李宏毅2020机器学习深度学习(4) RNN循环神经网络 笔记+作业
目录
- 1. 背景知识
-
- 1.1 RNN(循环神经网络)结构介绍
- 1.2 LSTM(Long Short-term Memory)
- 1.3 LSTM如何训练?
- 2. 作业描述
- 3. 数据预处理
-
- 3.1 数据描述
- 3.2 词向量化
- 3.3 半监督学习(Semi-Supervised Learning)
- 3.4 数据格式
- 4. 完整代码
-
- 4.1 word2vec
- 4.2 utils.py
- 4.3 w2v.py
- 4.4 preprocess.py
- 4.5 data.py
- 4.6 model.py
- 4.7 train.py
- 4.8 test_data.py
- 4.9 main.py
- 5.预测结果
1. 背景知识
1.1 RNN(循环神经网络)结构介绍
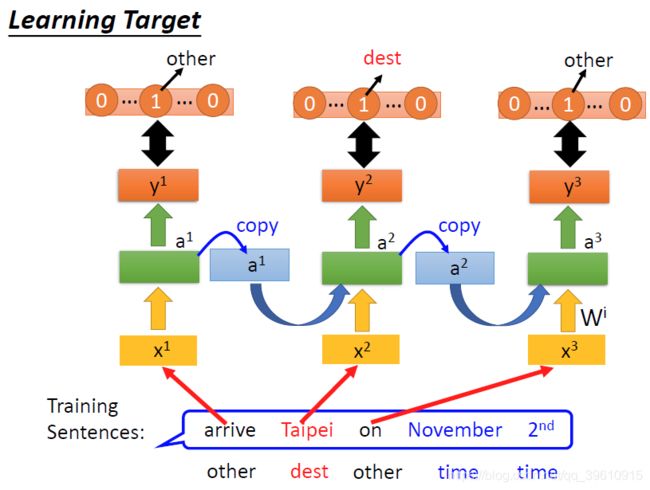
先从一个例子开始,某订票系统希望“智能地”从一句话中提取出目的地和时间,实现对输入文本序列的一个归类。

将每一个输入的单词用向量表示,可以使用 One-of-N Encoding

增加一个维度“others”,用来存储字典中没有的词汇。

我们希望神经网络能输出“Taipei”属于dest和time of departure的概率。
但普通的神经网络不能完成这个问题,“Taipei”前的动词不同,语义就会大大的不同。

所以我们需要神经网络能记住一些东西,比如“arrive”和“leave”输出的结果。

如上图,是同一个network在3个时间点的表现,上一个时刻输出的结果被储存下来也作用于下一个时刻的计算。

这样输入“Taipei”时,就能因为上文不同,而输出不同的结果。
RNN的层数加深时,就像这样。

几种RNN如下:
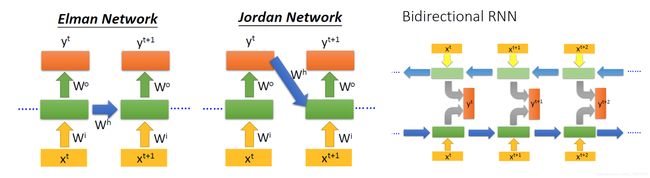
1.2 LSTM(Long Short-term Memory)
接下来进入重头戏,长短期记忆网络。
其结构如下:
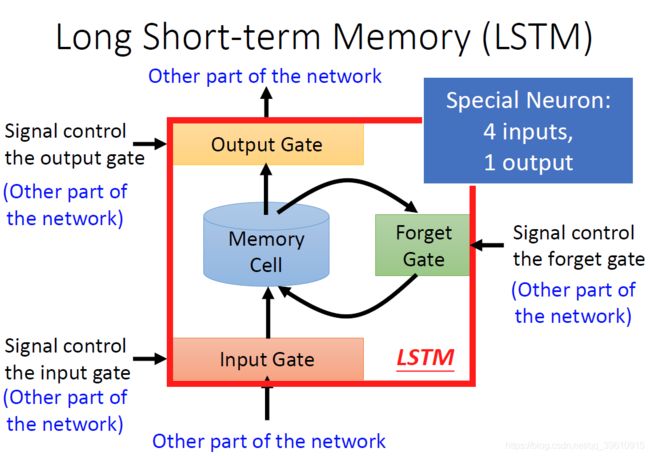
一个LSTM的神经元有4个Input和1个output。
除了原始输入,Input Gate控制输入是否读入,Output Gate控制是否输出,Forget Gate控制是否读入记忆存储中的数值。

