论文速读:FAIR 最新 ViT 模型 改进多尺度 ViT --- Improved Multiscale Vision Transformers
Improved Multiscale Vision Transformers for Classification and Detection

Figure 1. Our Improved MViT is a multiscale transformer with state-of-the-art performance across three visual recognition tasks.
[pdf] [GitHub]
本文提出的多尺度 ViT (MViTv2) 首先延续了 MViTv1 的池化注意力模型,并在相对位置 embedding 上做了改进。其次,提出了 Hybrid window attention (Hwin),其实就是将池化注意力和窗口注意力进行有效结合。关于这点,很像另一篇工作提出的 Hybrid Local-Global ViT。另外本文的实验也很充分。
Abstract
In this paper, we study Multiscale Vision Transformers (MViT) as a unified architecture for image and video classification, as well as object detection.
We present an improved version of MViT that incorporates decomposed relative positional embeddings and residual pooling connections.
We instantiate this architecture in five sizes and evaluate it for ImageNet classification, COCO detection and Kinetics video recognition where it outperforms prior work.
We further compare MViTs’ pooling attention to window attention mechanisms where it outperforms the latter in accuracy/compute.
Without bells-and-whistles, MViT has state-of-the-art performance in 3 domains: 88.8% accuracy on ImageNet classification, 56.1 APbox on COCO object detection as well as 86.1% on Kinetics-400 video classification.
本文研究了多尺度 Vision Transformers (MViT) 作为一个统一的体系结构,进行图像和视频分类,以及目标检测。
本文提出了一个改进的 MViT 版本,它包含了分解的相对位置 embeddings 和残差池化(residual pooling)连接。
本文在五个尺度中实例化了这个架构,并评估了它在 ImageNet 分类、COCO 检测和 Kinetics 视频识别中的表现,在这些方面它优于之前的工作。
本文进一步比较了 MViT 池化注意力(pooling attention)与窗口注意力(window attention)机制,前者在准确性/计算方面的表现优于后者。
在没有附加的修饰模型的情况下,MViT 在 3 个领域具有最先进的性能:ImageNet 分类准确率为88.8%,COCO 对象检测准确率为 56.1,Kinetics-400 视频分类准确率为 86.1%。
1. Introduction
Designing architectures for different visual recognition tasks has been historically difficult and the most widely adopted ones have been the ones that combine simplicity and efficacy, e.g. VGGNet [67] and ResNet [37]. More recently Vision Transformers (ViT) [18] have shown promising performance and are rivaling convolutional neural networks (CNN) and a wide range of modifications have recently been proposed to apply them to different vision tasks [1, 2, 22, 55, 68, 74, 79, 91].
为不同的视觉识别任务设计架构一直以来都很困难,最广泛采用的是结合简单和有效性的架构,如VGGNet 和 ResNet。最近,Vision transformer (ViT) 显示出了良好的性能,可以与卷积神经网络(CNN) 相媲美。最近,人们提出了一系列改进方案,将其应用于不同的视觉任务。
While ViT [18] is popular in image classification, its usage for high-resolution object detection and space-time video understanding tasks remains challenging. The density of visual signals poses severe challenges in compute and memory requirements as these scale quadratically in complexity within the self-attention blocks of Transformerbased [77] models. The community has approached this burden with different strategies: Two popular ones are (1) local attention computation within a window [55] for object detection and (2) pooling attention that locally aggregates features before computing self-attention in video tasks [22].
The latter fuels Multiscale Vision Transformers (MViT) [22], an architecture that extends ViT in a simple way: instead of having a fixed resolution throughout the network, it has a feature hierarchy with multiple stages starting from high-resolution to low-resolution. MViT is designed for video tasks where it has state-of-the-art performance.
