PyTorch for Audio + Music Processing(2/3/4/5/6/7) :构建数据集和提取音频特征
基于Torchaudio构建数据集
文章目录
- 基于Torchaudio构建数据集
- 前言
-
- 02 Training a feed forward network
- 03 Making predictions
- 04 Creating a custom dataset
- 05 Extracting Mel spectrograms
- 06 Padding audio files
- 07 Preprocessing data on GPU
- 一、下载数据集
-
- 文件目录
- 标注格式
- 二、UrbanSoundDataset类的定义
- 三、提取梅尔频谱特征
-
- 定义梅尔转换
- 修改UrbanSoundDataset类,初始化时传入:
- 重采样
- 多声道合并
- 完善get_item
- 五、样本padding和cut
-
- cut的实现
- pad实现,右边补0
- 五、GPU支持
- 六、完整代码
- 总结
前言
本系列本来打算每一章都写笔记记录下来,不过看来几个视频之后,发现2,3其只是在普及torch以及复现基础手写字体识别的例子,与torchaudio和音频处理关系不大,就跳过,感兴趣的可以直接看代码。4,5,6,7都是在讲解如何构建数据集,所以一并记录:
02 Training a feed forward network
构建和训练mnist手写字符识别网络
03 Making predictions
推理接口的实现
04 Creating a custom dataset
创建数据集处理类
05 Extracting Mel spectrograms
基于torchaudio提取音频的梅尔频谱特征
06 Padding audio files
样本的Padding和cut
07 Preprocessing data on GPU
使用GPU训练
一、下载数据集
官方数据集要注册才能下载,直接从这里urbansound8k下载。
文件目录

其中audio是音频文件,大概8700多个
metadata为标注的文件夹
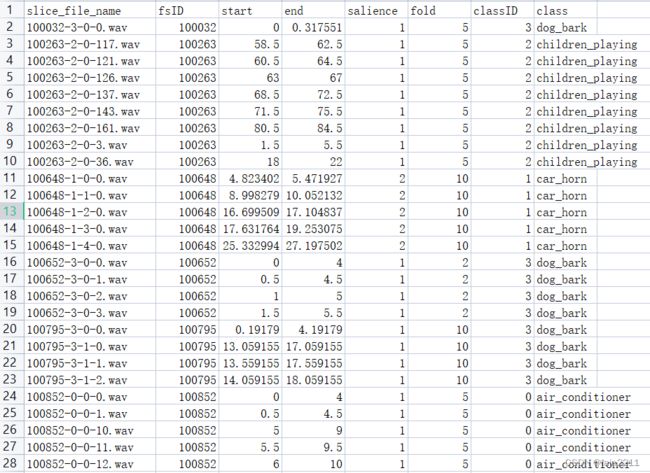
标注格式
metadata/UrbanSound8K.csv:
二、UrbanSoundDataset类的定义
class UrbanSoundDataset(Dataset):
def __init__(self, annotations_file, audio_dir):
self.annotations = pd.read_csv(annotations_file)
# 使用panda加载csv
self.audio_dir = audio_dir
def __len__(self):
return len(self.annotations)
def __getitem__(self, index):
audio_sample_path = self._get_audio_sample_path(index)
label = self._get_audio_sample_label(index)
signal, sr = torchaudio.load(audio_sample_path)
# 返回tensor类型的音频序列和采样率,与librosa.load的区别是,librosa返回的音频序列是numpy格式
return signal, label
def _get_audio_sample_path(self, index):
fold = f"fold{self.annotations.iloc[index, 5]}"
path = os.path.join(self.audio_dir, fold, self.annotations.iloc[
index, 0])
return path
def _get_audio_sample_label(self, index):
return self.annotations.iloc[index, 6]
三、提取梅尔频谱特征
梅尔频谱为音频信号处理中常见的特征表示,torchaudio中使用torchaudio.transforms模块来实现
定义梅尔转换
mel_spectrogram = torchaudio.transforms.MelSpectrogram(
sample_rate=SAMPLE_RATE,
n_fft=1024,
hop_length=512,
n_mels=64
)
修改UrbanSoundDataset类,初始化时传入:
class UrbanSoundDataset(Dataset):
def __init__(self, annotations_file, audio_dir, transformation,
target_sample_rate):
self.annotations = pd.read_csv(annotations_file)
self.audio_dir = audio_dir
self.transformation = transformation
self.target_sample_rate = target_sample_rate
重采样
在梅尔转换之前,需要对音频信号进行重采样和多声道合并,所以定义这两个函数:
def _resample_if_necessary(self, signal, sr):
# 每个信号的采样率不一致,如果跟共有变量的采样率不一致的话,需要重采样
if sr != self.target_sample_rate:
resampler = torchaudio.transforms.Resample(sr, self.target_sample_rate)
signal = resampler(signal)
return signal
多声道合并
def _mix_down_if_necessary(self, signal):
# 每个signal -> (channel,samples) -> (2,16000) -> (1,16000)
# 需要把所有的通道混合起来,保持维度不变
if signal.shape[0] > 1:
signal = torch.mean(signal, dim=0, keepdim=True)
return signal
完善get_item
然后在get_item的函数里把几个函数串起来,则完成了梅尔频谱特征提取的过程:
def __getitem__(self, index):
audio_sample_path = self._get_audio_sample_path(index)
label = self._get_audio_sample_label(index)
signal, sr = torchaudio.load(audio_sample_path)
signal = self._resample_if_necessary(signal, sr) # 重采样
signal = self._mix_down_if_necessary(signal) # 多声道合并
signal = self.transformation(signal) # 梅尔频谱提取
return signal, label
五、样本padding和cut
由于训练的要求,需要把每个信号样本都缩放到同一尺度,所以使用了padding(尺度小于阈值),cut(尺度大于阈值)的处理,添加两个函数:
cut的实现
直接取前面到阈值的部分(似乎有点简单粗暴?)
