2022年Cs231n PPT笔记-训练CNN
目录
权重初始化
随机初始化
Xavier Initialization
Kaiming / MSRA Initialization
训练误差和测试误差
Early Stopping
Model Ensembles
正则化
正则化的通用思想
Dropout
解释
Inverted dropout
数据增强
其他方法
使用建议
选择超参数
步骤
Random Search 和 Grid Search
权重初始化
在神经网络的学习中,权重初始值非常重要。很多时候权重初始值的设定关系到神经网络的学习能否成功。
随机初始化
小网络可以,更深的网络会出问题
初始化值比较小
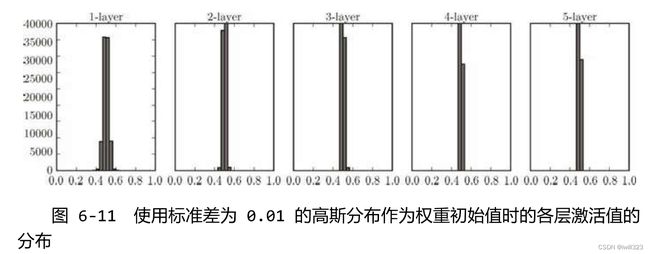
如果初始化数值比较小,比如W = 0.01* np.random.randn(D,H) ,会发生梯度消失。这里说的主要针对sigmoid或tanh函数,输⼊接近于零,反向传播过程中权重的local gradient(其中x这一项等于0)等于0,最后算出来的梯度成为0
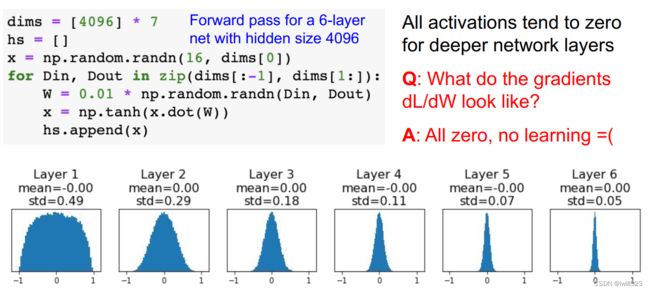
并且,激活值集中在 0.5 附近的分布,激活值的分布有所偏向,说明在表现力上会有很大问题。因为如果有多个神经元都输出几乎相同的值,那它们就没有存在的意义了。比如,如果 100 个神经元都输出几乎相同的值,那么也可以由 1 个神经元来表达基本相同的事情。因此,激活值在分布上有所偏向会出现“表现力受限”的问题。
各层的激活值的分布应当有适当的广度,因为通过在各层间传递多样性的数据,神经网络可以进行高效的学习。反过来,如果传递的是有所偏向的数据,就会出现梯度消失或者“表现力受限”的问题,导致学习可能无法顺利进行。
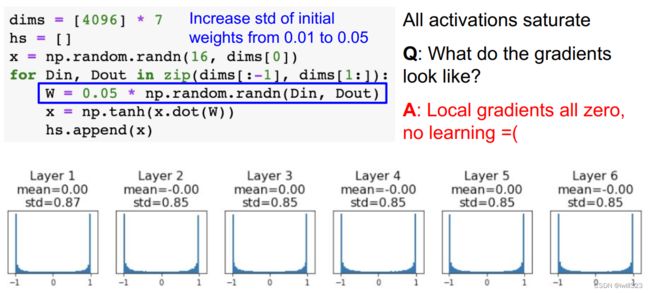
初始化数值比较大
如果初始化数值比较大,比如W = 0.05* np.random.randn(D,H) ,也会发生梯度消失:所有的激活值饱和,local gradient(tanh导数项等于0)等于0,最后算出来的梯度成为0
Xavier Initialization
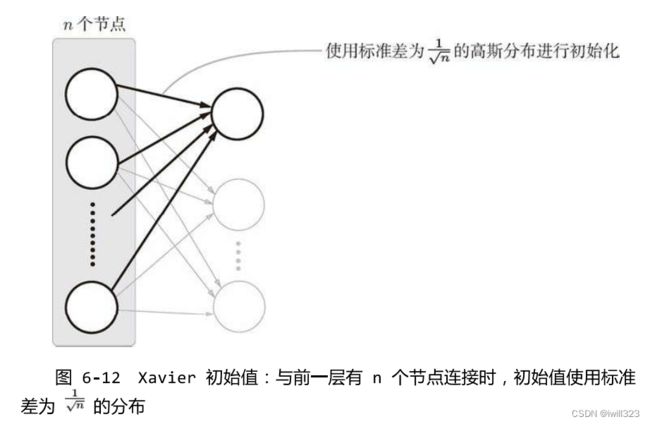
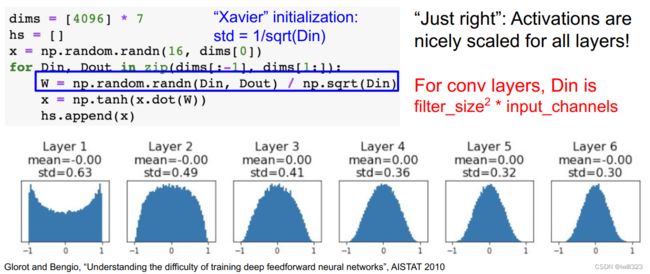
Xavier 的论文中,为了使各层的激活值呈现出具有相同广度的分布,推导了合适的权重尺度。随机初始化的neuron的output的方差随着input的个数增加而增加,于是要用input个数对权重矩阵进行缩放,使得输入输出的方差不变:如果前一层的节点数为 n,则初始值使用标准差为 1/sqrt(n) 的分布
推导过程