虽然 ViT 在图像分类中很受欢迎,但将其用于高分辨率目标检测和时空视频理解任务仍然具有挑战性。视觉信号的密度在计算和内存需求方面带来了严峻的挑战,因为这些信号在基于 transformer 模型的自注意块中复杂性呈二次方增长。社区已经用不同的策略来解决这个问题:两种常用的策略是 (1) 局部注意力,即在一个窗口内进行局部注意力计算,用于对象检测;(2) 池化注意力,即在视频任务中计算自注意之前,在局部聚集特征。
后者支持 Multiscale Vision transformer (MViT),这是一种以简单的方式扩展 ViT 的架构:它没有在整个网络中拥有固定的分辨率,而是拥有从高分辨率到低分辨率的多个阶段的特性层次结构。MViT 是为视频任务而设计的,它有最先进的性能。
In this paper, we develop two simple technical improvements to further increase its performance and study MViT as a single model family for visual recognition across 3 tasks: image classification, object detection and video classification, in order to understand if it can serve as a general vision backbone for spatial as well as spatiotemporal recognition tasks (see Fig. 1). Our empirical study leads to an improved MViT architecture and encompasses the following:
(i) We create strong baselines that improve pooling attention along two axes: (a) shift-invariant positional embeddings using decomposed location distances to inject position information in Transformer blocks; (b) a residual pooling connection to compensate the effect of pooling strides in attention computation. Our simple-yet-effective upgrades lead to significantly better results.
(ii) Using the improved structure of MViT, we employ a standard dense prediction framework: Mask R-CNN [36] with Feature Pyramid Networks (FPN) [53] and apply it to object detection and instance segmentation.
We study if MViT can process high-resolution visual input by using pooling attention to overcome the computation and memory cost involved. Our experiments suggest that pooling attention is more effective than local window attention mechanisms (e.g. Swin [55]). We further develop a simple-yet-effective Hybrid window attention scheme that can complement pooling attention for better accuracy/compute tradeoff.
(iii) We instantiate our architecture in five sizes of increasing complexity (width, depth, resolution) and report a practical training recipe for large multiscale transformers. The MViT variants are applied to image classification, object detection and video classification, with minimal modification, to study its purpose as a generic vision architecture.
本文开发了两项简单的技术改进,以进一步提高其性能,并将 MViT 作为一个单一的模型家族进行研究,用于跨 3 个任务的视觉识别:图像分类、目标检测和视频分类,以便理解它是否可以作为空间和时空识别任务的一般视觉支柱 (见图 1)。
改进的 MViT 架构包含以下内容:
(i) 创建强大的 baselines,沿着两个坐标轴的方向改善池化注意力:(a) 平移不变位置 embeddings,使用分解的位置距离在 Transformer block 中注入位置信息;(b) 一个残差池化(residual pooling)连接,用于补偿注意计算中池化跨距(pooling stride)的影响。
(ii) 利用改进的 MViT 结构,采用了一个标准的密集预测框架:Mask R-CNN [36] with Feature Pyramid Networks (FPN) [53],并将其应用于目标检测和实例分割。本文研究了 MViT 是否可以通过集中注意力来克服计算和内存成本来处理高分辨率的视觉输入。
实验表明池化注意力比局部窗口注意机制 (如 Swin[55]) 更有效。
本文进一步发展了一种简单而有效的混合窗口注意方案,它可以补充集中注意以获得更好的准确性/计算权衡。
(iii) 本文以五种日益复杂的尺寸 (宽度、深度、分辨率) 来实例化本文提出的架构,并报告了一个大型多尺度 transformer 的实际训练设置。
该 MViT 变体应用于图像分类、目标检测和视频分类,以最小的修改,以研究其作为通用视觉体系结构的目的。
Experiments reveal that our MViTs achieve 88.8% accuracy for ImageNet-1K classification, with pretraining on ImageNet-21K (and 86.3% without), as well as 56.1 APbox on COCO object detection using only Cascade Mask R-CNN [6]. For video classification tasks, MViT achieves unprecedented accuracies of 86.1% on Kinetics-400, 87.9% on Kinetics-600, 79.4% on Kinetics700, and 73.3% on Something-Something-v2. Our video code will be open-sourced in PyTorchVideo 1,2 [20, 21].
