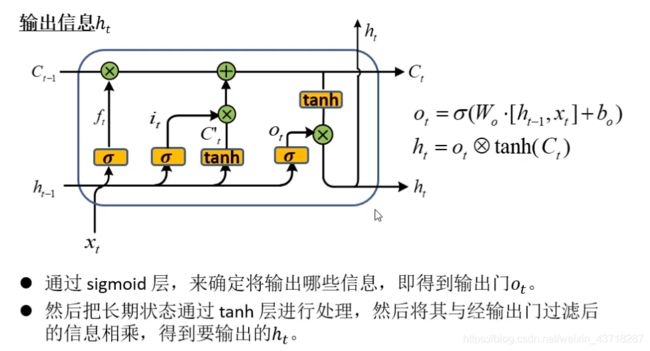
 (3)输出信息h(t)
(3)输出信息h(t)
双向RNN(Bidirectional RNNS)
双向传播,然后将正向和反向按照某一维度进行拼接

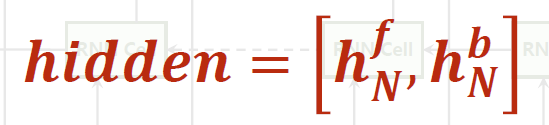
GRU
GRU是LSTM的一种变体,运算速度更快,与LSTM的使用场合分情况而定。

Example of GRU
模型

过程
Preparing Data
编码
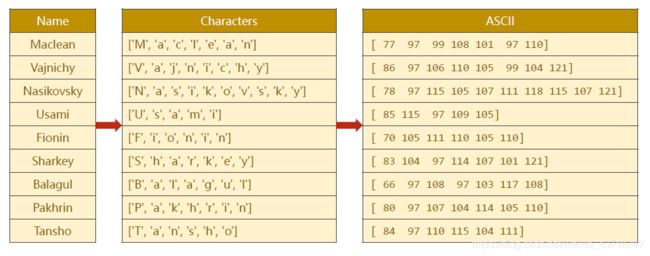 Padding
Padding

创建分类词典
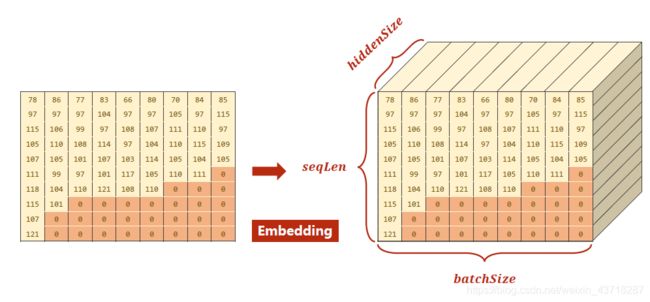
 Embedding
Embedding
(图片有误,填充0后Embedding得到的数值一样)

