【pytorch】余弦退火算法解读
every blog every motto: You can do more than you think.
0. 前言
记录余弦退火
1. 正文
1.1 Cosine Annealing Warm Restarts
1.1.1 官方解释
先放官网截图

1.1.2 测试
1. 第一次测试
1. 代码
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import CosineAnnealingLR, CosineAnnealingWarmRestarts
import itertools
import matplotlib.pyplot as plt
class Tmodel(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
model = Tmodel()
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=5)
print("初始化的学习率:", optimizer.defaults['lr'])
lr_list = [] # 把使用过的lr都保存下来,之后画出它的变化
for epoch in range(1, 31):
# train
optimizer.zero_grad()
optimizer.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer.param_groups[0]['lr']))
lr_list.append(optimizer.param_groups[0]['lr'])
scheduler.step()
# 画出lr的变化
plt.plot(list(range(1, 31)), lr_list)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("learning rate's curve changes as epoch goes on!")
plt.show()
说明:
- CosineAnnealingWarmRestarts中我们传了一个参数T_0=5
- 其他参数为默认
2. 运行结果:

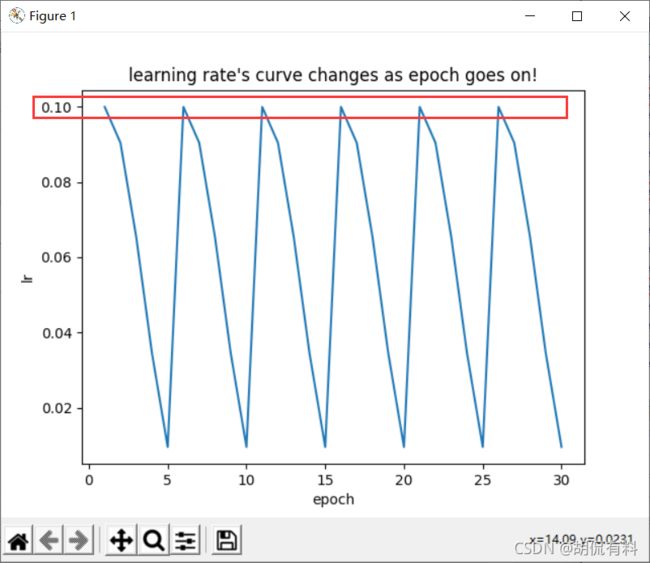
2. 第二次测试
1. 代码
代码如之前相同,唯一不同的时,将默认的T_mult=1修改为T_mult=2,如下图所示:
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=5,T_mult=2)
2. 运行结果


3. 参数解释
T_0:为我们学习率恢复到初始值的迭代次数(epoch)
注意: 学习率恢复到初始值以后,T_0是会更新的,更新公式为:
T_0 = T_0 × T_mult
学习率会从初始值下降到一个最小值(这个最小值根据公式得出),我们这里把这样一个过程定义为“一轮”,从上面的测试中可以看到,
- “一轮”的迭代次数是逐渐增加的,即,从初始值到最小值的epoch数增加(如果T_mult非默认)
- “一轮”中的最小值是逐渐减小的(如果T_mult非默认),这就需要另一个参数控制这个逐渐变小的过程:eta_min
eta_min:最小学习率
3. 更进一步
我们将上面测试2代码中的如下代码:
片段1:
for epoch in range(1, 31):
# train
optimizer.zero_grad()
optimizer.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer.param_groups[0]['lr']))
lr_list.append(optimizer.param_groups[0]['lr'])
scheduler.step()
替换为:
说明: 因为我们一个epoch中包含多次迭代
片段2:
for epoch in range(1, 31):
# train
for it in range(1,3):
optimizer.zero_grad()
optimizer.step()
print("第%d个epoch,迭代:%d,学习率:%f" % (epoch,it, optimizer.param_groups[0]['lr']))
lr_list.append(optimizer.param_groups[0]['lr'])
scheduler.step()
替换前,“一轮”的变换为:
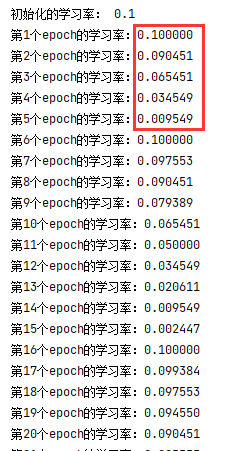
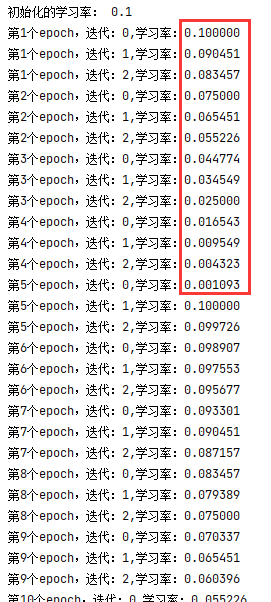
替换以后的的结果为:

我们发现其中的值是相同的,依次递减。实际上这个如下代码有关:
scheduler.step()
即我们调用依次,学习率更新一次。但是其中的默认参数为epoch,即,调用依次,参数epoch+1,这和官方文档中的第二份代码注释部分相同,如下:

我们知道,一个epoch表示将所有数据遍历一遍,其中包含多次迭代,正常代码如我们上面替换的所示,但依然有点问题,应该将如下代码添加参数,
scheduler.step()
正确做法如官网所示:

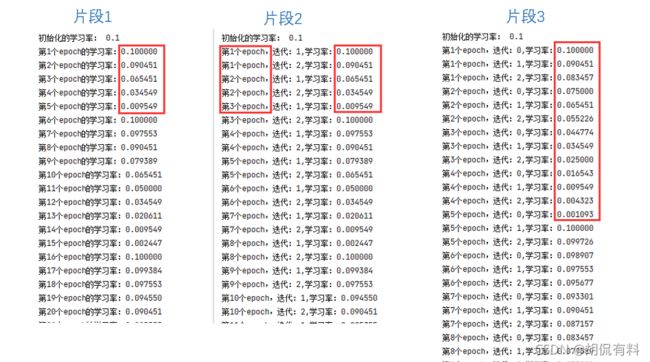
因此,我们将我们的片段2优化为如下:
片段3:
iters = 3
for epoch in range(1, 31):
# train
for it in range(iters):
optimizer.zero_grad()
optimizer.step()
print("第%d个epoch,迭代:%d,学习率:%f" % (epoch, it, optimizer.param_groups[0]['lr']))
lr_list.append(optimizer.param_groups[0]['lr'])
scheduler.step(epoch + it / iters)
这样做到每迭代一次更新一次,但更新幅度不会太大,如下:
最后,我们进行一次结果对比图的展示,如下:
参考文献
[1] https://pytorch.org/docs/stable/generated/torch.optim.lr_scheduler.CosineAnnealingWarmRestarts.html?highlight=cosineannealingwarmrestarts#torch.optim.lr_scheduler.CosineAnnealingWarmRestarts
[2] https://blog.csdn.net/qq_37612828/article/details/108213578
[3] https://blog.csdn.net/weixin_35848967/article/details/108493217
[4] https://www.jianshu.com/p/7099565063e8
[5] https://zhuanlan.zhihu.com/p/261134624