实验表明,本文的 MViTs 在 ImageNet-21K 上进行预处理后,对 ImageNet-1K 分类的准确率为88.8% (不进行预处理的准确率为 86.3%),在仅使用级联 Mask R-CNN[6] 进行 COCO 对象检测时,准确率为 56.1 APbox。对于视频分类任务,MViT 在 Kinetics-400 上达到了前所未有的准确率86.1%,在 Kinetics-600 上达到了 87.9%,在 Kinetics-700 上达到了 79.4%,在 Something-Something-v2 上达到了 73.3%。本文的视频代码将在 PyTorchVideo [facebookresearch/pytorchvideo: A deep learning library for video understanding research.] [https://github.com/facebookresearch/SlowFast] 中开源。
3. Revisiting Multiscale Vision Transformers
MViTv1 [22] 的关键思想是,在 ViT 中,为低层和高层的可视化建模构建不同的阶段,而不是单一尺度的块。MViT 缓慢地扩展了信道宽度 D,同时降低了从网络输入到输出阶段的分辨率 L (即序列长度)。
要在一个 Transformer block 内进行下采样,MViT 引入了池化注意力。给定输入 X ∈ R^{L×D},通过线性变换 W 和池化操作 P 得到 Q,K,V:

其中,池化操作将 Q 的尺度变换到 Q ∈ R^{L˜×D}。K,V 同理。所以,池化后的自注意力为:
![]()
池化注意力可以通过集中查询张量 Q 来降低 MViT 不同阶段之间的分辨率,并通过集中键 K 和值 V 张量来显著降低计算和内存复杂度。
更多 MViTv1 细节参考原文:
[22] Multiscale vision transformers. In Proc. ICCV, 2021.
4. Improved Multiscale Vision Transformers
4.1. Improved Pooling Attention
首先重新审视 MViT 对潜在改进的两个重要含义,并引入一些技术来理解和解决它们。
Decomposed relative position embedding
While MViT has shown promises in their power to model interactions between tokens, they focus on content, rather than structure. The space-time structure modeling relies solely on the “absolute” positional embedding to offer location information. This ignores the fundamental principle of shift-invariance in vision [47]. Namely, the way MViT models the interaction between two patches will change depending on their absolute position in images even if their relative positions stay unchanged. To address this issue, we incorporate relative positional embeddings [65], which only depend on the relative location distance between tokens into the pooled self-attention computation.
We encode the relative position between the two input elements, i and j, into positional embedding
, where p(i) and p(j) denote the spatial (or spatiotemporal) position of element i and j. 3 The pairwise encoding representation is then embedded into the self-attention module:
However, the number of possible embeddings
, p(j) scale in O(TW H), which can be expensive to compute. To reduce complexity, we decompose the distance computation between element i and j along the spatiotemporal axes:
where Rh , Rw, Rt are the positional embeddings along the height, width and temporal axes, and h(i), w(i), and t(i) denote the vertical, horizontal, and temporal position of token i, respectively. Note that Rt is optional and only required to support temporal dimension in the video case. In comparison, our decomposed embeddings reduce the number of learned embeddings to O(T + W + H), which can have a large effect for early-stage, high-resolution feature maps.

