Python数据分析(4):jieba分词详解
文章目录
- jieba分词器
-
- 1. jieba分词器的分词模式说明
-
- (1)精确模式
- (2)全模式
- (3)搜索引擎模式
- (4)Paddle模式
- 2. jieba分词器的基本用法
-
- (1)三种模式案例
- (2)词性标注
- (3)识别新词:HMM参数
- (4)搜索引擎模式分词:cut_for_search()函数
- 3. 调整词典
-
- (1)使用自定义词典:load_userdict()函数
- (2)动态修改词典:add_word()、del_word()函数
- (3)调节词频:suggest_freq()函数
- 4. 关键词提取
-
- (1)基于TF-IDF算法的关键词提取:extract_tags()函数
- (2)基于TextRank算法的关键词提取:textrank()函数
- 5. 停用词过滤
- 6. 词频统计
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站:人工智能从入门到精通教程
jieba分词器
1. jieba分词器的分词模式说明
jieba分词器提供4种分词模式,并且支持简体/繁体分词、自定义词典、关键词提取、词性标注。
(1)精确模式
该模式会将句子最精确地切分开,适合在文本分析时使用。
(2)全模式
该模式会将句子中所有成词的词语都扫描出来,速度也非常快,缺点是不能解决歧义问题,有歧义的词语也会被扫描出来。
(3)搜索引擎模式
该模式会在精确模式的基础上对长词再进行切分,将更短的词语切分出来。在搜索引擎中,要求输入词语的一部分也能检索到整个词语相关的文档,所以该模式适用于搜索引擎分词。
(4)Paddle模式
该模式利用PaddlePaddle深度学习框架,训练序列标注网络模型实现分词,同时支持词性标注。该模式在4.0及以上版本的jieba分词器中才能使用。使用该模式需要安装paddlepaddle模块。
2. jieba分词器的基本用法
在Python中,可以使用jieba模块的cut()函数进行分词,返回结果是一个迭代器。
cut()函数有4个参数:
- 第一个参数:待分词文本
- cut_all:设置使用全模式(True)还是精确模式(False); 默认False
- use_paddle:控制是否使用Paddle模式进行分词
- HMM:控制是否使用HMM模式识别新词
(1)三种模式案例
设置参数cut_all为True:全分词
import jieba
str1 = '我来到了西北皇家理工学院,发现这儿真不错'
seg_list = jieba.cut(str1, cut_all=True) # 使用全模式进行分词 生成列表
print('全模式分词结果:', '/'.join(seg_list)) # /拼接列表元素
全模式分词结果: 我/来到/了/西北/皇家/理工/理工学/理工学院/工学/工学院/学院/,/发现/这儿/真不/真不错/不错
设置参数cut_all为False:精确分词
import jieba
str1 = '我来到了西北皇家理工学院,发现这儿真不错'
seg_list = jieba.cut(str1, cut_all=False) # 使用精确模式进行分词
print('精确模式分词结果:', '/'.join(seg_list))
精确式分词结果: 我/来到/了/西北/皇家/理工学院/,/发现/这儿/真不错
cut_all参数不给定时,默认为false,即精确分词
import jieba
str1 = '我来到了西北皇家理工学院,发现这儿真不错'
seg_list = jieba.cut(str1)
print('全模式分词结果:', '/'.join(seg_list))
精确模式分词结果: 我/来到/了/西北/皇家/理工学院/,/发现/这儿/真不错
use_paddle参数可以设置开启paddle模式
import jieba
import paddle
str1 = '我来到了西北皇家理工学院,发现这儿真不错'
#jieba.enable_paddle() 已经停用
paddle.enable_static()
seg_list = jieba.cut(str1, use_paddle=True) #使用paddle模式进行分词
print('Paddle模式分词结果:', '/'.join(seg_list))
Paddle模式分词结果: 我/来到/了/西北/皇家/理工学院/,/发现/这儿/真不错
(2)词性标注
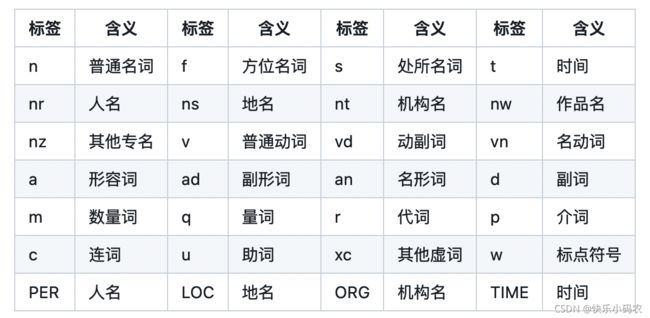