对于一个没有⾮线性的全连接层输出,权重wij都是从同⼀分布中独⽴抽取的。此外,假设该分布具有零均值和⽅差σ2。请注意,这并不意味着分布必须是⾼斯的,只是均值和⽅差需要存在。现在,让我们假设层xj的输⼊也具有零均值和⽅差γ2,并且它们独⽴于wij并且彼此独⽴。在这种情况下,我们可以按如下⽅式计算oi的平均值和⽅差: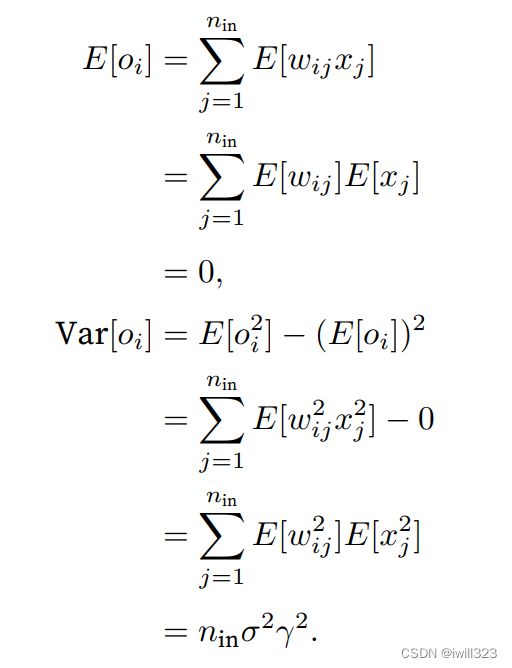
保持方差不变的一种方法是设置in2=1。考虑反向传播过程,我们面临着类似的问题,使用与前向传播相同的推断,可以看到,除非out2=1, 否则梯度的方差可能会增大,其中outnout是该层的输出的数量只需满⾜:
Xavier初始化从均值为零,方差 2=2/(in+out) 的高斯分布中采样权重。 我们也可以利用Xavier的直觉来选择从均匀分布中抽取权重时的方差。 注意均匀分布(−,)的方差为2/3。 将2/3代入到2的条件中,将得到初始化值域:
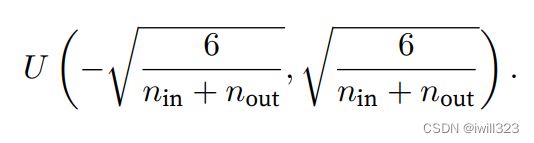
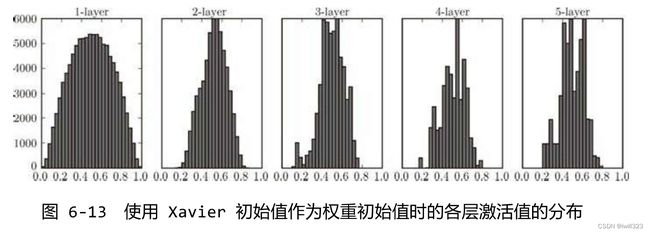
越是后面的层,图像变得越歪斜,但是呈现了比之前更有广度的分布。因为各层间传递的数据有适当的广度,所以 sigmoid 函数的表现力不受限制,有望进行高效的学习。
Kaiming / MSRA Initialization
上面是拿tanh函数举例,对于Relu函数,ReLU激活函数缓解了梯度消失问题,可以加速收敛。如果前一层的节点数为 n,则初始值使用标准差为 sqrt(2/n) 的分布 。(直观上)可以解释为,因为 ReLU 的负值区域的值为 0,为了使它更有广度,所以需要 2 倍的系数。
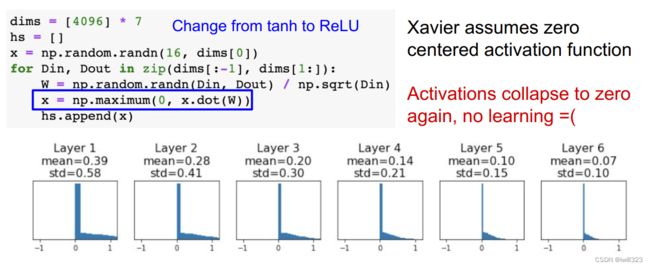
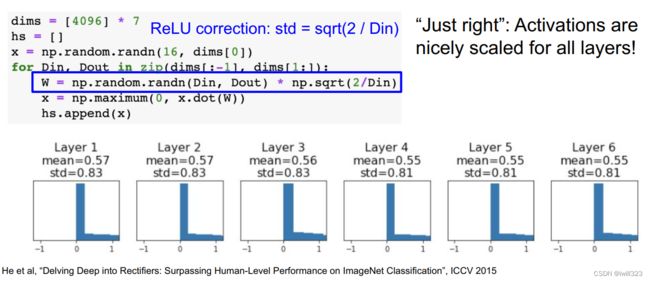
总结和比较
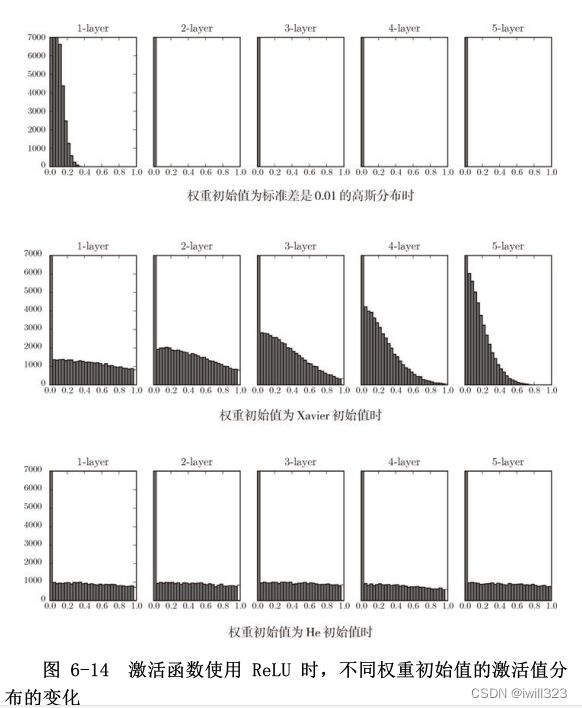
观察实验结果可知,当std = 0.01时,各层的激活值非常小 4。神经网络上传递的是非常小的值,说明逆向传播时权重的梯度也同样很小。这是很严重的问题,实际上学习基本上没有进展。
接下来是初始值为 Xavier 初始值时的结果。在这种情况下,随着层的加深,偏向一点点变大。实际上,层加深后,激活值的偏向变大,学习时会出现梯度消失的问题。而当初始值为 He 初始值时,各层中分布的广度相同。由于即便层加深,数据的广度也能保持不变,因此逆向传播时,也会传递合适的值。
总结一下,当激活函数使用 ReLU 时,权重初始值使用 He 初始值,当激活函数为 sigmoid或 tanh等 S 型曲线函数时,初始值使用 Xavier 初始值。这是目前的最佳实践。
更多资源
Understanding the difficulty of training deep feedforward neural networks
by Glorot and Bengio, 2010
