Recsys21 | 浅谈推荐系统如何在NLP的肩膀上前进
大家好,我是蘑菇先生。今天来聊聊推荐系统是如何在NLP的肩膀上前进的。
最近在读Recsys2021上的paper,Transformers4Rec: Bridging the Gap between NLP and Sequential/Session-Based Recommendation。

实际读完后,信息量很足,挺有收获,确实非常有意思。除了文章提出的方法本身,最有意思的是其关于NLP和推荐系统研究进程的关系的梳理和阐述,能够为大家大致描述出NLP和推荐系统的发展脉络。同时,也能够启发我们不同领域之间是相互影响和相互借鉴的,在研究某个领域的时候,也不妨多关注一下其它领域的进展,说不定能够启发研究或者工作思路。
1.研究动机
近年来,序列/会话推荐上的进展很多都源自于NLP模型和预训练技术的发展,可以说推荐系统是在NLP的肩膀上前进的。尤其是Transformers架构,在BERT等预训练模型中广泛应用,也在序列推荐中初露端倪。然而,推荐系统的发展实际上是滞后于NLP的。NLP中花式Transformers架构层出不穷,比如:邱锡鹏组的survey[2]集中展示了Transformer架构的演进;NLP中的开源社区也十分活跃,比如HuggingFace的开源库Transformers[4]涵盖了大部分主流的Transformers实现,总之,Transformers在NLP研究中正如火如荼地开展着。
然而,在推荐系统中的应用很多只停留在最原始的Transformer[3]。很大程度上是因为缺乏一个类似HuggingFace的统一轮子,研究者想在此基础上做迭代实际上相比于NLP会困难不少。
为了弥补这种发展鸿沟,作者开源了一个基于HuggingFace开源库[4]的序列推荐包Transformers4Rec,目的是希望推荐系统社区能够更快地follow到NLP社区在Transformers中的进展,并在序列/会话推荐任务中实现开箱即用。
那么这个库除了API层面的开发以外,还有什么优势呢?为了展现这个库的强大之处,作者在这篇论文中集中展现了:
如何使用Transformers4Rec赢了两个最新的会话推荐比赛。
以会话推荐为例,深入对比不同的Transformers架构和训练技巧。
最佳调优的Transfomers架构在公开的2个电商推荐数据上,超过了SOA的模型;除了电商领域之外,在2个新闻推荐数据上,也能和基线模型打平。
将不同的NLP预训练任务应用到序列推荐的训练过程中,并分析其性能差异。如CLM(Causal Language Modeling, GPT中用的), MLM(masked Language Modeling, BERT中用的), PLM(permutation language modeling, XLNet中用的), RTD (replacement token detection, XLNet中用的)。使用带RTD的XLNet架构在所有的数据集上表现均超过SOA模型。
最后,引入了推荐系统中常用的辅助信息到Transformers中进行建模,如item,user,context,均能够提升性能。引入辅助信息这一点也是推荐系统和NLP比较大的区别。
完整的代码开源在了github:https://github.com/NVIDIA-Merlin/Transformers4Rec/
2.推荐系统和NLP发展的联系
近年来,关于序列推荐的工作也是层出不穷,survey[5]集中展示了基于深度学习的序列推荐研究进展。在大部分的序列推荐场景中,可能都只用了用户最新的交互行为数据,或者由于用户是匿名的,所以只能用到当前会话session下的序列行为,这也就是典型的session会话推荐场景,属于序列推荐中的一种。
2.1 推荐以NLP的发展为基础的原因
在最近10年内,大部分序列推荐的工作是在NLP发展的基础上开展的,个人认为主要是因为三方面:
推荐问题和NLP问题的抽象形式非常相似[6]
推荐系统(尤其是序列推荐)的基本问题可以抽象成求解如下式子:
即求解指定在指定的历史行为记录下可能产生行为的联合条件概率。而NLP的语言模型中,第个word的概率也正是类似的形式:
当我们省略的信息,只使用历史行为记录的时候,推荐系统和NLP的基本问题变得惊人相似。
文本是推荐系统重要的side information。推荐系统中的side information多种多样,文本是其中最重要的来源之一。因此,基于NLP技术对文本做特征提取并输入到推荐系统中进行建模,就是一种很自然的想法。这样的前提下,利用最新的nlp进展来提升文本的表达能力,从而提升推荐系统的性能,也是一种很自然的动机。