import jieba
import jieba.posseg as pseg
#jieba.enable_paddle()
str2 = '上海自来水来自海上'
seg_list = pseg.cut(str2, use_paddle=True) #使用posseg进行分词
for seg, flag in seg_list:
print(seg, flag)
上海 ns
自来水 l
来自 v
海上 s
(3)识别新词:HMM参数
HMM参数设置为True,可以识别新词,即词典中不存在的词。
词典为jieba分词自带的字典。
如下:他知
import jieba
str3 = '他知科技研发有限公司是一家互联网行业的公司'
seg_list = jieba.cut(str3, HMM=True) #HMM默认为True,所以可以不设置
print('精确模式分词结果:', '/'.join(seg_list))
精确模式分词结果: 他知/科技/研发/有限公司/是/一家/互联网/行业/的/公司
(4)搜索引擎模式分词:cut_for_search()函数
cut_for_search()函数可以进行搜索引擎模式分词
该函数只有两个参数:
- 第一个参数:待分词文本
- 第二个参数:HMM,默认为True
import jieba
str1 = '我来到了西北皇家理工学院,发现这儿真不错'
seg_list = jieba.cut_for_search(str1)
print('搜索引擎模式分词结果:', '/'.join(seg_list))
搜索引擎模式分词结果: 我/来到/了/西北/皇家/理工/工学/学院/理工学/工学院/理工学院/,/发现/这儿/真不/不错/真不错
3. 调整词典
用户也可以自己生成一个自定义词典,包含jieba分词自带字典中没有的词语,添加到程序中。比如:

注意:词频、词性可省略。
未加载自定义字典时使用精确切分来进行分词
import jieba
seg_list = jieba.cut(
'心灵感应般地蓦然回首,才能撞见那一低头的温柔;也最是那一低头的温柔,似一朵水莲花不胜凉风的娇羞;也最是那一抹娇羞,才能让两人携手共白首。')
print('未加载自定义词典时的精确模式分词结果:\n', '/'.join(seg_list))
未加载自定义词典时的精确模式分词结果:
心灵感应/般地/蓦然回首/,/才能/撞见/那一/低头/的/温柔/;/也/最/是/那/一/低头/的/温柔/,/似/一朵/水/莲花/不胜/凉风/的/娇羞/;/也/最/是/那/一抹/娇羞/,/才能/让/两人/携手/共/白首/。
(1)使用自定义词典:load_userdict()函数
load_userdict()函数加载用户自定义字典
import jieba
jieba.load_userdict('用户词典.txt')
seg_list = jieba.cut(
'心灵感应般地蓦然回首,才能撞见那一低头的温柔;也最是那一低头的温柔,似一朵水莲花不胜凉风的娇羞;也最是那一抹娇羞,才能让两人携手共白首。')
print('加载自定义词典时的精确模式分词结果:\n', '/'.join(seg_list))
加载自定义词典时的精确模式分词结果:
心灵感应/般地/蓦然回首/,/才能/撞见/那/一低头/的/温柔/;/也/最/是/那/一低头/的/温柔/,/似/一朵/水莲花/不胜/凉风/的/娇羞/;/也/最/是/那/一抹/娇羞/,/才能/让/两人/携手/共/白首/。
(2)动态修改词典:add_word()、del_word()函数
1. 动态添加词:add_word()
import jieba
jieba.load_userdict('用户词典.txt')
jieba.add_word('最是') #添加词, 但是不会添加到 用户字典.txt 文件中
seg_list = jieba.cut(
'心灵感应般地蓦然回首,才能撞见那一低头的温柔;也最是那一低头的温柔,似一朵水莲花不胜凉风的娇羞;也最是那一抹娇羞,才能让两人携手共白首。')
print('添加自定义词时的精确模式分词结果:\n', '/'.join(seg_list))
添加自定义词时的精确模式分词结果:
心灵感应/般地/蓦然回首/,/才能/撞见/那/一低头/的/温柔/;/也/最是/那/一低头/的/温柔/,/似/一朵/水莲花/不胜/凉风/的/娇羞/;/也/最是/那/一抹/娇羞/,/才能/让/两人/携手/共/白首/。
2.动态删除词:del_word()
import jieba
jieba.load_userdict('用户词典.txt')
