神经网络基础与反向传播
文章目录
- 一 生物神经网络到人工神经网络
- 二 单层感知机网络
-
- 2.1 感知机模型
- 2.2 激活函数
- 2.3 感知机分类图示
- 2.4 感知机的学习策略
- 三 多层神经网络
- 四 反向传播学习算法(Back Propagation)
-
- 3.1 从输出层到隐含层
- 3.2 从隐含层到输入层(隐含层)
- 3.3 简单的反向传播例子
- 3.4 BP算法的优化
-
-
- 3.4.1 规格化
- 3.4.2 隐含层单元数
- 3.4.3 权值初始化
- 3.4.4 学习率
-
- 参考
一 生物神经网络到人工神经网络
人工神经网络的构筑理念是受到生物(人或其他动物)神经网络功能的运作启发而产生的。神经元大致可以分为:树突、突触、细胞体和轴突。
在生物神经网络中,每个神经元与其他神经元相连,当它兴奋时,就会向相连的神经元发送化学物质,从而改变这些神经元的电位;如果某神经元的电位超过了一个阈值,它就会被激活,即"兴奋"起来,向其他神经元发送化学物质。
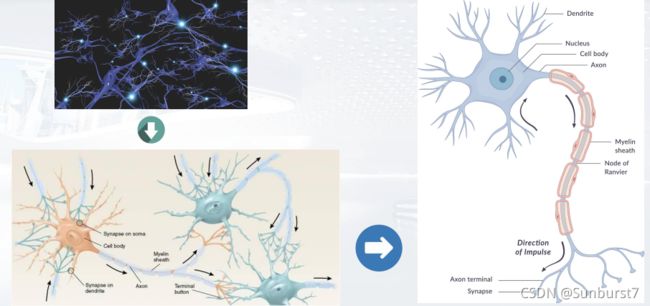
人工神经网络(artificial neural network,ANN),简称神经网络(neural network,NN),是一种模仿生物神经网络的结构和功能的数学模型或计算模型。神经网络由大量的人工神经元联结进行计算,【2】是:
- 模拟大脑学习过程的计算模型
- 具有神经元的基本特征以及类似大脑的神经元的连接。
神经网络是由简单处理单元组成的大规模并行分布式处理器,具有存储实验知识并使其可用的自然倾向。它在两个方面与大脑相似:
- 知识的获取方式是网络通过一个学习的过程在环境中获取的
- 神经元间连接强度被称为突触权重,用来储存获得的知识
- 在学习过程中,为了在训练中正确地为特定的学习任务建模,需要对权值进行了修改
神经网络的发展历史:
-
Frank Rosenblatt,(康奈尔大学的心理学家)在1958年,在《 纽约时报 (New York Times)》上发表文 章《Electronic ‘Brain’ Teaches Itself.》,正式把算 法取名为“感知器”。
它有400个光传感器,它们一起充当视网膜,将 信息传递给大约1000个“神经元” ,这些神经元进行处理并输出单一信息。