分解相对位置 embedding
虽然 MViT 在建模 token 之间的交互方面表现出了强大的能力,但它们关注的是内容,而不是结构。时空结构建模仅依靠绝对位置嵌入来提供位置信息。这忽略了视觉中位移不变性的基本原理。也就是说,即使两个 patch 的相对位置保持不变,MViT 对它们之间相互作用的建模方式也会根据它们在图像中的绝对位置而改变。为了解决这个问题,本文引入了相对位置 embedding,它只依赖于 token 之间的相对位置距离,并将其放入池化自注意计算中。
本文编码两个输入元素之间的相对位置,i 和 j,位置 embedding ![]() ,p(i) 和 p(j) 表示的空间 (或时空) 位置元素 i 和 j。然后成对编码表示被 embedded 到 self-attention 模块,如公式(3)。
,p(i) 和 p(j) 表示的空间 (或时空) 位置元素 i 和 j。然后成对编码表示被 embedded 到 self-attention 模块,如公式(3)。
然而,可能的 embedding ![]() 的个数为 O(TWH),计算复杂度较高。为了降低复杂度,本文将元素 i 和元素 j 沿时空轴的距离计算分解为(4)的表达形式。
的个数为 O(TWH),计算复杂度较高。为了降低复杂度,本文将元素 i 和元素 j 沿时空轴的距离计算分解为(4)的表达形式。
其中,R^h、R^w、R^t 分别是沿高度、宽度和时间轴的位置 embedding,h(i)、w(i)、t(i) 分别表示标记 i 的垂直、水平和时间位置。注意,在视频的情况下,R^t 是可选的,只有支持时间维度时才需要 R^t。相比之下,本文的分解 embedding 将学习 embedding 的数量减少到 O(T + W + H),这对于 early-stage、高分辨率的 feature map 有很大的影响。
Residual pooling connection
As demonstrated [22], pooling attention is very effective to reduce the computation complexity and memory requirements in attention blocks. MViTv1 has larger strides on K and V tensors than the stride of the Q tensors which is only downsampled if the resolution of the output sequence changes across stages. This motivates us to add the residual pooling connection with the (pooled) Q tensor to increase information flow and facilitate the training of pooling attention blocks in MViT.
We introduce a new residual pooling connection inside the attention blocks as shown in Fig. 2. Specifically, we add the pooled query tensor to the output sequence Z. So Eq. (2) is reformulated as:
Z := Attn (Q, K, V ) + Q. (5)
Note that the output sequence Z has the same length as the pooled query tensor Q.
The ablations in §6.2 and §5.3 shows that both the pooling operator (PQ) for query Q and the residual path are necessary for the proposed residual pooling connection. This change still enjoys the low-complexity attention computation with large strides in key and value pooling as adding the pooled query sequence in Eq. (5) comes at a low cost.
残差池化连接
如 MViTv1 所示,池化注意力对于降低注意块的计算复杂度和内存需求是非常有效的。MViTv1 在 K和 V 张量上的步幅比 Q 张量的步幅大,Q 张量的步幅只有在输出序列的分辨率在不同阶段发生变化时才下采样。这促使本文将残差池化连接添加到 (池化的) Q 张量上,以增加信息流,便于 MViT 中池化注意块的训练。

在注意块内部引入一种新的残差池化连接,如图 2 所示。具体来说,将池化的查询张量 Q 添加到输出序列 Z 中。因此,将式 (2) 重新表述为公式(5)
注意,输出序列 Z 与池化查询张量 Q 具有相同的长度。
§6.2 和 §5.3 (请参阅原文,本博客就偷懒不讲那么细了)中的消融表明,对于残差池连接,查询 Q 的池化操作 (P_Q) 和残差路径都是必要的。这种改变仍然具有低复杂度的注意计算,在 K 和 V 池化中有较大的跨步,因为在式 (5) 中添加池化查询序列的成本较低。
4.2. MViT for Object Detection
本节将描述如何将 MViT backbone 应用于对象检测和实例分割任务。
FPN integration
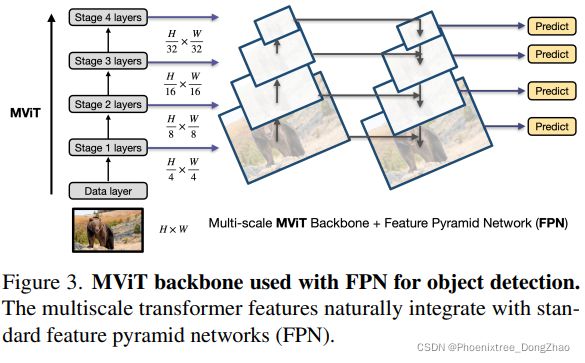
The hierarchical structure of MViT produces multiscale feature maps in four stages, and therefore naturally integrates into Feature Pyramid Networks (FPN) [53] for object detection tasks, as shown in Fig. 3. The top-down pyramid with lateral connections in FPN constructs semantically strong feature maps for MViT at all scales. By using FPN with the MViT backbone, we apply it to different detection architectures (e.g. Mask R-CNN [36]).