jieba.del_word('一低头')
seg_list = jieba.cut('心灵感应般地蓦然回首,才能撞见那一低头的温柔;也最是那一低头的温柔,似一朵水莲花不胜凉风的娇羞;也最是那一抹娇羞,才能让两人携手共白首。')
print('删除自定义词时的精确模式分词结果:\n', '/'.join(seg_list))
删除自定义词时的精确模式分词结果:
心灵感应/般地/蓦然回首/,/才能/撞见/那一/低头/的/温柔/;/也/最/是/那/一/低头/的/温柔/,/似/一朵/水莲花/不胜/凉风/的/娇羞/;/也/最/是/那/一抹/娇羞/,/才能/让/两人/携手/共/白首/。
(3)调节词频:suggest_freq()函数
不修改词频前:
#不修改词频
import jieba
str3 = '他认为未来几年健康产业在GDP中将占比第一。'
seg_list = jieba.cut(str3)
print('精确模式分词结果:\n', '/'.join(seg_list))
精确模式分词结果:
他/认为/未来/几年/健康/产业/在/GDP/中将/占/比/第一/。
修改词频后:
#修改词频
import jieba
str3 = '他认为未来几年健康产业在GDP中将占比第一。'
jieba.suggest_freq(('中', '将'), True) #修改词频 强制“中将”
jieba.suggest_freq('占比', True) #强制让“占比”作为一次词
seg_list = jieba.cut(str3, HMM=False)
print('精确模式分词结果:\n', '/'.join(seg_list))
精确模式分词结果:
他/认为/未来/几年/健康/产业/在/GDP/中/将/占比/第一/。
4. 关键词提取
从文本文件中提取关键词的理论方法主要有两种:
第一种是有监督的学习方法,该方法将关键词的提取视为一个二分类问题,要么是关键词,要么不是
第二种是无监督的学习方法,该方法对候选词进行打分,大风范最高的候选词为关键词
常见的打分算法有TF-IDF和TextRank。
(1)基于TF-IDF算法的关键词提取:extract_tags()函数
extract_tags()函数能基于TF-IDF算法提取关键词
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
该函数有四个参数:
- sentence:待提取关键词的文本
- topK:关键词数
- withWeight:是否返回权重
- allowPOS:指定筛选关键词的词性;默认不分词性
基于TF-IDF算法的关键词提取
# 基于TF-IDF算法的关键词提取
from jieba import analyse
text = '记者日前从中国科学院南京地质古生物研究所获悉,该所早期生命研究团队与美国学者合作,在中国湖北三峡地区的石板滩生物群中,发现了4种形似树叶的远古生物。这些“树叶”实际上是形态奇特的早期动物,它们生活在远古海洋底部。相关研究成果已发表在古生物学国际专业期刊《古生物学杂志》上。'
keywords = analyse.extract_tags(text, topK=10, withWeight=True, allowPOS=('n', 'v'))
print(keywords)
[('古生物学', 0.783184303024), ('树叶', 0.6635900468544), ('生物群', 0.43238540794400004), ('古生物', 0.38124919198039997), ('期刊', 0.36554014868720003), ('石板', 0.34699723913040004), ('形似', 0.3288202017184), ('研究成果', 0.3278758070928), ('团队', 0.2826627565264), ('获悉', 0.28072960723920004)]
(2)基于TextRank算法的关键词提取:textrank()函数
textrank()函数能基于TextRank算法提取关键字
jieba.analyse.textrank(sentance, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
两种方法的区别是默认提取的词性不同
当然算法不同,结果可能有差异
基于TextRank算法的关键词提取
# 基于TextRank算法的关键词提取
from jieba import analyse