-
马文·明斯基(人工智能之父” (Marvin Minsky) 1970图灵奖获得者)1969年,Minsky 和Papert所著的《Perceptron》一书出版, 从数学角度证明了关于单层感知器的计算具有根本的局限性, 指出感知器的处理能力有限,甚至连XOR这样的问题也不能解决。神经网络进入了萧条期
-
杰弗里·辛顿(“神经网络之父”(Geoffrey Hinton) 2019图灵奖获得者)1986年在多伦多大学的辛顿实现了一种叫做反向传播的 原理来让神经网络从他们的错误中学习
二 单层感知机网络
2.1 感知机模型
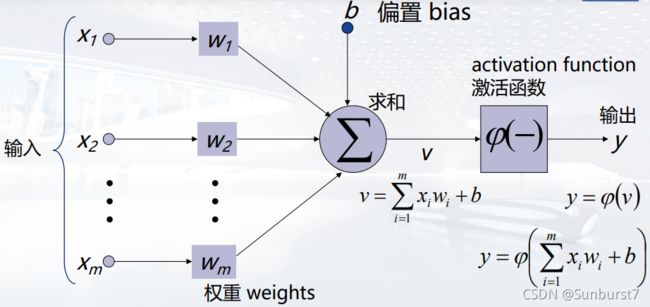
感知机(Perceptron)或神经元(Neuron)是神经网络中最基本的信息处理单元,它模拟生物神经元,由以下几个部分组成:
-
输入一组特征向量: x 1 , x 2 , . . . x m x_1,x_2,...x_m x1,x2,...xm
-
一组突触或连接,每根连接都会赋予一个权重: W 1 , W 2 , . . . , W m W_1,W_2,...,W_m W1,W2,...,Wm
-
一个偏置(bias): b b b,偏置增加了感知机的灵活性
-
一个加法器函数(线性组合器),计算通过突触输入的加权值的和: v = ∑ i = 1 m x i w i + b v=\sum_{i=1}^{m}x_iw_i+b v=∑i=1mxiwi+b
-
激活函数(压实函数),用于限制神经元输出的振幅: φ ( v ) \varphi(v) φ(v)
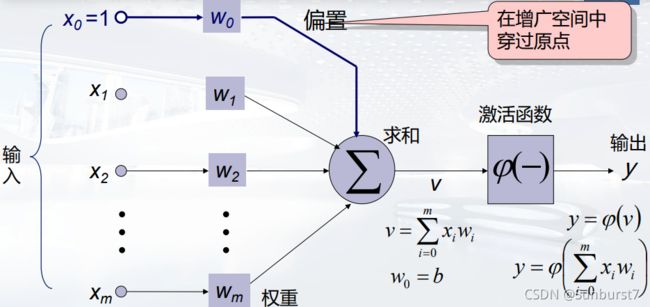
为了保持加权和的形式统一我们可以添加一个输入 x 0 = 1 x_0=1 x0=1,权值 W 0 = b W_0=b W0=b,形成新的输入特征向量在特征增广空间中穿过原点。
2.2 激活函数




2.3 感知机分类图示
假设我们有训练集分为两种类型: T 1 ∈ C 1 和 T 2 ∈ C 2 T_1\in C_1和T_2\in C_2 T1∈C1和T2∈C2。其中,样本表示为 x = ( x 0 , x 1 , x 2 , . . . , x m ) T , x 0 = 1 ( 偏 置 ) \textbf{x}=(x_0,x_1,x_2,...,x_m)^T,x_0=1(偏置) x=(x0,x1,x2,...,xm)T,x0=1(偏置),假设T1与T2是线性可分的(linearly separable),能否给出一个感知机将数据正确划分?

我们使用单层感知机模型来解决这个问题,激活函数选择符号函数。输出1为1类正例,输出-1为2类负例。

假设数据的维数是二维 x = ( x 1 , x 2 ) \textbf{x}=(x_1,x_2) x=(x1,x2),有个测试数据真实标签为1类,下图的这个 W W W向量能够正确的分类,因为计算激活函数的值为1。

但下图的 W W W却不能正确分类

如何更新w让感知机变得可行?应该让 W W W加上一个 Δ W = a x \Delta W=a\textbf{x} ΔW=ax使得 ( w + Δ W ) T x ′ > 0 (w+\Delta W)^Tx^{'}>0 (w+ΔW)Tx′>0

对于分类结果的真实类别与预测类别一共有以下四种情况:
| 真实类别 | 预测类别 | 差 |
|---|---|---|
| 1 | -1 | 2 |
| -1 | 1 | -2 |
| 1 | 1 | 0 |
| -1 | -1 | 0 |
因此我们设计一种误差 r = d − y r=d-y r=d−y:
- = + 2 =+2 =+2,把正例错分成负例,假负例
- = − 2 =-2 =−2,把负例错分成正例,假正例
- = 0 =0 =0,预测正确
再配上学习率 η \eta η,来构造一个标准化 Δ W = η r x \Delta W=\eta r\textbf{x} ΔW=ηrx,用于更新激活函数中的 W W W
2.4 感知机的学习策略
对于2.3节的问题,假设我们的误差函数是均方误差的形式:

在m=2时,也就是每个数据有两个特征时,可以画出近似的误差函数图像:

我们的目标是减小误差,直观的来说就是“下山”,因此学习策略采用梯度下降法:
对于任意一个函数 f ( x ) = f ( w 1 , w 2 , . . , w m ) f(\textbf{x})=f(w_1,w_2,..,w_m) f(x)=f(w1,w2,..,wm),定义一个梯度算子 ∇ f = ( δ f δ w 1 , δ f δ w 2 , . . . δ f δ w n ) \nabla f=(\frac{\delta f}{\delta w_1},\frac{\delta f}{\delta w_2},...\frac{\delta f}{\delta w_n}) ∇f=(δw1δf,δw2δf,...δwnδf), Δ x = ( d w 1 , d w 2 , . . . , d w n ) T \Delta \textbf{x}=(dw_1,dw_2,...,dw_n)^T Δx=(dw1,dw2,...,dwn)T。
则f的全导数 d f = < ∇ f , Δ x > df=<\nabla f,\Delta \textbf{x}> df=<∇f,Δx>
梯度(向量)表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
为了最小化误差函数的值,我们选择向负梯度的方向学习 Δ W = − η ∇ f \Delta W=-\eta \nabla f ΔW=−η∇f


三 多层神经网络
上图显示的是一个简单的异或(XOR)问题三层神经网络,这个网络由一个输入层,一个隐含层(它的输入与输出并不为外部环境直接所见)和一个输出层组成。它们由可修正的权值相连,除了连接输入单元,每个单元还连接者一个偏置(bias),单元也被称为神经元(neuron),我们要利用这种网络来做模式识别,输入单元提供特征量,输出单元激发的信号成为用来分类的判别函数的值。
通过一个最简单的非线性问题了解多层神经网络——异或(XOR)问题:给定两个特征(x1,x2),输出他们异或的值。
每个二维输入向量都提供给输入层,每个输入神经元的输出结果就是对应的分量,隐含层单元对它的各个输入进行加权求和运算而形成标量的净激活(net activation简称net),为了简单,我们增广输入向量(附加一个特征值 x 0 = 1 x_0=1 x0=1)和权值( w 0 = b i a s w_0=bias w0=bias),因此其形式定义:
n e t j = ∑ i = 1 d x i w j i + w j 0 = ∑ i = 0 d x i w j i net_j=\sum_{i=1}^dx_iw_{ji}+w_{j0}=\sum_{i=0}^dx_iw_{ji} netj=i=1∑dxiwji+wj0=i=0∑dxiwji
下标i是输入层单元的索引,j是输出层单元的索引, w j i w_{ji} wji表示输入层第i个神经元到隐含层第j个神经元的权值。每个隐含层单元激发出一个输出分量,这个分量是将净激活传入一个激活函数中 f ( n e t ) f(net) f(net),该问题中定义激活函数为符号函数(sign):
f ( n e t ) = s i g n ( n e t ) f(net)=sign(net) f(net)=sign(net)
每个输出单元同隐含层单元计算它的净激活:
n e t k = ∑ j = 1 n y j w k j + w k 0 = ∑ j = 0 n y i w k j net_k=\sum_{j=1}^ny_jw_{kj}+w_{k0}=\sum_{j=0}^ny_iw_{kj} netk=j=1∑nyjwkj+wk0=j=0∑nyiwkj
这样最后的输出 z k = f ( n e t k ) z_k=f(net_k) zk=f(netk),我们用这个输出来解决异或问题。容易验证,上述给定权值的三层网络的确可以解决异或(XOR)问题。它计算判决边界为 x1+x2+0.5 = 0。另一个隐含层单元的判别边界x1+x2-1.5=0。只有y1与y2都等于1,最终z才激发为+1。
四 反向传播学习算法(Back Propagation)
对于一个三层的神经网络,可以很直接的根据其误差,找到隐含层与输出层的权值更新,这与线性LMS算法类型,可是如何训练从输入层到隐函层的权值呢?如果一个隐含层单元的“适当”输出对每种模式都是已知的,那么输入层到隐含层的权值就可以调节到很接近它。BP算法允许我们对每个隐含层单元计算有效误差,并由此推导出一个输入层到隐含层权值的学习规则