与特征金字塔网络集成
MViT 的层次结构产生了四个阶段的多尺度特征图,因此自然地集成到特征金字塔网络 (Feature Pyramid Networks, FPN) [53]中进行目标检测任务,如图 3 所示。FPN 中带有横向连接的自顶向下金字塔为 MViT 在所有尺度上构建了语义强特征映射。通过使用 FPN 和 MViT backbone,本文将其应用于不同的检测架构 (例如 Mask R-CNN[36])。
Hybrid window attention
The self-attention in Transformers has quadratic complexity w.r.t. the number of tokens. This issue is more exacerbated for object detection as it typically requires high-resolution inputs and feature maps. In this paper, we study two ways to significantly reduce this compute and memory complexity: First, the pooling attention designed in attention blocks of MViT. Second, window attention used as a technique to reduce computation for object detection in Swin [55].
Pooling attention and window attention both control the complexity of self-attention by reducing the size of query, key and value tensors when computing self-attention. Their intrinsic nature however is different: Pooling attention pools features by downsampling them via local aggregation, but keeps a global self-attention computation, while window attention keeps the resolution of tensors but performs selfattention locally by dividing the input (patchified tokens) into non-overlapping windows and then only compute local self-attention within each window. The intrinsic difference of the two approaches motivates us to study if they could perform complementary in object detection tasks.
Default window attention only performs local selfattention within windows, thus lacking connections across windows. Different from Swin [55], which uses shifted windows to mitigate this issue, we propose a simple Hybrid window attention (Hwin) design to add cross-window connections. Hwin computes local attention within a window in all but the last blocks of the last three stages that feed into FPN. In this way, the input feature maps to FPN contain global information. The ablation in §5.3 shows that this simple Hwin performs consistently better than Swin [55] on image classification and object detection tasks. Further, we will show that combining pooling attention and Hwin achieves the best performance for object detection.
混合窗口注意力
Transformer 中的自注意的复杂度为 token 数量的 2 次方。这个问题在对象检测中更加严重,因为它通常需要高分辨率的输入和特征图。本文研究了两种显著降低该计算和内存复杂度的方法:一是将注意力集中在 MViT 的注意力块中;其次,同 Swin [55],窗口注意作为一种减少对象检测计算的技术。
池化注意和窗口注意都通过减少计算自注意时 Q、K 和 V 张量的大小来控制自注意的复杂度。然而,它们的内在本质是不同的:池化注意池特征是通过局部聚合进行下采样,但保持全局自注意计算,而窗口注意保持张量的分辨率,但通过将输入 (patchified tokens) 划分为不重叠的窗口,在每个窗口内只计算局部自注意,从而实现局部自注意。这两种方法的内在差异促使本文去研究它们在物体检测任务中是否可以互补。
默认窗口注意只在窗口内执行局部自注意,因此缺少跨窗口的连接。不同于 Swin[55],它使用移位的窗口来缓解这个问题,本文提出了一个简单的 Hybrid 窗口注意 (Hwin) 设计来添加跨窗口连接。Hwin 计算一个窗口内的局部注意力,除了最后三个阶段的最后一个块,并将其输入 FPN。通过这种方式,输入特征映射到 FPN 包含全局信息。§5.3 中的消融表明,这个简单的 Hwin 在图像分类和目标检测任务上始终优于Swin[55]。此外,池化注意力和 Hwin 结合在一起可以获得最佳的目标检测性能。
Positional embeddings in detection
Different from ImageNet classification where the input is a crop of fixed resolution (e.g. 224×224), object detection typically encompasses inputs of varying size in training. For the positional embeddings in MViT (either absolute or relative), we first initialize the parameters from the ImageNet pre-training weights corresponding to positional embeddings with 224×224 input size and then interpolate them to the respective sizes for object detection training.