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks by Saxe et al, 2013
Random walk initialization for training very deep feedforward networks by Sussillo and Abbott, 2014
Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification by He et
al., 2015
Data-dependent Initializations of Convolutional Neural Networks by Krähenbühl et al., 2015
All you need is a good init, Mishkin and Matas, 2015
Fixup Initialization: Residual Learning Without Normalization, Zhang et al, 2019
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, Frankle and Carbin, 2019
训练误差和测试误差
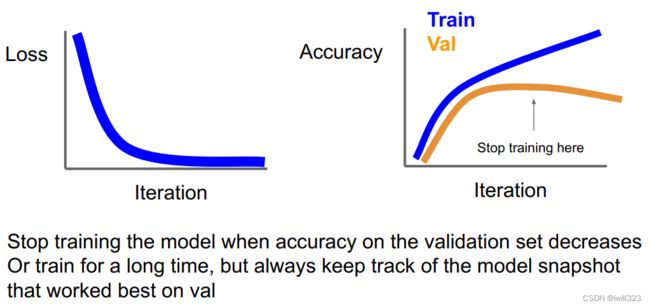
Early Stopping
训练得好不一定测试结果好,在过拟合前early stop
Model Ensembles
训练几个独立的模型,在测试的时候取这几个模型的预测均值(Take average of predicted probability distributions, then choose argmax),一般能带来2%的额外提升
具体可以参考官网CS231n Convolutional Neural Networks for Visual Recognition
正则化
正则化的通用思想
Training: Add random noise 在训练的过程中加入一些随机性,防止模型的过拟合
Testing: Marginalize over the noise 在测试的时候消除这个随机性,使得模型的泛化能力变强

常用方法
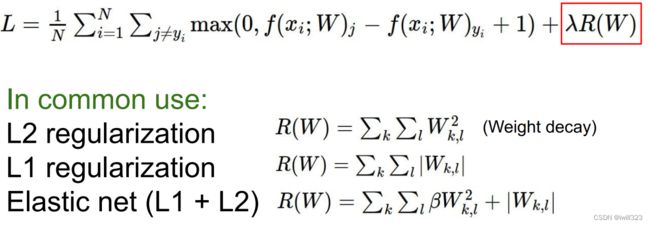
Dropout
正向传播过程中,随机让一些neuron变成0。“丢弃”的neuron比率是一个超参数,常用0.5。可以为每⼀层分别设置dropout概率:常⻅的技巧是在靠近输⼊层的地⽅设置较高的dropout概率

正向传播时传递了信号的神经元,反向传播时按原样传递信号;正向传播时没有传递信号的神经
元,反向传播时信号将停在那里
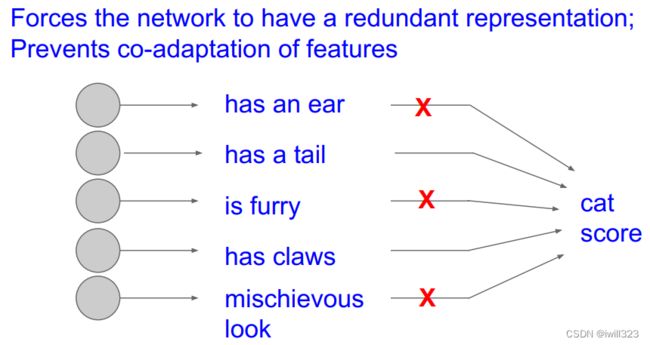
解释