每个LSTM神经元需要输入的参数时普通神经元的4倍。
假设我们每层有n个LSTM神经元
c t − 1 c^{t-1} ct−1为存储了每个LSTM神经元存储状态的向量。
将向量 x t x^t xt (n维)进行线性变换,得到四个向量 z f z^f zf, z i z^i zi, z z z, z o z^o zo,都是n维向量。
这四个向量合起来,就能操作这n个LSTM神经元的运作。
第i个神经元的对应输入为这些向量的第i个分量。

下面解释一下如何通过矩阵运算一次得到每个LSTM神经元的记忆和输出。
送入每个神经元的门控信号只是一个标量。
如下图所示,左图中的输入输出均为n为向量,蓝色x代表element-wise 相乘(同位元素相乘)
(图里有个小错,z没有经过函数g)

第一个LSTM神经元输出的 c t c^t ct为所有memory中的值
整个网络的在相邻时刻的数据流向如下图,一定要注意,这是一个时序图!
每一个time step的前进都更新了所有的LSTM神经元!

上面讲的是一个简化的版本!
t + 1 t+1 t+1时间点的输入,不止有输入 x t + 1 x^{t+1} xt+1
还有上一个时间点的输出 y t y^t yt和记忆存储 c t c^t ct(peephole)
共同构成t+1时刻的输入。
把这三个向量并在一起,乘上不同的线性变换矩阵,得到门控信号。

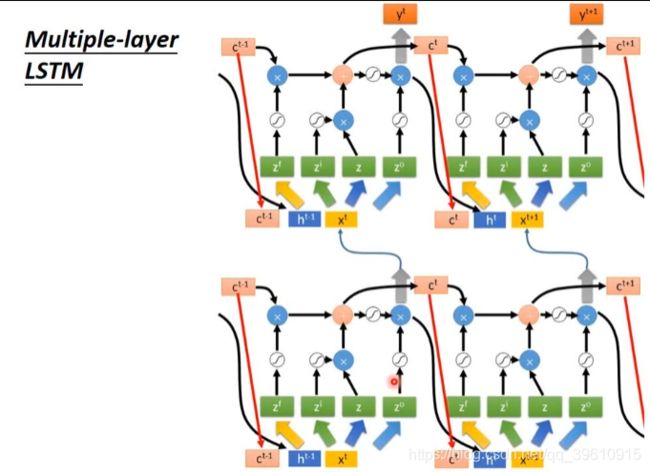
多层LSTM结构的示意图
输入下一层的 y t y^t yt = h t h^t ht
1.3 LSTM如何训练?
对比输入输出向量的相似度。
求权重的偏微分使用BPTT算法。(课中并未讲解)

RNN并不容易训练,梯度下降不容易顺利进行。
解决方法:clipping(当梯度>某个阈值时就取这个阈值)

为什么RNN的loss会出现这样“陡峭”的特性呢?

