Pytorch机器学习(三)——VOC数据集转换为YOLO数据集
Pytorch机器学习(三)——VOC数据集转换为YOLO数据集
目录
Pytorch机器学习(三)——VOC数据集转换为YOLO数据集
前言
一、yolo格式
二、代码
总结
前言
本文为利用pytorch官方提供的datasets读取VOC数据集的方法,来处理数据集并把其转化为yolo的格式。如果对datasets读取VOC数据集的方法不熟悉,可以看上篇文章
Pytorch机器学习(二)——利用torchvision.datasets分析,处理,可视化VOC数据集
其次,本文的代码是参考了b站博主的代码,做了一定的改进和修改。
霹雳吧啦Wz b站主页
一、yolo格式
我们先来看看用于yolo网络训练的格式长什么样

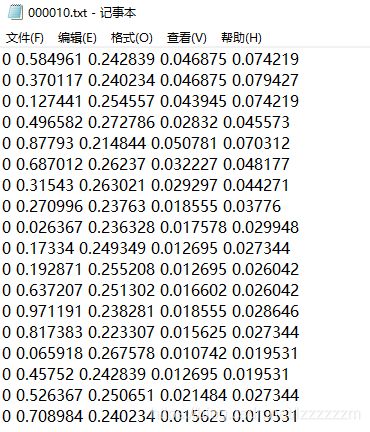
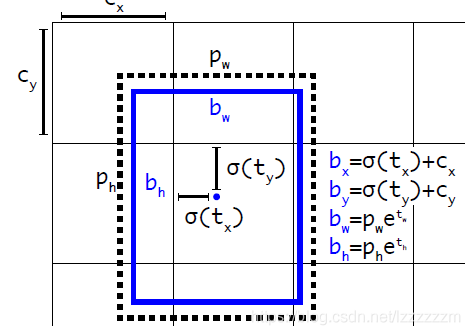
其中images中为原始图片,labels中对应标签的信息,其中标签的信息,相对于VOC原始的信息有一点不样,yolo格式里的boundingbox的信息为中心坐标x,y和长宽,而VOC格式里的boundingbox的信息为左上角和右上角的坐标。
二、代码
代码部分,我写的注释比较多,如果还有不理解的地方,可以来私信我。这里说一下,怎么使用这个代码。
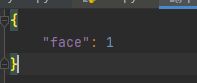
1.我们首先需要一个json格式的目录,放在和VOCdevkit中,其内容为标签的编号,我这里只有一个face,注意,要从1开始,0是背景。

2.只需要按需要修改前面几个地址,和voc的版本和年份以及voc_val_txt_path 中的val.txt即可,因为我发现有的数据集是test.txt有的是val.txt,可以自己去看看。
import torchvision.datasets as datasets
from tqdm import tqdm
import shutil
import json
import os
# json和voc数据集目录
label_json_path = './data/pascal_voc_classes.json' # VOC中json目录的
voc_root = './data/VOCdevkit' # VOC数据集地址,按需修改,默认在根目录
voc_version = 'VOC2012' # VOC版本,需要修改!!
voc_year = "2012" # VOC年份,需要修改!!
# 拼接出voc的data目录
voc_images_path = os.path.join(voc_root, voc_version, "JPEGImages")
voc_xml_path = os.path.join(voc_root, voc_version, "Annotations")
voc_train_txt_path = os.path.join(voc_root, voc_version, "ImageSets", "Main", "train.txt")
voc_val_txt_path = os.path.join(voc_root, voc_version, "ImageSets", "Main", "val.txt") # 注意!这里有的数据集是val.txt,有的是test.txt,按需修改!!