1. 对于单个神经元,其工作是接收输入并产生一些有意义的输出。但是加入了 dropout 后,输入的特征都存在被随机清除的可能,即不会给任何一个输入特征设置太大的权重,所以该神经元任何一个输入特征影响被均匀化了,将噪音边缘化。 With dropout, your neurons thus become less sensitive to the activation of one other specific neuron, because that other neuron might be shut down at any time. 因此,通过传播过程,dropout 将产生和 L2 正则化相同的收缩权重的效果。
2. Dropout通过每次迭代训练时,随机选择不同的神经元,相当于每次都在不同的神经网络上进行训练,求其输出的平均值。也就是说,可以理解成,Dropout将集成学习的效果(模拟地)通过一个网络实现了。
 |
 |
Inverted dropout
在测试的时候为了结果稳定,不采用dropout,为了让正传播正常进行,测试时必须让每一个神经元的输出等于训练时的预期输出,于是测试时要在激活值上进行缩放(乘以训练时的dropout比率)


一般我们想让测试的时候简单一点,于是采用Inverted dropout,即在训练的时候缩放,在测试的时候不缩放
"""
Inverted Dropout: Recommended implementation example.
We drop and scale at train time and don't do anything at test time.
"""
p = 0.5 # probability of keeping a unit active. higher = less dropout
def train_step(X):
# forward pass for example 3-layer neural network
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = (np.random.rand(*H1.shape) < p) / p # first dropout mask. Notice /p!
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = (np.random.rand(*H2.shape) < p) / p # second dropout mask. Notice /p!
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# backward pass: compute gradients... (not shown)
# perform parameter update... (not shown)
def predict(X):