排序

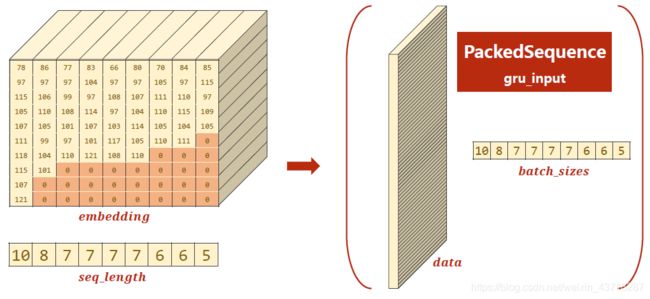
 横向取值,表示批量取每个样本的x1,即为名字的第一个字符
横向取值,表示批量取每个样本的x1,即为名字的第一个字符
整体代码如下:
import csv
import gzip
import torch
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
import time
import math
#parameters
HIDDEN_SIZE=100
BATCH_SIZE=256
N_LAYER=2
N_EPOCHS=20
N_CHARS=128
USE_GPU=False
class NameDataset(Dataset):
def __init__(self,is_train_set=True):
filename='names_train.csv.gz' if is_train_set else 'names_test.csv.gz'
with gzip.open(filename,'rt') as f:
reader=csv.reader(f)
rows=list(reader)
self.names=[row[0] for row in rows]
self.len=len(self.names)
self.countries=[row[1] for row in rows]
self.country_list=list(sorted(set(self.countries))) #制作国家名称词典
self.country_dict=self.getCountryDict()
self.country_num=len(self.country_list)
def __getitem__(self, index):
return self.names[index],self.country_dict[self.countries[index]]
def __len__(self):
return self.len
def getCountryDict(self):
country_dict=dict()
for idx,country_name in enumerate(self.country_list,0):
country_dict[country_name]=idx
return country_dict
def idx2country(self,index):
return self.country_list[index]
def getCountriesNum(self):
return self.country_num
trainset=NameDataset(is_train_set=True)
trainloader=DataLoader(trainset,batch_size=BATCH_SIZE,shuffle=True)
testset=NameDataset(is_train_set=False)
testloader=DataLoader(testset,shuffle=False,batch_size=BATCH_SIZE)
N_COUNTRY=trainset.getCountriesNum()
#使用GPU进行计算
def create_tensor(tensor):
if USE_GPU:
device=torch.device("cuda:0")
tensor=tensor.to(device)
return tensor
class RNNClassifier(torch.nn.Module):
def __init__(self,input_size,hidden_size,output_size,n_layers=1,bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size=hidden_size
self.n_layers=n_layers
self.n_directions=2 if bidirectional else 1 #if 为真输出前面表达式的内容,否则输出else后的内容
self.embedding =torch.nn.Embedding(input_size,hidden_size)
self.gru=torch.nn.GRU(hidden_size,hidden_size,n_layers,
bidirectional=bidirectional)
self.fc=torch.nn.Linear(hidden_size*self.n_directions,output_size)
def _init_hidden(self,batch_size):
hidden=torch.zeros(self.n_layers*self.n_directions,
batch_size,self.hidden_size)
return create_tensor(hidden)
def forward(self,input,seq_lengths):
#input shape: BxS -> SxB
input=input.t() #转置
batch_size=input.size(1)
hidden=self._init_hidden(batch_size)
embedding=self.embedding(input)
#pack them up
#It returns a PackedSequence object
gru_input=torch.nn.utils.rnn.pack_padded_sequence(embedding,seq_lengths)
output,hidden=self.gru(gru_input,hidden)
# print(hidden)
if self.n_directions==2:
hidden_cat=torch.cat([hidden[-1],hidden[-2]],dim=1)
else:
hidden_cat=hidden[-1]
fc_output=self.fc(hidden_cat)
return fc_output
def name2list(name):
arr=[ord(c) for c in name]
return arr,len(arr)
def make_tensors(names,countries):
sequences_and_lengths=[name2list(name) for name in names]
#print(sequences_and_lengths)
name_sequences=[s1[0] for s1 in sequences_and_lengths]
seq_lengths=torch.LongTensor([s1[1] for s1 in sequences_and_lengths])
countries=countries.long()
#make tensor of name, BatchSize x Seqlen
#全部填充0然后覆盖
seq_tensor=torch.zeros(len(name_sequences),seq_lengths.max()).long()
for idx,(seq,seq_len) in enumerate(zip(name_sequences,seq_lengths),0):
seq_tensor[idx,:seq_len]=torch.LongTensor(seq)
#sort by length to use pack_padded_sequence
seq_lengths,perm_idx=seq_lengths.sort(dim=0,descending=True)
seq_tensor=seq_tensor[perm_idx]
countries=countries[perm_idx]
return create_tensor(seq_tensor),\
create_tensor(seq_lengths),\
create_tensor(countries)
def trainModel():
def time_since(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
total_loss = 0
for i, (names, countries) in enumerate(trainloader, 1):
inputs, seq_lengths, target = make_tensors(names,countries)
output=classifier(inputs,seq_lengths)
loss=criterion(output,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss +=loss.item()
if i%10==0:
print(f"[{time_since(start)} Epoch {epoch} ",end="")
print(f"[{i*len(inputs)}/{len(trainset)}] ",end='')
print(f'loss={total_loss/(i*len(inputs))}')
return total_loss
def testModel():
correct=0
total=len(testset)
print("evaluating trained model ...")
with torch.no_grad():
for i,(names,countries) in enumerate(testloader):
inputs,seq_lengths,target=make_tensors(names,countries)
output=classifier(inputs,seq_lengths)
pred=output.max(dim=1,keepdim=True)[1]
correct +=pred.eq(target.view_as(pred)).sum().item()
percent='%.2f'% (100*correct/total)
print(f'Test set: Accuracy {correct}/{total} {percent}%')
return correct/total
def show(list):
epoch=np.arange(1,len(list)+1,1)
list=np.array(list)
plt.plot(epoch,list)
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.grid()
plt.show()
if __name__ == '__main__':
classifier=RNNClassifier(N_CHARS,HIDDEN_SIZE,N_COUNTRY,N_LAYER)
if USE_GPU:
device=torch.device("cuda:0")
classifier.to(device)
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(classifier.parameters(),lr=0.001)
start=time.time()
print("Training for %d epcohs>>>" %N_EPOCHS)
acc_list=[]
for epoch in range(1,N_EPOCHS+1):
#Training Cycle
trainModel()
acc=testModel()
acc_list.append(acc)
show(acc_list)
Result

Preference
B站pytorch深度学习实践