定位嵌入检测
与 ImageNet 分类不同,ImageNet 分类的输入是一组固定的分辨率 (例如 224×224),目标检测通常在训练中包含不同大小的输入。对于 MViT 中的位置嵌入 (无论是绝对的还是相对的),首先用 224×224 输入尺寸的位置嵌入对应的 ImageNet 预训练权值初始化参数,然后将它们插值到各自的尺寸用于目标检测训练。
4.3. MViT for Video Recognition
MViT can be easily adopted for video recognition tasks (e.g. the Kinetics dataset) similar to MViTv1 [22] as the upgraded modules in §4.1 generalize to the spatiotemporal domain. While MViTv1 only focuses on the training-fromscratch setting on Kinetics, in this work, we also study the (large) effect of pre-training from ImageNet datasets.
MViT 可以很容易地用于视频识别任务 (例如动力学数据集),类似于 MViTv1[22],因为 §4.1 中升级的模块可以推广到时空域。而 MViTv1 只专注于 Kinetics 的从头开始的训练设置,在本工作中,研究了从 ImageNet 数据集进行预训练的 (大) 效应。
Initialization from pre-trained MViT
Compared to the image-based MViT, there are only three differences for video-based MViT: 1) the projection layer in the patchification stem needs to project the input into space-time cubes instead of 2D patches; 2) the pooling operators now pool spatiotemporal feature maps; 3) relative positional embeddings reference space-time locations.
As the projection layer and pooling operators in 1) and 2) are instantiated by convolutional layers by default 4 , we use an inflation initialization as for CNNs [8, 25]. Specifically, we initialize the conv filters for the center frame with the weights from the 2D conv layers in pre-trained models and initialize other weights as zero. For 3), we capitalize on our decomposed relative positional embeddings in Eq. 4, and simply initialize the spatial embeddings from pre-trained weights and the temporal embedding as zero.
从预训练的 MViT 初始化
与基于图像的 MViT 相比,基于视频的 MViT 只有三个不同之处:
1) patch化干中的投影层需要将输入投影到时空立方体中,而不是二维的 patch;
2) 池化算子将时空特征图进行池化;
3) 相对位置 embedding 参考时空位置。
由于1) 和 2) 中的投影层和池化操作符在默认情况下是由卷积层实例化的,所以本文对 CNN 使用膨胀初始化(inflation initialization) [8,25]。具体地说,本文用预训练模型中 2D 卷积层的权值初始化中心帧的卷积滤波器,并将其他权值初始化为零。对于 3),本文利用 Eq. 4 中分解的相对位置 embedding,并简单地将预先训练的权值和时间 embedding 初始化为零。
4.4. MViT Architecture Variants
We build several MViT variants with different number of parameters and FLOPs as shown in Table 1, in order to have a fair comparison with other vision transformer works [9,55, 73, 82]. Specifically, we design five variants (Tiny, Small, Base, Large and Huge) for MViT by changing the base channel dimension, the number of blocks in each stage and the number of heads in the blocks. Note that we use a smaller number of heads to improve runtime, as more heads lead to slower runtime but have no effect on FLOPs and Parameters.
Following the pooling attention design in MViT [22], we employ Key and Value pooling in all pooling attention blocks by default and the pooling stride is set to 4 in the first stage and adaptively decays stride w.r.t resolution across stages.
本文构建了几个具有不同数量参数和 FLOPs 的 MViT 变体,如表 1 所示,以便与其他 vision transformer 作品进行公平的比较。具体来说,本文为 MViT 设计了 5 个变体 (Tiny, Small, Base, Large和Huge),通过改变基本通道尺寸,每个阶段的块数量和块中的头数量。
注意,本文使用更少的头来改善运行时,因为更多的头会导致更慢的运行时,但对 FLOPs 和参数没有影响。
遵循 MViT[22] 中的池化注意力设计,本文在所有集中注意力块中默认使用 Key 和 Value 池化,并在第一 stage 将池化注意力的步幅设置为 4,并且对于后续 stages,根据分辨率来自适应衰减步幅。