text = '记者日前从中国科学院南京地质古生物研究所获悉,该所早期生命研究团队与美国学者合作,在中国湖北三峡地区的石板滩生物群中,发现了4种形似树叶的远古生物。这些“树叶”实际上是形态奇特的早期动物,它们生活在远古海洋底部。相关研究成果已发表在古生物学国际专业期刊《古生物学杂志》上。'
keywords = analyse.textrank(text, topK=10, withWeight=True, allowPOS=('n', 'v'))
print(keywords)
[('古生物学', 1.0), ('树叶', 0.8797803471074045), ('形似', 0.6765568513591282), ('专业', 0.6684901270801065), ('生物', 0.648692596888148), ('发表', 0.6139083953888275), ('生物群', 0.59981945604977), ('期刊', 0.5651065025924439), ('国际', 0.5642917600351786), ('获悉', 0.5620719278559326)]
5. 停用词过滤
停用词:“你”、“我”、“的”、“在”及标点符号等大量出现但非关键词的词。
我们可以把它们过滤掉
启动停用词过滤前:
#未启动停用词过滤
import jieba
text = '商务部4月23日发布的数据显示,一季度,全国农产品网络零售额达936.8亿元,增长31.0%;电商直播超过400万场。电商给农民带来了新的机遇。'
seg_list = jieba.cut(text)
print('未启用停用词过滤时的分词结果:\n', '/'.join(seg_list))
未启用停用词过滤时的分词结果:
商务部/4/月/23/日/发布/的/数据/显示/,/一季度/,/全国/农产品/网络/零售额/达/936.8/亿元/,/增长/31.0%/;/电商/直播/超过/400/万场/。/电商/给/农民/带来/了/新/的/机遇/。
为了过滤停用词,需要有一个停用词词典。
我们可以自己制作停用词词典,停用词词典的内容是根据NLP的目的变化的。
如果制作太慢,可以百度下载一个停用词词典,稍作修改成自己想要的。如下:

启动停用词过滤后:
#启动停用词过滤
import jieba
with open('stopwords.txt', 'r+', encoding = 'utf-8')as fp:
stopwords = fp.read().split('\n') #将停用词词典的每一行停用词作为列表中的一个元素
word_list = [] #用于存储过滤停用词后的分词结果
text = '商务部4月23日发布的数据显示,一季度,全国农产品网络零售额达936.8亿元,增长31.0%;电商直播超过400万场。电商给农民带来了新的机遇。'
seg_list = jieba.cut(text)
for seg in seg_list:
if seg not in stopwords:
word_list.append(seg)
print('启用停用词过滤时的分词结果:\n', '/'.join(word_list))
启用停用词过滤时的分词结果:
商务部/4/月/23/日/发布/数据/显示/一季度/全国/农产品/网络/零售额/达/936.8/亿元/增长/31.0%/电商/直播/超过/400/万场/电商/农民/带来/新/机遇
注意:我们根据不同的编码方式,修改encoding参数
6. 词频统计
import jieba
text = '蒸馍馍锅锅蒸馍馍,馍馍蒸了一锅锅,馍馍搁上桌桌,桌桌上面有馍馍。'
with open('stopwords.txt', 'r+', encoding = 'utf-8')as fp:
stopwords = fp.read().split('\n') #加载停用词
word_dict = {} #用于存储词频统计结果的词典
jieba.suggest_freq(('桌桌'), True) #让“桌桌”作为一个词
seg_list = jieba.cut(text)
for seg in seg_list:
if seg not in stopwords:
if seg in word_dict.keys():
word_dict[seg] += 1 #存在则词频+1
else:
word_dict[seg] = 1 #不存在则存入键值对
print(word_dict)
{'蒸': 3, '馍馍': 5, '锅锅': 1, '一锅': 1, '锅': 1, '搁': 1, '桌桌': 2, '上面': 1}