神经网络中有两种基本的学习模式:前馈与反向传播。
- 前馈:在网络间传递信号,然后在输出层得到输出。
- 反向传播:对于一个有监督学习,通过修改网络中每个节点的连接权重来使实际输出更接近真实值。
对于一个d-n-c的全连接三层网络:
-
一个d维的输入向量被提供给输入层,每个输入单元发送它对应的分量 x i x_i xi
-
n个隐含层单元的每个都计算它的净激活能 n e t j net_j netj,他是输入层和隐含层单元权值的内积
-
隐含层单元的输出是 y i = f ( n e t j ) y_i=f(net_j) yi=f(netj),f是一个激活函数,这里选择Sigmod函数。
-
输出层单元类似于隐含层,计算净激活能 n e t k net_k netk,网络的最终信号 z k = f ( n e t k ) z_k=f(net_k) zk=f(netk)
-
η \eta η是学习率。
3.1 从输出层到隐含层
根据期望输出值 t k t_k tk与实际输出值 z k z_k zk,我们先定义一个误差函数(LossFunction):
J ( w ) = 1 2 ∑ k = 1 c ( t k − z k ) 2 = 1 2 ∣ ∣ t − z ∣ ∣ 2 J(w)=\frac{1}{2}\sum_{k=1}^c(t_k-z_k)^2=\frac{1}{2}||\textbf{t}-\textbf{z}||^2 J(w)=21k=1∑c(tk−zk)2=21∣∣t−z∣∣2
反向传播学习规则是基于梯度下降法的。权值向量首先被初始化为随机值,然后向误差减小的方向调整:
Δ w = − η ϑ J ϑ w w ( m + 1 ) = w ( m ) + Δ w \Delta\textbf{w}=-\eta\frac{\vartheta J}{\vartheta \textbf{w}}\\ \textbf{w}(m+1)=\textbf{w}(m)+\Delta\textbf{w} Δw=−ηϑwϑJw(m+1)=w(m)+Δw
针对上图的三层网络,考虑一个隐含层神经元到一个输出层神经元的权值分量 w k j w_{kj} wkj,利用链式求导法则:
ϑ J ϑ w k j = ϑ J ϑ n e t k ϑ n e t k ϑ w k j = − δ k ϑ n e t k ϑ w k j \frac{\vartheta J}{\vartheta w_{kj}}=\frac{\vartheta J}{\vartheta net_k}\frac{\vartheta net_k}{\vartheta w_{kj}}=-\delta_k\frac{\vartheta net_k}{\vartheta w_{kj}} ϑwkjϑJ=ϑnetkϑJϑwkjϑnetk=−δkϑwkjϑnetk
其中单元k的敏感度 δ k \delta_k δk定义为误差关于输出层净激活能的偏导,而误差又与激活函数的值直接相关:
δ k = − ϑ J ϑ n e t k = − ϑ J ϑ z k ϑ z k ϑ n e t k = ( t k − z k ) f ′ ( n e t k ) \delta_k=-\frac{\vartheta J}{\vartheta net_k}=-\frac{\vartheta J}{\vartheta z_k}\frac{\vartheta z_k}{\vartheta net_k}=(t_k-z_k)f'(net_k) δk=−ϑnetkϑJ=−ϑzkϑJϑnetkϑzk=(tk−zk)f′(netk)
(8)式的最后一项由 n e t k = ∑ J = 1 n y J w K J + w K 0 = ∑ J = 0 n y I w K J net_k=\sum_{J=1}^ny_Jw_{KJ}+w_{K0}=\sum_{J=0}^ny_Iw_{KJ} netk=∑J=1nyJwKJ+wK0=∑J=0nyIwKJ,对于具体的一个隐含层神经元 J = j J=j J=j与该神经元到输出层的权值 w k j w_{kj} wkj
ϑ n e t k ϑ w k j = y j \frac{\vartheta net_k}{\vartheta w_{kj}}=y_j ϑwkjϑnetk=yj