def _cut_if_necessary(self, signal):
# 举例 signal -> Tensor -> (1,num_samples) -> (1,50000) -> 切片后变成 (1,22500)
if signal.shape[1] > self.num_samples:
signal = signal[:, :self.num_samples]
return signal
pad实现,右边补0
def _right_pad_if_necessary(self, signal):
length_signal = signal.shape[1]
if length_signal < self.num_samples:
num_missing_samples = self.num_samples - length_signal
last_dim_padding = (0, num_missing_samples)
# 每个signal都是二维的,所以以上式子,第一个0是不pad的,只pad第二维
signal = torch.nn.functional.pad(signal, last_dim_padding)
return signal
五、GPU支持
就是加了一个判断,这也单独列了一章……
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
print(f"Using device {device}")
六、完整代码
import os
import torch
from torch.utils.data import Dataset
import pandas as pd
import torchaudio
class UrbanSoundDataset(Dataset):
def __init__(self,
annotations_file,
audio_dir,
transformation,
target_sample_rate,
num_samples,
device):
self.annotations = pd.read_csv(annotations_file)
self.audio_dir = audio_dir
self.device = device
self.transformation = transformation.to(self.device)
self.target_sample_rate = target_sample_rate
self.num_samples = num_samples
def __len__(self):
return len(self.annotations)
def __getitem__(self, index):
audio_sample_path = self._get_audio_sample_path(index)
label = self._get_audio_sample_label(index)
signal, sr = torchaudio.load(audio_sample_path)
signal = signal.to(self.device)
signal = self._resample_if_necessary(signal, sr)
signal = self._mix_down_if_necessary(signal)
signal = self._cut_if_necessary(signal)
signal = self._right_pad_if_necessary(signal)
signal = self.transformation(signal)
return signal, label
def _cut_if_necessary(self, signal):
if signal.shape[1] > self.num_samples:
signal = signal[:, :self.num_samples]
return signal
def _right_pad_if_necessary(self, signal):
length_signal = signal.shape[1]
if length_signal < self.num_samples:
num_missing_samples = self.num_samples - length_signal
last_dim_padding = (0, num_missing_samples)
signal = torch.nn.functional.pad(signal, last_dim_padding)
return signal
def _resample_if_necessary(self, signal, sr):
if sr != self.target_sample_rate:
resampler = torchaudio.transforms.Resample(sr, self.target_sample_rate)
signal = resampler(signal)
return signal
def _mix_down_if_necessary(self, signal):
if signal.shape[0] > 1:
signal = torch.mean(signal, dim=0, keepdim=True)
return signal
def _get_audio_sample_path(self, index):
fold = f"fold{self.annotations.iloc[index, 5]}"
path = os.path.join(self.audio_dir, fold, self.annotations.iloc[
index, 0])
return path
def _get_audio_sample_label(self, index):
return self.annotations.iloc[index, 6]
if __name__ == "__main__":
ANNOTATIONS_FILE = "/home/valerio/datasets/UrbanSound8K/metadata/UrbanSound8K.csv"
AUDIO_DIR = "/home/valerio/datasets/UrbanSound8K/audio"
SAMPLE_RATE = 22050
NUM_SAMPLES = 22050
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
print(f"Using device {device}")
mel_spectrogram = torchaudio.transforms.MelSpectrogram(
sample_rate=SAMPLE_RATE,
n_fft=1024,
hop_length=512,
n_mels=64
)
usd = UrbanSoundDataset(ANNOTATIONS_FILE,
AUDIO_DIR,
mel_spectrogram,
SAMPLE_RATE,
NUM_SAMPLES,
device)
print(f"There are {len(usd)} samples in the dataset.")
signal, label = usd[0]
总结
以上就是整个数据集的定义、加载、预处理及梅尔频谱特征提取过程,为后续的训练做好数据的准备。