LSTM中的forget gate可以解决RNN中梯度消失的问题。

后续课程内容为RNN应用的各种情形,限于能力,暂时不进行讨论。
先专注于作业中RNN的应用。
2. 作业描述
进行文本的二元情感分类,0表示负面情感,1表示正面情感。

将文本序列输入LSTM进行训练,预测结果在0-1之间。
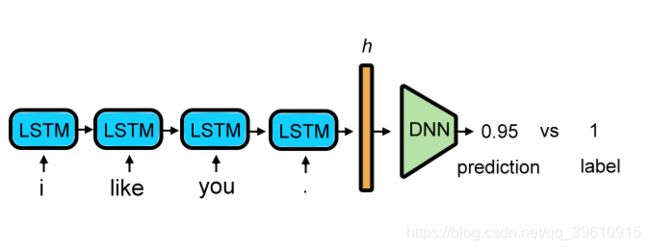
3. 数据预处理
3.1 数据描述
训练数据与测试数据为Twitter上采集的推文。

training_label.txt:有label的training data(句子被标记为0 or 1)
training_nolabel.txt:沒有label的training data(只有句子),用來做semi-supervise learning
testing_data.txt:你要判断testing data中的的句子(的情感倾向)是0 or 1
3.2 词向量化
先建立字典,字典内含有每一个单词对应的index。
举例来说,“I have a pen.” ->[1,2,3,4],而"I have an apple." -> [1,2,5,6]。
利用Word Embedding来代表每一个单词。
并借由RNN model得到一个代表该句的vector。
或者可以直接用bag of words(BOW)的方法获得该句的vector。
Word Embedding
这里老师专门讲了一节课,所以单记了一篇Word Embedding的笔记

one-hot encoding 是一种被广泛使用的编码方法,但缺点是维数过高,且占用存储空空间,存储的数据较为稀疏。

Bag of Words(BOW)
BOW的概念就是将句子里的文字变成一个袋子装着这些词的方式表现,不考虑语法以及词的顺序。
给定一个包含两个文本的语料库,文本内容分别如下:
1)John likes to watch movies, Mary likes too.
2)John also likes to watch football games.
通过这两个文本构建如下表的词典:

通过词典,就可以将所有的词向量化了。以one-hot向量表示,每个词的向量长度都是词典的大小,然后向量中元素全是0, 除了index位置的元素是1,如watch = [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]。
完成对所有词的向量化之后,就可以得出两个文本的向量化结果,每个文本的向量长度都是词典的大小,向量中的每个位置的元素代表词典中该位置的词在文本中出现的次数。以文本1为例,John出现了1次,likes出现了2次,football出现了0次等等,结果如下:文本1 = [1, 2, 1, 1, 1, 0, 0, 0, 1, 1]。
Word Embedding
使用CBOW或者skip-gram
推荐阅读:word2vec 中的数学原理详解

3.3 半监督学习(Semi-Supervised Learning)
利用未标签的数据
把 train 好的 model 对 unlabel data 做预测,并将这些预测后的值转成这些unlabel data 的 label,并加入这些新的 data 做 training。你可以调整不同的 threshold,或是多次取样来得到比较有信心的 data。
例如设定 pos_threshold = 0.8,只有 prediction > 0.8 的 data 会被标上 1。
3.4 数据格式
已标记数据格式如图所示,1为无恶意,0为有恶意。(这里觉得标签打得很随意,数据不理想)