因此一个隐含层神经元( z k , t k , n e t k z_k,t_k,net_k zk,tk,netk)到一个输出层神经元( y j y_j yj)的权值( w k j w_{kj} wkj)更新规则:
Δ w k j = η δ k y i = η ( t k − z k ) f ′ ( n e t k ) y i \Delta w_{kj}=\eta\delta_ky_i=\eta(t_k-z_k)f'(net_k)y_i Δwkj=ηδkyi=η(tk−zk)f′(netk)yi
3.2 从隐含层到输入层(隐含层)
从输入层到隐含层的权值学习规则不太一样,对误差求关于任意一个输入层到隐含层权值( w j i w_{ji} wji)的偏导:
ϑ J ϑ w j i = ϑ J ϑ y i ϑ y i ϑ n e t j ϑ n e t j ϑ w j i = ϑ J ϑ y i f ′ ( n e t j ) x i \frac{\vartheta J}{\vartheta w_{ji}}=\frac{\vartheta J}{\vartheta y_i}\frac{\vartheta y_i}{\vartheta net_j}\frac{\vartheta net_j}{\vartheta w_{ji}}=\frac{\vartheta J}{\vartheta y_i}f'(net_j)x_i ϑwjiϑJ=ϑyiϑJϑnetjϑyiϑwjiϑnetj=ϑyiϑJf′(netj)xi
而对于第一项,因为从隐含层到输出层是全连接,一个具体的输出 y i y_i yi输入到了所有的输出层中,要对所有的输出层误差求和再偏导: z k = f ( n e t k ) 、 n e t k = ∑ j = 0 n w k j y j z_k=f(net_k)、net_k=\sum_{j=0}^nw_{kj}y_j zk=f(netk)、netk=∑j=0nwkjyj
ϑ J ϑ y i = ϑ ϑ y i [ 1 2 ∑ k = 1 c ( t k − z k ) 2 ] = − ∑ k = 1 c ( t k − z k ) ϑ z k ϑ y i = − ∑ k = 1 c ( t k − z k ) ϑ z k ϑ n e t k ϑ n e t k ϑ y i = − ∑ k = 1 c ( t k − z k ) f ′ ( n e t k ) w k j = − f ′ ( n e t j ) ∑ k = 1 c w k j δ k \begin{aligned} \frac{\vartheta J}{\vartheta y_i}&=\frac{\vartheta }{\vartheta y_i}[\frac{1}{2}\sum_{k=1}^c(t_k-z_k)^2]\\ &=-\sum_{k=1}^c(t_k-z_k)\frac{\vartheta z_k}{\vartheta y_i}\\ &=-\sum_{k=1}^c(t_k-z_k)\frac{\vartheta z_k}{\vartheta net_k}\frac{\vartheta net_k}{\vartheta y_i}\\ &=-\sum_{k=1}^c(t_k-z_k)f'(net_k)w_{kj}\\ &=-f'(net_j)\sum_{k=1}^cw_{kj}\delta_k \end{aligned} ϑyiϑJ=ϑyiϑ[21k=1∑c(tk−zk)2]=−k=1∑c(tk−zk)ϑyiϑzk=−k=1∑c(tk−zk)ϑnetkϑzkϑyiϑnetk=−k=1∑c(tk−zk)f′(netk)wkj=−f′(netj)k=1∑cwkjδk
类似的定义一个隐含层单元的敏感度为各输出单元的敏感度的加权和,权重为隐含层到输出层的权重 w k j w_{kj} wkj,因此输入层到隐含层的学习策略是:
Δ w j i = η x i δ j = η [ ∑ k = 1 c w k j δ k ] f ′ ( n e t j ) x i \Delta w_{ji}=\eta x_i\delta_j=\eta[\sum_{k=1}^cw_{kj}\delta_k]f'(net_j)x_i Δwji=ηxiδj=η[k=1∑cwkjδk]f′(netj)xi
(9)式与(16)式共同给出了反向传播算法,确切的说是误差反向传播算法。
3.3 简单的反向传播例子
下面通过一个简单三层神经元的例子来直观的感受BP算法的过程,b代表偏置,激活函数选择sigmod函数:

-
计算h1的输入: h 1 = w 1 ∗ i 1 + w 2 ∗ i 2 + b 1 ∗ 1 = 0.3775 h_1=w_1*i_1+w_2*i_2+b_1*1=0.3775 h1=w1∗i1+w2∗i2+b1∗1=0.3775
-
计算h1的输出值: y 1 = s i g m o d ( 0.3775 ) = 1 1 + e − 0.3775 = 0.59326992 y_1=sigmod(0.3775)=\frac{1}{1+e^{-0.3775}}=0.59326992 y1=sigmod(0.3775)=1+e−0.37751=0.59326992
-
同理计算h2的输出值y2 = 0.596884378。
-
o1的输入值: o 1 = w 5 ∗ y 1 + w 6 ∗ y 2 + b 2 ∗ 1 = 1.105905967 o_1=w_5*y_1+w_6*y_2+b_2*1=1.105905967 o1=w5∗y1+w6∗y2+b2∗1=1.105905967
o1的输出值为sigmod(1.105905867)=0.75136507
-
同理o2的输出值为0.772928465
定义Loss function(损失函数)为平方误差,计算总误差:

求总误差关于 w 5 w_5 w5的梯度:
-

-
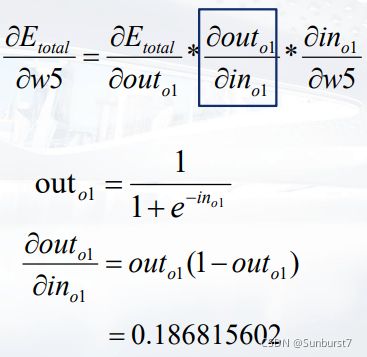
-

因此总误差关于w5权重的梯度方向为:

取学习率为0.5,w5的变化率:
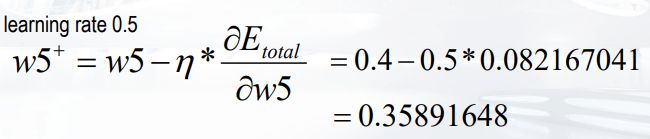
3.4 BP算法的优化
3.4.1 规格化
假设我们使用2-输入的网络,利用质量(以克为单位)和长度(以米为单位)特征来对鱼进行分类,这种表示法对于一个神经网络分类器具有严重的不足:质量与长度的度量不在一个数量级上,从而在训练的过程中,网络将更多的根据质量输入来调节权值。我们不希望我们的分类器仅根据某一种做出判断,仅仅因为它们在数值表示上不同。
为了避免这样的问题,输入模式必须重新进行尺度变换(scaling),常见的尺度变换有归一化:将所有输入标签全部映射在[0,1]区间上。
3.4.2 隐含层单元数
输入层与输出层单元数分别由输入向量的维数与类别决定,隐含层单元数 n H n_H nH,决定了网络的表达能力——从而决定了判别边界的复杂度。如果模式较容易分开或线性可分,那么仅需要较少的隐单元;相反需要更多的隐单元。
隐含层单元的选择应该适中:
- 隐含层单元过大:训练误差率可能变得很小,但可能过拟合训练集,使得测试集的误差很大
- 隐含层单元过小:网络将不具备足够的自由度以较好的拟合训练数据。
一个经验规则是选取隐单元的个数,使得网络中总权重数大约为n/10(n为训练样本数)
3.4.3 权值初始化
我们不能将权值初始化为0,否则学习过程将不可能开始。相关的知识可以看【3】
3.4.4 学习率
原则上,学习率足够小以保证收敛,那么它的值仅仅决定网络中到达最小误差的速度。
- 学习率过小:可以保证收敛到最小误差,但训练速度太慢
- 学习率过大:可能系统会震荡,可能系统会发散无法收敛。
参考
【1】模式分类第二版
【2】[ 神经网络详解(基本完成)_大土的博客-CSDN博客_神经网络(https://blog.csdn.net/as091313/article/details/79080583)
【3】[啃一啃神经网络——权重初始化 - 知乎 (zhihu.com(https://zhuanlan.zhihu.com/p/102708578)