# ensembled forward pass
H1 = np.maximum(0, np.dot(W1, X) + b1) # no scaling necessary
H2 = np.maximum(0, np.dot(W2, H1) + b2)
out = np.dot(W3, H2) + b3pytorch版:
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃
if dropout == 0:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 1:
return X
mask = (torch.rand(X.shape) < dropout).float()
return mask * X / dropout
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)使用高级API:
net = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);数据增强
在对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,从而扩大了训练集的规模。 随机改变训练样本可以减少模型对某些属性的依赖,从而提高模型的泛化能力。例如,我们可以以不同的方式裁剪图像,使感兴趣的对象出现在不同的位置,减少模型对于对象出现位置的依赖。还可以调整亮度、颜色等因素来降低模型对颜色的敏感度。
翻转和裁剪:transforms.RandomHorizontalFlip、transforms.RandomVerticalFlip、RandomResizedCrop
改变颜色:transforms.ColorJitter


其他方法
| DropConnect
|
 |
| Fractional Max Pooling Graham, “Fractional Max Pooling”, arXiv 2014 |
 |
| Stochastic Depth Testing: Use all the layer Huang et al, “Deep Networks with Stochastic Depth”, ECCV 2016 |
 |
| Cutout DeVries and Taylor, “Improved Regularization of |
 |
| Mixup Zhang et al, “mixup: Beyond Empirical Risk Minimization”, ICLR 2018 |
 |
使用建议
- Consider dropout for large fully-connected layers