4. 完整代码
完整代码已经上传至github仓库
所需训练数据已上传至百度网盘,提取码:rbwi
4.1 word2vec
为了能理解整个程序,必须先对word2vec包进行一些说明。
参考文档:https://radimrehurek.com/gensim/models/word2vec.html
举一个最简单的例子
from gensim.test.utils import common_texts
from gensim.models import Word2Vec
model = Word2Vec(sentences=common_texts, vector_size=100, window=5, min_count=1, workers=4)
model.save("word2vec.model")
训练语句sentences必须是可迭代的
训练好的单词向量存储在一个 KeyedVectors 实例中,作为 model.wv
model = Word2Vec.load("word2vec.model")
vector = model.wv['computer'] # get numpy vector of a word
如果你已经完成了模型的训练(也就是说不需要更新,只需要查询) ,你可以切换到 KeyedVectors 实例:
word_vectors = model.wv
del model
4.2 utils.py
此程序存放了一些常用的函数,包括从txt文件中读取数据和标签等
import torch
import numpy as np
import pandas as pd
import torch.optim as optim
import torch.nn.functional as F
def load_training_data(path = 'data/training_label.txt'):
# 读取训练数据
# 已打标签数据'training_label.txt'需要读取标签,未打标签数据'training_nolabel.txt'则不需要读取标签
if 'training_label' in path:
with open(path, 'r', encoding='utf-8') as f:
lines = f.readlines() # Return a list
lines = [line.strip('\n').split(' ') for line in lines]
x = [line[2:] for line in lines] # list中的元素是每句话根据空格符分词的结果
y = [line[0] for line in lines] # list中的元素是每句话的标签,0 or 1
return x,y
else:
with open(path, 'r', encoding='utf-8') as f:
lines = f.readlines()
x = [line.strip('\n').split(' ') for line in lines]
return x
def load_testing_data(path = 'data/testing_data.txt'):
# 读取测试数据
# 测试数据格式为 id,句子内容
with open(path, 'r', encoding='utf-8') as f:
lines = f.readlines()
X = ["".join(line.strip('\n').split(',')[1:]).strip() for line in lines[1:]] # 读取的时候去掉第一行
X = [sen.split(' ') for sen in X] # 分词
return X
def evaluation(outputs, labels):
#outputs => probability (float)
#labels => labels
outputs[outputs>=0.5] = 1 # >0.5为无恶意
outputs[outputs<0.5] = 0 # <0.5为无恶意
correct = torch.sum(torch.eq(outputs, labels)).item()
return correct
4.3 w2v.py
这个程序使用skip-gram模型,得到词向量化矩阵
# 这个程序用来进行word embedding
import os
import sys
from gensim.models import word2vec
sys.path.append(os.pardir) #返回当前文件的父目录
from utils import load_training_data, load_testing_data
path_prefix = './'
def train_word2vec(x):
# 训练词向量化的word embedding
# size参数主要是用来设置神经网络的层数
# workers参数用于设置并发训练时候的线程数,不过仅当Cython安装的情况下才会起作用
# min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
# 在不同大小的语料集中,我们对于基准词频的需求也是不一样的。譬如在较大的语料集中,我们希望忽略那些只出现过一两次的单词
# window:即词向量上下文最大距离,window越大,则和某一词较远的词也会产生上下文关系。默认值为5,在实际使用中,可以根据实际的需求来动态调整这个window的大小。
# iter:随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
# sg:即我们的word2vec两个模型的选择了。如果是0, 则是CBOW模型;是1则是Skip-Gram模型;默认是0即CBOW模型。
model = word2vec.Word2Vec(x, size=250, window=5, min_count=5, workers=12, iter=10, sg=1)
return model
if __name__ == '__main__':
print("载入训练数据......")
train_x,y = load_training_data('data/training_label.txt')
train_x_no_label = load_training_data('data/training_nolabel.txt')
print("载入测试数据......")
test_x = load_testing_data('data/testing_data.txt')
print("正在进行词向量化")
model = train_word2vec(train_x + train_x_no_label + test_x)
print("保存模型......")
model.save(os.path.join(path_prefix, 'model/w2v_all.model'))
因为我们把size设为250,则训练出来的词向量就是250维的。