NLP的研究起步远早于推荐系统。NLP最早可以追溯到20世纪40年代和50年代[7],经历了符号、规则、统计、RNN、word2vec、表征学习到预训练模型等。而推荐系统最早能追溯到20世纪90年代[8],由哥伦比亚大学的Jussi Karlgren教授在一份报告中提出,最早的协同过滤推荐也是在90年代才被提出的,经历了从协同过滤、基于内容的推荐、矩阵分解SVD、分解机FM、Facebook提出的GBDT+LR、Youtube提出的DNN、花式DNN、Graph Embedding,GNN等等。
NLP发展始终快推荐系统一步,而二者的抽象问题又非常相似,且文本是推荐系统重要的side information,因此很容易出现推荐系统社区研究人员在NLP社区的研究进展的基础上,直接应用或改进后用到推荐系统中。
2.2 早期非深度学习时代
早期非深度学习时代,推荐系统受NLP的影响工作例如:
TF-IDF,推荐中的item frequency和NLP中的word frequency存在同样的头部或长尾特点,因此TF-IDF在NLP中可以用于提取关键词,在推荐系统中也能用来推荐Item。
SVD,LSA,隐语义分析最早被拿来抽取NLP的词向量,在推荐系统中,矩阵分解同样适用于user或者item的向量表示,在Netflix比赛中SVD和进阶版SVD++夺得了冠军。
LDA,LDA最早用于NLP中的主题发现或关键词提取[31],后来也应用到推荐系统领域做基于内容的推荐或可解释推荐,这部分工作在深度学习流行起来之前非常多,各种基于概率图模型的推荐和自编码器等,都是受到LDA的影响。比如:荣获KDD2021时间检验研究奖的工作:协同主题回归[30],探讨了传统基于矩阵分解的协同过滤方法和主题模型LDA的融合,能够提供非常好的解释性和为用户建立画像标签。
2.3 深度学习时代
进入深度学习时代后,NLP对推荐系统的影响就更加深远了,先看一张图:
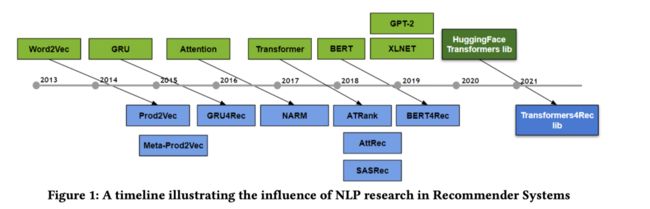
word2vec。这个影响就非常深远了,Mikolov大佬的作品,最早用于做词向量表征。也广泛影响着推荐系统的研究:
item2vec,直接把word sequence替换成用户的历史交互行为序列item sequence,就能取得很好的效果,如电商领域的Prod2vec[14]。此外在各种各样的比赛中,基本上也都会有用。核心是利用了item-item之间的共现性。这个最经典的工作非Airbnb在KDD 2018的best paper[35]莫属。
DeepWalk,稍微进阶一点的,DeepWalk,除了预处理在图上游走形成序列之外,其余的都是照搬word2vec那一套,包括训练使用skip-gram也是源自word2vec的训练方法。话说回来,基于概率的随机游走生成序列的高效实现方法Alias Table,在LDA中也被玩过了。
负采样,目前推荐系统中非常注重样本负采样,关于负采样策略的"鼻祖",我觉得word2vec论文绝对是其中之一。如基于item频次分布构造层次哈夫曼树;基于item频次的unigram分布做随机负采样等。尤其在推荐系统的召回阶段广泛应用。
RNN。NLP中常用的LSTM, GRU等也被广泛地应用在推荐系统序列推荐或者用作序列特征提取器中。经典的工作比如GRU4Rec等,还比如,推荐系统中引入文本side information时,经常使用LSTM/GRU来做特征提取器,并作为DNN的输入。
Attention。说起Attention,最早的起源实际上源于cv领域,当人类观察外界事物的时候,一般不会把事物当成一个整体去看,往往倾向于根据需要选择性的去获取被观察事物的某些重要部分。在seq2seq流行之后,就广泛地应用在了NLP领域,最早的应用比如Bengio大佬的机器翻译工作[10],在Decoder端用注意力机制引入Encoder的上下文信息,让Decoder自适应的选择合适的信息进行建模。在推荐系统中,最早的attention工作如:NARM[15] (Neural Attentive Recommendation Machine)和Attentional FM[16]。而影响比较深远、且更经典的Attention应用是DIN [11] (Deep Interest Networks),使用目标item对历史行为序列做attention。这些工作开辟了attention在推荐系统中应用的浪潮。