- Batch normalization and data augmentation almost always a good idea
- Try cutout and mixup especially for small classification datasets
选择超参数
进行超参数的最优化时,逐渐缩小超参数的“好值”的存在范围非常重要。所谓逐渐缩小范围,是指一开始先大致设定一个范围,从这个范围中随机选出一个超参数(采样),用这个采样到的值进行识别精度的评估;然后,多次重复该操作,观察识别精度的结果,根据这个结果缩小超参数的“好值”的范围。通过重复这一操作,就可以逐渐确定超参数的合适范围
在超参数的最优化中,要注意的是深度学习需要很长时间(比如,几天或几周)。因此,在超参数的搜索中,需要尽早放弃那些不符合逻辑的超参数。于是,在超参数的最优化中,减少学习的
epoch,缩短一次评估所需的时间是一个不错的办法。
步骤
第一步:检查初始loss
Turn off weight decay, sanity check loss at initialization e.g. log(C) for softmax with C classes
注意,启动正则化后,loss将会上升
第二步:对一小部分样本进行过拟合
关闭正则化,使用最普通的SGD优化
Try to train to 100% training accuracy on a small sample of training data (~5-10 minibatches); fiddle with architecture, learning rate, weight initialization
Loss not going down? LR too low, bad initialization
Loss explodes to Inf or NaN? LR too high, bad initialization
第三步:找到让loss下降的学习率
如果损失基本不变,原因通常是设置的学习率太低了;如果损失是NaN,往往意味着学习率太高了
Use the architecture from the previous step, use all training data, turn on small weight decay, find a learning rate that makes the loss drop significantly within ~100 iterations
Good learning rates to try: 1e-1, 1e-2, 1e-3, 1e-4
第四步:在粗略范围(分散的数值)内尝试超参数,训练大约1-5 epochs
快速发现哪些超参数有效。在对数范围内采样,如learning_rate = 10 ** uniform(-6, 1)