4.4 preprocess.py
此程序用于数据的预处理,根据w2v.py得到词向量结果,将句子向量化。
实际模型运行的时候,不是把所有词变成embedding存在文件里,然后模型读取文件,那样运行效率太低。
此程序会根据4.3中训练好的模型,组装出一个{ index:word},我们只需用每个词在embedding矩阵中的index,就能表示一个完整的句子,等具体要送入LSTM网络中训练时,再根据index取出对应词的embedding(通常维数很高)。这个过程等价于根据词在词典中的下标(one hot里1的下标)在embedding矩阵(V行E列)里查出对应行存的embedding向量,这个过程即look up。
import torch
from torch import nn as nn
from gensim.models import Word2Vec
class Preprocess():
def __init__(self, sentences, sen_len, w2v_path = "./model/w2v.model"):
self.w2v_path = w2v_path # w2v 模型存放路径
self.sentences = sentences # 训练文本,可能是一个list
self.sen_len = sen_len # 句子长度
self.idx2word = [] # 根据idx存放word的一个list
self.word2idx = {} # 存放了{word:index}的dict
self.embedding_matrix = [] # 词嵌入矩阵
def get_w2v_model(self):
# 读取之前训练好的word to vec模型
self.embedding = Word2Vec.load(self.w2v_path)
self.embedding_dim = self.embedding.vector_size
def add_embedding(self, word):
# 把word加进embedding,并赋予其一个随机生成的表示向量
# word只会是或
#(1):对于短句子用填充。
#(2): EOS代表句子的结尾。
#(3):对于一些不常见的词汇,直接用UNK替换掉。
vector = torch.empty(1, self.embedding_dim)
torch.nn.init.uniform_(vector) # 参数初始化,选择均匀分布,默认从0到1
self.word2idx[word] = len(self.word2idx) # word的index为现有词数
self.idx2word.append(word) # 将word加入idx2word的末尾
self.embedding_matrix = torch.cat([self.embedding_matrix, vector])
def make_embedding(self, load=True):
print("正在组装词向量化矩阵......")
# 取得训练好的 Word2vec word embedding
if load:
print("加载 word to vec 模型......")
self.get_w2v_model()
else:
raise NotImplementedError
# 制作一个 word2idx 的 dictionnary
# 制作一个 idx2word 的 list
# 制作一个 word2vector 的 list
#
for i, word in enumerate(self.embedding.wv.vocab): # model.wv.vocab:可以直接调用生成的词向量
print('get words #{}'.format(i+1), end= '\r')
#e.g. self.word2index['a'] = 1
#e.g. self.index2word[1] = 'a'
#e.g. self.vectors[1] = 'a'对应的vector
self.word2idx[word] = len(self.word2idx)
self.idx2word.append(word)
self.embedding_matrix.append(self.embedding[word])
print('')
self.embedding_matrix = torch.tensor(self.embedding_matrix)
# 将和加入embedding中
self.add_embedding("" )
self.add_embedding("" )
print("total words: {}".format(len(self.embedding_matrix)))
return self.embedding_matrix
def pad_sequence(self, sentence):
# 将每个句子变成一样的长度
if len(sentence) > self.sen_len:
sentence = sentence[:self.sen_len]
else:
pad_len = self.sen_len - len(sentence)
for _ in range(pad_len):
sentence.append(self.word2idx["" ])
assert len(sentence) == self.sen_len
return sentence
def sentence_word2idx(self):
# 把句子里面的词转成相应的index
sentence_list = []
for i, sen in enumerate(self.sentences):
print('sentence count #{}'.format(i+1), end='\r')
sentence_idx = []
for word in sen:
if (word in self.word2idx.keys()): #keys() 函数以列表返回一个字典所有的键
sentence_idx.append(self.word2idx[word])
else:
sentence_idx.append(self.word2idx["" ])
# 将每个句子变成一样的长度
sentence_idx = self.pad_sequence(sentence_idx)
sentence_list.append(sentence_idx)
return torch.LongTensor(sentence_list) # torch.Tensor默认是torch.FloatTensor是32位浮点类型数据,torch.LongTensor是64位整型
def labels_to_tensor(self, y):
# 将labels转成tensor
y = [int(label) for label in y]
return torch.LongTensor(y)
4.5 data.py
重写dataset所需要的’init’, ‘getitem’, 'len’方法,好让dataloader使用。
import torch
from torch.utils import data
class TwitterDataset(data.Dataset):
"""
Expected data shape like:(data_num, data_len)
Data can be a list of numpy array or a list of lists
input data shape : (data_num, seq_len, feature_dim)