Transformers。Transformers中最经典的结构非self-attention莫属。在推荐系统中,不仅Transformers本身应用广泛[13,17],包括核心结构self-attention机制、多头机制等也被广泛应用,如经典的SR-GNN[12]就用了self-attention。
BERT。BERT对推荐系统的影响在近两年来也产生了不少工作,例如BERT4Rec[18],引入了双向Self-Attention进行序列建模,还比如:UBERT[19],借鉴BERT的思想提升用户表征的表达能力。
除了上述研究之外,还有不少最新前沿的推荐系统研究实际上也是深受NLP领域的影响,有一些还有着推荐系统领域"独特的味道"。
表征学习:最早的表征学习源自于NLP中做词向量。目前也广泛地在推荐系统研究领域开展着,且有着更明显的特点。推荐系统的稀疏性问题比NLP领域更严重:NLP领域的词表大小有限,但是推荐系统领域则面临着海量的用户和物品。因此,如何得到一个更合理的表征向量,对推荐系统来说非常重要。这方面工作例如早期的度量学习或近些年的图表征学习以及嵌入层的迭代等,典型工作如:KDD21上Google[20]和华为[21]的工作。
图神经网络:图神经网络可能是极少数NLP和推荐系统齐头并进的领域,或者说在NLP和推荐系统上的发展有各自的特色。在NLP中,通常更注重图的构造,如何基于word、token、entity、句法树、依存树甚至引入知识图谱等,实际上更重要,这部分工作可以参考KDD21的tutorials:Deep Learning on Graphs for Natural Language Processing[23],介绍的很仔细。在推荐系统领域,图的构造也很重要,但通常最优雅最自然的graph就是推荐系统天然的user-item二分图,因此推荐系统在GNN方面的研究则更注重模型结构上的改造、如何解决过平滑问题、可解释性、异构图建模等问题,包括GC-MC、LightGCN、SR-GNN等。
知识图谱:知识图谱源于NLP的概念,在推荐系统中也早有应用。这部分研究最经典的如TransE[32]。近年来基于知识图谱的推荐主要和图网络结合在一起做,例如KGAT[33]等,这部分工作可以Follow斯坦福王鸿伟大佬的工作[34]。
对比学习:对比学习可能最早要追溯到cv领域。后来在NLP中也广泛应用,例如SimCSE[24]。再后来又影响了推荐系统,目前基于对比学习的自监督推荐系统工作也非常多[22],今年还涌现了不少引入对比学习做纠偏的工作[25]或抗噪的工作[28]。
知识蒸馏:这方面工作实际上最早也是源于cv,出自Hinton大佬之手[26]。然后近年来随着预训练/BERT的兴起,对BERT如何做蒸馏成为了热点。而推荐系统领域应用知识蒸馏,最主流的方式是大模型蒸馏小模型或者后置跨链路蒸馏前置链路[27]。归根结底都是性能和准确性的权衡。
预训练/迁移学习:也是得益于BERT的发展,目前推荐系统领域应用预训练/迁移学习的场景也变的非常多。例如:刘知远老师组的综述:基于预训练的推荐系统知识迁移综述[29],能够有效解决推荐系统中的数据稀疏问题。
Transfromers4Rec工作实际上也是受到Transfomers、BERT以及NLP开源社区的影响所产生的。不同领域之间互相影响当然也是件好事,例如NLP领域也经常借鉴CV领域的成果,例如残差网络、CNN等等。
总结
从上面的介绍,我们可以看到NLP研究进展如何深远的影响着推荐系统的研究。可以说很大程度上推荐系统的发展是在NLP的肩膀上前进的。
到目前为止,我们看到的大多是单向影响,即:起步较早的领域深度影响着新兴领域,那么是否存在反哺的现象呢?也算是本篇文章的一个遗留问题,例如:推荐系统社区是否有反哺NLP社区呢? 这个问题可能也等价于推荐系统是否有一些独创/开创性的研究,是已经或有可能潜在影响其他领域的研究?(可能是个知乎好问题)。
这个问题也很大,需要花一些时间去学习和积累才能感受到。以读者目前的浅薄认知而言,我觉得有,至少我认为推荐系统在工程架构方面的进展是前沿的,是领先其他领域的。比如:实时推理引擎如TF Serving那一套,最早是服务于大规模实时推荐系统的,但对NLP尤其是预训练模型做实时serving还是有帮助的,小规模场景开箱即用,大规模场景做TF Serving优化后,也能使用。还有比如推荐系统中算首创的工作协同过滤或特征交互的研究进展,经典的FM等,也能一定程度上启发NLP研究。还有比如搜索/推荐场景常用的多阶段pipeline,召回+粗排+精排,也经常用在对话系统中。更多的以后有机会可以一起探讨探讨。
下一期将介绍基于Transformers的序列推荐建模调研或者Transformers4Rec文章核心方法本身。下期分享见!