# 拼接出保存的目录结构
save_path_root = './yolo_datasets'
save_path_train = os.path.join(save_path_root, 'train')
save_path_train_images = os.path.join(save_path_train, 'images')
save_path_train_labels = os.path.join(save_path_train, 'labels')
save_path_val = os.path.join(save_path_root, 'val')
save_path_val_images = os.path.join(save_path_val, 'images')
save_path_val_labels = os.path.join(save_path_val, 'labels')
save_path = [save_path_root, save_path_train, save_path_train_images, save_path_train_labels, save_path_val, save_path_val_images, save_path_val_labels]
# 检测并创建需要的文件夹
def check_path(save_path):
if not os.path.exists(save_path):
os.mkdir(save_path)
print("making {} file".format(save_path))
# 生成json 对应.name文件
def create_class_names(class_dict: dict):
keys = class_dict.keys()
with open("./data/my_data_label.names", "w") as w:
for index, k in enumerate(keys):
if index + 1 == len(keys):
w.write(k)
else:
w.write(k + "\n")
def voc_translate_yolo(file_name, xml_object, class_dict, type):
"""
将对应xml文件信息转为yolo中使用的txt文件信息
:param file_names:读取相应训练集或者测试集中的图片
:param class_dict:类别名单
:param type:确定是训练集还是测试集
:return:
"""
for file in tqdm(file_name, desc="translate {} file...".format(type)):
img_path = os.path.join(voc_images_path, file + '.jpg') # 得到对应图像的路径
assert os.path.exists(img_path), "file:{} not exist...".format(img_path) # 检测是否图像存在
# file + '.xml' = xml的名称 例如 “012906.jpg”
xml_path = os.path.join(voc_xml_path, file + '.xml')
assert os.path.exists(xml_path), "file:{} not exist...".format(img_path) # 检测对应xml文件是否存在
# file + '.jpg' = 图片名字 例如 “012906.jpg”
xml_data = xml_object[file + '.jpg']
assert "object" in xml_data.keys(), "file: '{}' lack of object key.".format(xml_path) # 如果没有object对象,则不处理
if len(xml_data['object']) == 0:
print("Warning: in '{}' xml, there are no objects.".format(xml_path))
continue
# 获取图片高宽,给后面算绝对坐标
image_height = int(xml_data["size"]["height"])
image_width = int(xml_data["size"]["height"])
# 确定保存labels中txt文件路径
if type == 'train':
save_txt_path = os.path.join(save_path_train_labels, file + '.txt')
else:
save_txt_path = os.path.join(save_path_val_labels, file + '.txt')
with open(save_txt_path, "w") as f:
for index, obj in enumerate(xml_data["object"]):
# 获取四个坐标信息,待后续转换为yolo格式
xmin = float(obj["bndbox"]["xmin"])
xmax = float(obj["bndbox"]["xmax"])
ymin = float(obj["bndbox"]["ymin"])
ymax = float(obj["bndbox"]["ymax"])
class_name = obj["name"]
if class_name not in class_dict:
print("Warning: in '{}' xml, some class_name are error".format(xml_path))
continue
class_index = class_dict[class_name] - 1 # 目标id从0开始
# 进一步检查数据,有的标注信息中可能有w或h为0的情况,这样的数据会导致计算回归loss为NAN
if xmax <= xmin or ymax <= ymin:
print("Warning: in '{}' xml, there are some bbox w/h <=0".format(xml_path))
continue
# 将box信息转换到yolo格式
xcenter = xmin + (xmax - xmin) / 2
ycenter = ymin + (ymax - ymin) / 2
w = xmax - xmin
h = ymax - ymin
# 绝对坐标转相对坐标,保存6位小数
xcenter = round(xcenter / image_width, 6)
ycenter = round(ycenter / image_height, 6)
w = round(w / image_width, 6)
h = round(h / image_height, 6)
info = [str(i) for i in [class_index, xcenter, ycenter, w, h]]
if index == 0:
f.write(" ".join(info))
else:
f.write("\n" + " ".join(info))
# copy image into save_images_path
if type == "train":
path_copy_to = os.path.join(save_path_train_images, file+'.jpg')
else:
path_copy_to = os.path.join(save_path_val_images, file+'.jpg')
shutil.copyfile(img_path, path_copy_to)
def main():
# 通过pytorch官方datasets读取xml文件
data_path = './data'
voc_train = datasets.VOCDetection(data_path, year=voc_year, image_set='train')
voc_val = datasets.VOCDetection(data_path, year=voc_year, image_set='val')
# 创建文件夹目录
for path in save_path:
check_path(path)
# 提取出xml文件, 存放在xml_object中
xml_object = {}
for image, target in tqdm(voc_train, desc="extracting {} xml files...".format('train')):
data = {target['annotation']['filename']: target['annotation']}
xml_object.update(data)
for image, target in tqdm(voc_val, desc="extracting {} xml files...".format('val')):
data = {target['annotation']['filename']: target['annotation']}
xml_object.update(data)
# 读取出json文件
json_file = open(label_json_path, 'r')
class_dict = json.load(json_file)
# 将voc中train.txt和val.txt文件中的内容提取出来
with open(voc_train_txt_path, "r") as r:
train_file_names = [i for i in r.read().splitlines() if len(i.strip()) > 0]
with open(voc_val_txt_path, "r") as r:
val_file_names = [i for i in r.read().splitlines() if len(i.strip()) > 0]
# 训练集划分
voc_translate_yolo(train_file_names, xml_object, class_dict, type="train")
print("train file has been done!......")
# 测试集划分
voc_translate_yolo(val_file_names, xml_object, class_dict, type="val")
print("val file has been done!......")
# 生成.name 文件
create_class_names(class_dict)
if __name__ == "__main__":
main()总结
本文,更像是资料分享把,因为平常要将voc转为yolo的情况还挺多的