__len__ will return the number of data
"""
def __init__(self, X, y):
self.data = X
self.label = y
def __getitem__(self, idx):
if self.label is None: return self.data[idx]
return self.data[idx], self.label[idx]
def __len__(self):
return len(self.data)
4.6 model.py
# 此程序是用于训练情感分类的lstm模型
import torch
from torch import nn
class LSTM_Net(nn.Module):
def __init__(self, embedding, embedding_dim, hidden_dim, num_layers, dropout = 0.5, fix_embedding = True):
super(LSTM_Net, self).__init__()
# 设计 embedding layer
# torch.nn.Embedding:A simple lookup table that stores embeddings of a fixed dictionary and size.
# num_embeddings :字典中词的个数
# embedding_dim:embedding的维度
self.embedding = torch.nn.Embedding(embedding.size(0),embedding.size(1)) # 单词数量*词向量维数
# Embedding.weight (Tensor) – the learnable weights of the module of shape
# embedding即为之前word2vec训练出来的词向量矩阵
self.embedding.weight = torch.nn.Parameter(embedding) # nn.Parameter会自动被认为是module的可训练参数,即加入到parameter()这个迭代器中去
# 是否将embedding固定
# 如果fix_embedding为False,在训练过程中,embedding也会跟着被训练
self.embedding.weight.requires_grad = False if fix_embedding else True
self.embedding_dim = embedding.size(1)
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.dropout = dropout
self.lstm = nn.LSTM(input_size = embedding_dim, hidden_size = hidden_dim, num_layers = num_layers, batch_first=True)
# nn.LSTM部分参数说明
# input_size – The number of expected features in the input x
# hidden_size – The number of features in the hidden state h
# num_layers – Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two LSTMs together to form a stacked LSTM, with the second LSTM taking in outputs of the first LSTM and computing the final results. Default: 1
# batch_first – If True, then the input and output tensors are provided as (batch, seq, feature). Default: False
# dropout – If non-zero, introduces a Dropout layer on the outputs of each LSTM layer except the last layer, with dropout probability equal to dropout. Default: 0
self.classifier = nn.Sequential(nn.Dropout(dropout),
nn.Linear(hidden_dim, 1),
nn.Sigmoid())
def forward(self, inputs):
# 这一步根据输入的数据的idx,完成句子的embedding操作
inputs = self.embedding(inputs)
# inputs的dimension由(batch, seq_len)变为(batch, seq_len, input_size) 128*30*250
x, _ =self.lstm(inputs, None)
# x的dimension (batch, seq_len, num_directions * hidden_size) 128*30*300
# hidden_size:The number of features in the hidden state h
# 取LSTM最后一层的hidden state
x = x[:, -1, :] # 128*300, 注意这里会直接降一维
x = self.classifier(x) # 128*1
return x
4.7 train.py
# 这个程序是用来训练模型的
import torch
from torch import nn
import torch.optim as optim
import torch.nn.functional as F
from utils import evaluation
def training(batch_size, n_epoch, lr, model_dir, train, valid, model, device):
total = sum(p.numel() for p in model.parameters()) # .numel()返回数组中元素的个数
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
print('\nstart training, parameter total:{}, trainable:{}\n'.format(
total, trainable))
model.train() # 将model的模式设为train, 这样optimizer就可以更新model的参数
criterion = nn.BCELoss() # 因为是一个二值分类问题,所以使用binary cross entropy作为损失函数
t_batch = len(train) # 即有多少个batch
v_batch = len(valid)
optimizer = optim.Adam(model.parameters(), lr=lr) # 将模型的参数给优化器,设置合适的学习率
total_loss, total_acc, best_acc = 0, 0, 0
# 每一个epoch都要做training和validation
for epoch in range(n_epoch):
total_loss, total_acc = 0, 0