Choose a few values of learning rate and weight decay around what worked from Step 3, train a few models for ~1-5 epochs.
Good weight decay to try: 1e-4, 1e-5, 0
第五步:细化超参数采样的范围,训练更长的时间
在上一步确定的范围内搜索更精确的数值。注意如果最优超参数发生在采样边缘,则意味着采样区间可能有问题,要及时调整采样区间,让最优超参数在采样区间中间段
Pick best models from Step 4, train them for longer (~10-20 epochs) without learning rate decay
第六步:观察loss和accuracy曲线
第七步:返回步骤五
下面是第六步的提示
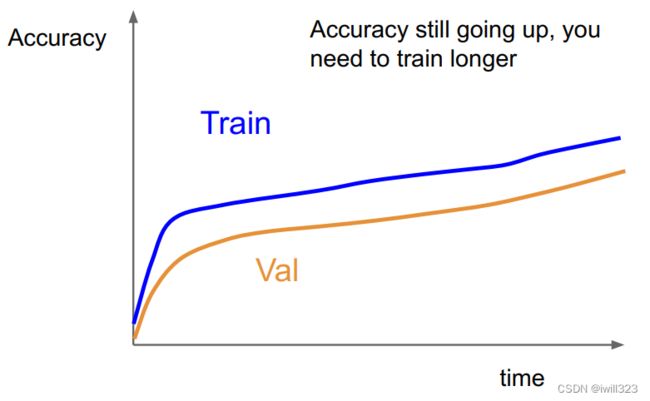 |
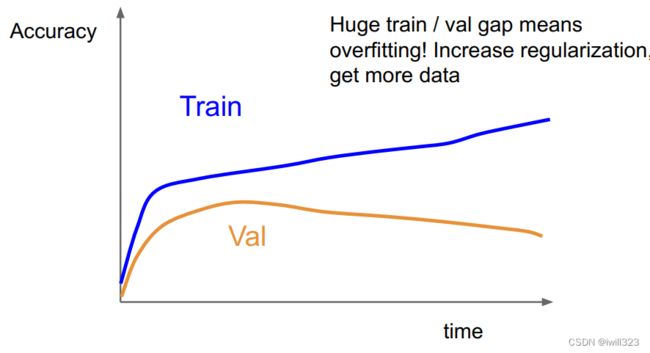 |
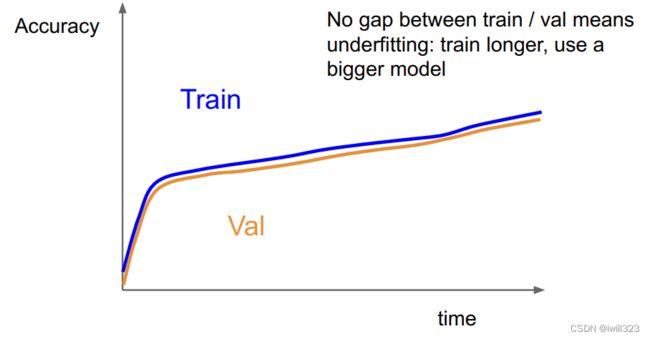 |
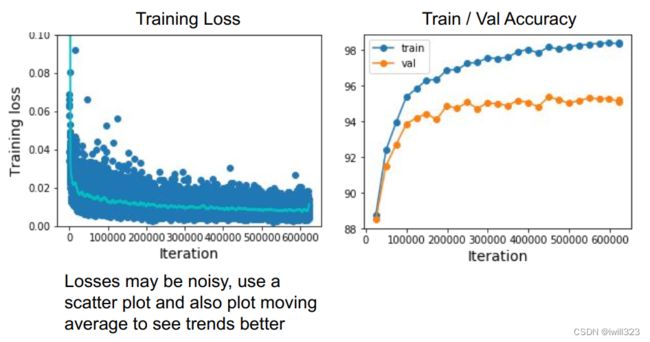

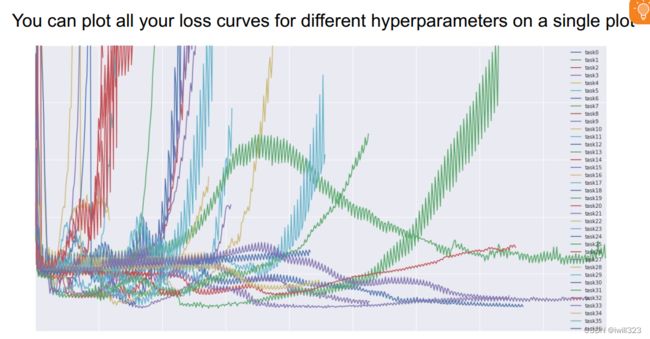
Random Search 和 Grid Search
根据 Random Search for Hyper-Parameter Optimization,与网格搜索等有规律的搜索相比,随机采样的搜索方式效果更好。这是因为在多个超参数中,各个超参数对最终的识别精度的影响程度不同,而随机化选择参数能够尽可能地得到更多种参数组合。比如下图,如果使用均匀采样的话,每个参数只有3种情况,有的参数不重要,但还是控制其他参数不变,对其进行了试验,即在不重要的参数上浪费了计算;而使用随机采样的话,每个参数有9种可能的情况,有时候在实际应用中完全不知道哪个参数更加重要,随机采样调试的样本组合更多,能为重要的超参数选择不错的数值。

总结
- Improve your training error:
- Optimizers
- Learning rate schedules
- Improve your test error:
- Regularization
- Choosing Hyperparameters
We looked in detail at:
- Activation Functions (use ReLU)
- Data Preprocessing (images: subtract mean)
- Weight Initialization (use Xavier/He init)
- Batch Normalization (use this!)
- Transfer learning (use this if you can!)