《在现实世界啥也不会的我,到了异世界依旧是个废物》之基于YOLOV7的人体姿态估计保姆级入门教学
基于YOLOV7的人体姿态估计与之前的目标检测区别不大,如果不知道如何安装和使用YOLOV7进行目标检测的话,请移步我的上一篇博客。
(3条消息) 《关于我被车创④,转生到异世界以后什么都不会,于是从零开始搞深度学习这回事》之 yolov7保姆级教学_深度学习鲨我的博客-CSDN博客
在GitHub上把YOLOV7的源码下载下来以后,还需要下载一个对应的权重文件,链接如下。
GitHub - WongKinYiu/yolov7: Implementation of paper - YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
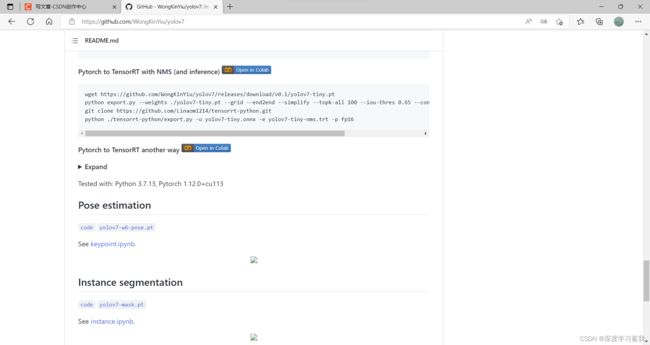
在Pose estimation这里,直接点击下面的yolov7-w6-pose.pt即可,下载完成以后,将该权重文件拖入YOLOV7文件夹中,不用特地为他创建一个文件夹,随便放。
这里附上测试代码。
import torch
import cv2
import numpy as np
import time
from torchvision import transforms
from utils.datasets import letterbox
from utils.general import non_max_suppression_kpt
from utils.plots import output_to_keypoint, plot_skeleton_kpts
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
weigths = torch.load('yolov7-w6-pose.pt')
model = weigths['model']
model = model.half().to(device)
_ = model.eval()
cap = cv2.VideoCapture(0)
if (cap.isOpened() == False):
print('open failed.')
# 分辨率
frame_width = int(cap.get(3))
frame_height = int(cap.get(4))
# 图片缩放
vid_write_image = letterbox(cap.read()[1], (frame_width), stride=64, auto=True)[0]
resize_height, resize_width = vid_write_image.shape[:2]
save_name = f"{'test-30.mp4' .split('/')[-1].split('.')[0]}"
# 保存结果视频
out = cv2.VideoWriter("test-100.mp4",
cv2.VideoWriter_fourcc(*'mp4v'), 30,
(resize_width, resize_height))
# frame_count = 0
# total_fps = 0
while(cap.isOpened):
ret, frame = cap.read()
if ret:
orig_image = frame
image = cv2.cvtColor(orig_image, cv2.COLOR_BGR2RGB)
image = letterbox(image, (frame_width), stride=64, auto=True)[0]
image_ = image.copy()
image = transforms.ToTensor()(image)
image = torch.tensor(np.array([image.numpy()]))
image = image.to(device)
image = image.half()
start_time = time.time()
with torch.no_grad():
output, _ = model(image)
end_time = time.time()
# 计算fps
# fps = 1 / (end_time - start_time)
# total_fps += fps
# frame_count += 1
output = non_max_suppression_kpt(output, 0.25, 0.65, nc=model.yaml['nc'], nkpt=model.yaml['nkpt'], kpt_label=True)
output = output_to_keypoint(output)
nimg = image[0].permute(1, 2, 0) * 255
nimg = nimg.cpu().numpy().astype(np.uint8)
nimg = cv2.cvtColor(nimg, cv2.COLOR_RGB2BGR)
for idx in range(output.shape[0]):
plot_skeleton_kpts(nimg, output[idx, 7:].T, 3)
# 显示fps
# cv2.putText(nimg, f"{fps:.3f} FPS", (15, 30), cv2.FONT_HERSHEY_SIMPLEX,
# 1, (0, 255, 0), 2)
# 显示结果并保存
cv2.imshow('image', nimg)
out.write(nimg)
# 按q退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
break
# 资源释放
cap.release()
cv2.destroyAllWindows()
# 计算平均fps
# avg_fps = total_fps / frame_count
# print(f"Average FPS: {avg_fps:.3f}")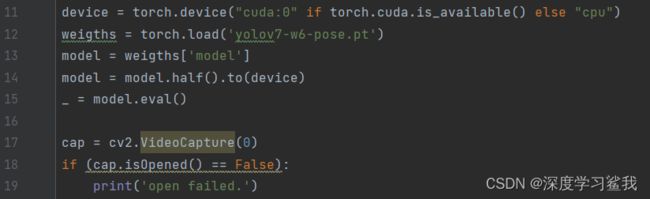
这里注意几个需要修改的地方,11行中,如果你有gpu则不需要修改,如果没有,就把那个cuda:0改为cpu即可。17行中,如果你要检测具体的图片或者视频,请将括号中的0改为该文件的地址,地址要加单引号‘’,如果要用摄像头,电脑自带摄像头是0,外接摄像头是1。
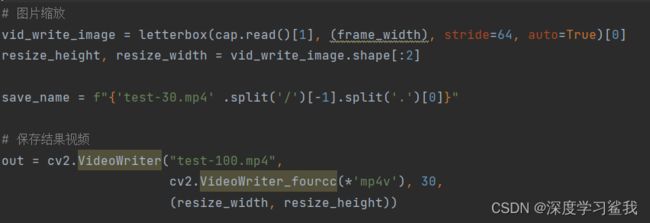
上面的save-name中填的东西和你要检测文件名字是一样的,下面保存结果视频中填的名字是自定义的,但是如果你是用的摄像头的话,随便,填啥都可以。
(里面本来有个帧率检测的,但是我运行的时候一直报错,不知道为啥,所以我给他注释掉了,如果你知道怎么改的话,也可以自己把那个改过来。)