# 开始训练
# 每次训练一个batch的数据
for i, (inputs, labels) in enumerate(train):
# device为"cuda",将inputs转为torch.cuda.LongTensor
# 输入维度为128*30 每行为[word1的index, word2的index, ... , word30的index]
inputs = inputs.to(device, dtype=torch.long)
# device为"cuda",将labels转为torch.cuda.FloatTensor(因为要带入损失函数中计算,要为float)
# labels为128维的tensor
labels = labels.to(device, dtype=torch.float)
# 由于loss.backward()的gradient会累加,每次训练完一个batch要归零
optimizer.zero_grad()
outputs = model(inputs) # 將input送入模型,输出维度为128*1
outputs = outputs.squeeze() # 去掉维数为1的的维度,好让output可以输入criterion()
loss = criterion(outputs, labels) # 計算此時模型的training loss
loss.backward() # 算loss的gradient
optimizer.step() # 更新训练模型的参数
correct = evaluation(outputs, labels) # 计算模型此时的training accuracy
total_acc += (correct / batch_size)
total_loss += loss.item()
print('[ Epoch{}: {}/{} ] loss:{:.3f} acc:{:.3f} '.format(epoch+1, i+1, t_batch, loss.item(), correct*100/batch_size), end='\r')
print('\nTrain | Loss:{:.5f} Acc: {:.3f}'.format(total_loss/t_batch, total_acc/t_batch*100))
# 这段做validation,不更新参数
model.eval() # 将model的模式设为eval, 这样model的参数就会固定住
with torch.no_grad():
total_loss, total_acc = 0, 0
for i, (inputs, labels) in enumerate(valid):
inputs = inputs.to(device, dtype=torch.long)
labels = labels.to(device, dtype=torch.float)
outputs = model(inputs)
outputs = outputs.squeeze()
loss = criterion(outputs, labels)
correct = evaluation(outputs, labels)
total_acc += (correct / batch_size)
total_loss += loss.item()
print("Valid | Loss:{:.5f} Acc: {:.3f} ".format(total_loss/v_batch, total_acc/v_batch*100))
if total_acc > best_acc:
# 如果validation的结果优于之前所有的结果,就把当下的模型存下来用于之后的预测
# best_acc只和验证阶段的计算有关,最终保存下来的模型是在验证阶段表现最好的
best_acc = total_acc
#torch.save(model, "{}/val_acc_{:.3f}.model".format(model_dir,total_acc/v_batch*100))
torch.save(model, "{}/ckpt.model".format(model_dir))
print('saving model with acc {:.3f}'.format(total_acc/v_batch*100))
print('-----------------------结束了一个epoch的训练------------------------')
model.train() # 将model的模式设为train, 这样optimizer就可以更新model的参数(因为刚才转成eval模式)
4.8 test_data.py
# 此程序用来对testing_data.txt做预测
import torch
from torch import nn
import torch.optim as optim
import torch.nn.functional as F
def testing(batch_size, test_loader, model, device):
model.eval()
ret_outputs = []
with torch.no_grad():
for i, inputs in enumerate(test_loader):
inputs = inputs.to(device, dtype = torch.long)
outputs = model(inputs)
outputs = outputs.squeeze()
outputs[outputs >= 0.5] = 1 # 大于等于0.5为正面
outputs[outputs < 0.5] = 0 # 小于0.5为负面
ret_outputs += outputs.int().tolist()
return ret_outputs
4.9 main.py
import warnings
warnings.filterwarnings('ignore')
path_prefix = './'
# 载入所需的包
import os
import sys
import torch
import argparse
import numpy as np
import pandas as pd
from torch import nn as nn
from gensim.models import word2vec
from sklearn.model_selection import train_test_split
# 设定工作目录
os.chdir(r'') #修改成你自己的工作路径
sys.path.append('..')
# 读取自己写的python程序
from utils import load_training_data, load_testing_data, evaluation
from preprocess import Preprocess
from model import LSTM_Net
from data import TwitterDataset
from train import training
from test_data import testing
# 如果有使用gpu的环境则device设为"cuda",没有就设为"cpu"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 设定各个data的路径
train_with_label = os.path.join(path_prefix, 'data/training_label.txt')