参考
[1] de Souza Pereira Moreira G, Rabhi S, Lee J M, et al. Transformers4Rec: Bridging the Gap between NLP and Sequential/Session-Based Recommendation[C]//Fifteenth ACM Conference on Recommender Systems. 2021: 143-153.
[2] Lin T, Wang Y, Liu X, et al. A Survey of Transformers[J]. arXiv preprint arXiv:2106.04554, 2021.
[3] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[4] State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow: https://github.com/huggingface/transformers
[5] Hui Fang, Danning Zhang, Yiheng Shu, and Guibing Guo. 2020. Deep Learning for Sequential Recommendation: Algorithms, Influential Factors, and Evaluations. ACM Transactions on Information Systems (TOIS) 39, 1 (2020), 1–42.
[6] 研究推荐系统要对NLP很了解吗?付鹏的回答:https://www.zhihu.com/question/317441966/answer/633112869
[7] 自然语言处理 NLP 的百年发展史, http://imgtec.eetrend.com/blog/2020/100052025.html
[8] 一文尽览推荐系统模型演变史
[9] Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. Session-based recommendations with recurrent neural networks. arXiv preprint arXiv:1511.06939 (2015).
[10] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
[11] Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1059-1068.
[12] Wu S, Tang Y, Zhu Y, et al. Session-based recommendation with graph neural networks[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 346-353.
[13] Transformer 在美团搜索排序中的实践: https://tech.meituan.com/2020/04/16/transformer-in-meituan.html
[14] Mihajlo Grbovic, Vladan Radosavljevic, Nemanja Djuric, Narayan Bhamidipati, Jaikit Savla, Varun Bhagwan, and Doug Sharp. 2015. E-commerce in your inbox: Product recommendations at scale. In Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining. 1809–1818.
[15] Jing Li, Pengjie Ren, Zhumin Chen, Zhaochun Ren, and Jun Ma. 2017. Neural Attentive Session-based Recommendation. arXiv:1711.04725 [cs.IR]
[16] Jun Xiao, Hao Ye, Xiangnan He, Hanwang Zhang, Fei Wu, and Tat-Seng Chua. Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks. arXiv:1708.04617 [cs.LG]
[17] Fuyu Lv, Taiwei Jin, Changlong Yu, Fei Sun, Quan Lin, Keping Yang, and Wilfred Ng. 2019. SDM: Sequential deep matching model for online large-scale recommender system. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2635–2643.
[18] Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management. 1441–1450.
[19] Qiu Z, Wu X, Gao J, et al. U-BERT: Pre-training User Representations for Improved Recommendation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(5): 4320-4327.
[20] Kang W C, Cheng D Z, Yao T, et al. Learning to Embed Categorical Features without Embedding Tables for Recommendation[C]//Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021: 840-850.
[21] Guo H, Chen B, Tang R, et al. An Embedding Learning Framework for Numerical Features in CTR Prediction[J]. arXiv preprint arXiv:2012.08986, 2020.
[22] Wu J, Wang X, Feng F, et al. Self-supervised graph learning for recommendation[C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2021: 726-735.
[23] KDD2021, Deep Learning on Graphs for Natural Language Processing: https://dlg4nlp.github.io/
[24] Gao T, Yao X, Chen D. SimCSE: Simple Contrastive Learning of Sentence Embeddings[J]. arXiv preprint arXiv:2104.08821, 2021.
[25] Zhou C, Ma J, Zhang J, et al. Contrastive learning for debiased candidate generation in large-scale recommender systems[C]//Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021: 3985-3995.
[26] Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network[J]. arXiv preprint arXiv:1503.02531, 2015.
[27] 张俊林,知识蒸馏在推荐系统的应用:https://zhuanlan.zhihu.com/p/143155437
[28] 张俊林,利用Contrastive Learning对抗数据噪声:对比学习在微博场景的实践,https://zhuanlan.zhihu.com/p/370782081
[29] Zeng Z, Xiao C, Yao Y, et al. Knowledge transfer via pre-training for recommendation: A review and prospect[J]. Frontiers in big Data, 2021, 4
[30] Wang C, Blei D M. Collaborative topic modeling for recommending scientific articles[C]//Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining. 2011: 448-456.
[31] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. the Journal of machine Learning research, 2003, 3: 993-1022.
[32] Bordes A, Usunier N, Garcia-Duran A, et al. Translating embeddings for modeling multi-relational data[J]. Advances in neural information processing systems, 2013, 26.
[33] Wang X, He X, Cao Y, et al. Kgat: Knowledge graph attention network for recommendation[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019: 950-958.
[34] Hongwei Wang, https://scholar.google.com/citations?user=3C__4wsAAAAJ&hl=zh-CN
[35] Grbovic M, Cheng H. Real-time personalization using embeddings for search ranking at airbnb[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 311-320.