train_no_label = os.path.join(path_prefix, 'data/training_nolabel.txt')
testing_data = os.path.join(path_prefix, 'data/testing_data.txt')
# 设定word to vec model的路径
w2v_path = os.path.join(path_prefix, 'model/w2v_all.model')
# 设定训练参数
sen_len = 30 #定义句子长度为30
fix_embedding = True # 训练时固定embedding
batch_size = 128
epoch = 5
lr = 0.001
model_dir = os.path.join(path_prefix, 'model/') #存放临时模型的目录
# 把'training_label.txt'和'training_nolabel.txt'读取
print("加载数据中......")
train_x, y = load_training_data(train_with_label)
train_x_no_label = load_training_data(train_no_label)
# 对input和labels做预处理
preprocess = Preprocess(train_x, sen_len, w2v_path=w2v_path) #创建一个处理类的实例
embedding = preprocess.make_embedding(load=True) # 组装词向量化矩阵
train_x = preprocess.sentence_word2idx() # 进行句子的向量化,返回一个[[],[],...],train_x[i][j]存的是第i个句子的第j个词的index
y = preprocess.labels_to_tensor(y)
# 创建一个model的对象
'''
LSTM_Net(
(embedding): Embedding(55779, 250)
(lstm): LSTM(250, 300, batch_first=True)
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=300, out_features=1, bias=True)
(2): Sigmoid()
)
)
'''
model = LSTM_Net(embedding, embedding_dim=250, hidden_dim=300, num_layers=1, dropout=0.5, fix_embedding=fix_embedding)
model = model.to(device)
# 将data分为training data和validation data
X_train, X_val = train_x[:190000], train_x[190000:]
y_train, y_val = y[:190000], y[190000:]
# 将data做成dataset供dataloader使用
train_dataset = TwitterDataset(X=X_train, y=y_train)
val_dataset = TwitterDataset(X=X_val, y=y_val)
# 将data 转成 batch of tensors
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0) # windows系统下不要用多线程,linux系统随意!
val_loader = torch.utils.data.DataLoader(dataset=val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=0)
# 开始训练
training(batch_size, epoch, lr, model_dir, train_loader, val_loader, model, device)
print("载入测试数据......")
test_x = load_testing_data(testing_data)
preprocess = Preprocess(test_x, sen_len, w2v_path=w2v_path)
embedding = preprocess.make_embedding(load=True)
test_x = preprocess.sentence_word2idx()
test_dataset = TwitterDataset(X=test_x, y=None)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = batch_size,
shuffle = False,
num_workers = 0)
print('\nload model ...')
model = torch.load(os.path.join(model_dir, 'ckpt.model'))
outputs = testing(batch_size, test_loader, model, device)
# 将测试集的预测结果写入csv
tmp = pd.DataFrame({"id":[str(i) for i in range(len(test_x))],"label":outputs})
print("保存预测结果至csv ...")
tmp.to_csv(os.path.join(path_prefix, 'predict.csv'), index=False)
print("结束预测")
5.预测结果
取10条测试结果举例,预测的效果不错
| ID | 英文句子 | 预测结果 |
|---|---|---|
| 0 | my dog ate our dinner . no , seriously … he ate it . | 负面 |
| 1 | omg last day sooon n of primary noooooo x im gona be swimming out of school wif the amount of tears am gona cry | 负面 |
| 2 | stupid boys … they ’ re so … stupid ! | 负面 |
| 3 | hi ! do u know if the nurburgring is open for tourists today ? we want to go , but there is an event today | 负面 |
| 4 | having lunch in the office , and thinking of how to resolve this discount form issue | 正面 |
| 5 | shopping was fun | 正面 |
| 6 | wondering where all the nice weather has gone . | 负面 |
| 7 | morning ! yeeessssssss new mimi in aug | 正面 |
| 8 | umm … maybe that ’ s how the british spell it ? | 正面 |
| 9 | yes it ’ s 3 : 50 am . yes i ’ m still awake . yes i can ’ t sleep . yes i ’ ll regret it tomorrow . haha i love you mr saturday | 正面 |