学习-共享:利用计算约束和参数共享的硬件友好迁移学习框架(2021-ICML)
摘要
针对预先训练过的多transformer的特定任务微调在多个NLP任务中取得了性能突破。但是,由于计算量和参数大小都是随子任务数量线性增长的,由于计算设备上不现实的内存和计算开销,这种方法越来越难以应用到现实世界中。之前关于微调的工作重点是通过共享参数来减少不断增长的参数大小以节省存储成本。然而,与存储相比,计算约束是现代计算环境中微调模型的一个更为关键的问题。在这项工作中,我们提出了一个在多个任务中利用计算约束和参数共享的框架——LeTS 。与传统的微调相比,LeTS提出了一种新的神经体系结构,它包含一个固定的预训练transformer模型,加上可学习的子任务附加组件。可学习组件重用固定预训练模型中的中间激活,解耦计算依赖。采用可微神经结构搜索方法确定特定任务的计算共享方案,并采用一种新颖的早期剪枝方法对加性构件进行稀疏化,实现参数共享。大量的实验表明,与完全微调相比,每个任务增加1.4%的额外参数,LeTS在GLUE基准上减少了49.5%的计算量,精度损失仅为0.2%。
引语
-
预先训练的transformers的微调(V aswani等人,2017)已经成为许多NLP任务的事实方法,随着各种自然语言理解基准的性能突破(Devlin et al.,2019;Lan et al.,2020; Liu et al.,2019d;Joshi et al.,2020;Y et al.,2019)。然而,越来越多的不同NLP任务进入流,使得这种方法很难集成到现实世界的商业产品中。关键的瓶颈在于计算和存储约束。特别是传统的微调方法(Howard & Ruder,2018;Wang et al.,2018),单输入处理延迟和存储需求都随子任务数量线性增长。这给商业产品带来了不切实际的计算、功率和存储开销。
-
计算和存储约束都是优化任务的关键。一方面,云计算厂商在不牺牲太多服务质量的情况下,更关注计算约束,以进一步提高质量。存储开销可以通过内存和存储技术的进步来解决(英特尔,2019;Consortium,a;b),这使得低成本和大容量的数据存储成为可能。另一方面,在内存有限的设备(如移动设备)中,这两种限制都对用户体验至关重要。大多数以前的工作重点是通过杠杆来减少多个子任务之间的存储约束荷兰国际集团(ing) parameter-sharing。多任务学习(MTL)将所有子任务一起训练(Liu et al.,2019b;Clark et al.,2019;Stickland &穆雷,2019)。但是,它需要在设计时访问所有子任务。此外,随着子任务数量的增加,MTL无法进行扩展,因为很难平衡多个任务的性能并同样很好地解决它们(Stickland & Murray,2019)。
-
最近,Adapter (Houlsby et al.,2019)以到达流的方式考虑新任务,与MTL相比,它更具有可扩展性。它建议在每个注意力层之间添加一个特定任务的构建块,并在微调期间冻结其他参数。最近的研究提出了一种可微分剪枝方法(Guo et al.,2020),该方法取得了比Adapter更好的结果
-
不幸的是,上述所有的参数效率努力并没有解决多任务推理的计算瓶颈,因为调整底层会影响下游层的计算结果。因此,需要重新计算。
-
为了减轻多任务评估中的计算和存储负担,我们提出了learn - To - share (LeTS),这是一个新的迁移学习框架,利用计算和参数共享来减少计算和存储需求,同时保持子任务的高性能。主要贡献如下:
-
-
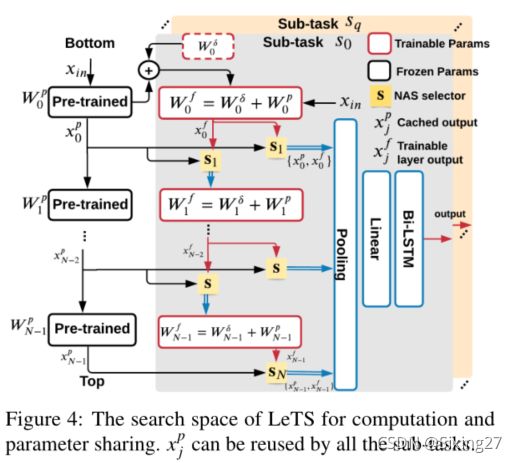
(i)我们提出了一个新的微调架构设计空间(图4)。每个自注意层的输出将在最后使用池化层和双向LSTM (Huang et al.,2015) (Bi-LSTM)进行聚合,得到最终的分类结果。这样,底层的修改不会影响下游的计算。这允许在转换器内并发执行。当Bi-LSTM使用已经计算过的注意值作为输入时,许多计算可以被绕过。此外,我们还发现,通过将矩阵-矩阵乘法转换为矩阵-向量乘法,可以减少更多的计算(章节3.2)。
-
(ii)我们设计了一种可微神经结构搜索(NAS)算法,以找到子任务的最优微调结构。具体来说,NAS选择每个注意层和最后的池层的输入。当选择一个计算结果作为各层的输入时,可以绕过多次计算,实现计算共享。在搜索空间中提出了一个新的计算感知损失函数,以减少计算量并保持任务精度。
-
(iii)我们将获得的微调模型权值视为预训练权值p与权差(δ)之和:Wf=Wp+Wδ,并提出一种新的早期剪枝方法来获得Wδ。在微调开始时,为w δ生成一个表示修剪的权值掩码。w δ不是随机初始化的,而是使用特定任务的梯度累积来初始化的,以获得一个健壮的权重掩码。
-
(iv)系统集成(ii)和(iii),生成任务性能高、计算和存储成本低的微调模型。在NAS过程中,(ii)对可训练参数生成的掩码可以更好地表征模型性能。此外,在在线原型制作过程中,给定线性层的输入和输出已经完成计算后,可以利用(iii)产生的稀疏性将计算简化为稀疏矩阵乘法。
-
-
我们的框架为不同的计算环境生成有效的微调语言模型。大量的实验表明,Lets在实现子任务精度的同时,大大降低了计算成本。更具体地说,对于计算和存储受限的平台,LeTS通过每个任务仅增加1.4%的额外参数,减少49.5%的计算量,同时在GLUE基准上保持微调BERT(Devlin et al.,2019)的高任务精度。对于具有低成本存储预算的计算环境,Lets可以在没有精度损失的情况下实现40.2%的计算减少。而且,Lets的子任务越多,每个任务的计算量就越少。对于每个新添加的任务,Lets需要7.2 gflops1,而调优的BERTBASE需要22.5 GFLOPs。
-
LeTS是第一个在多任务NLP微调中同时考虑计算和存储效率的框架。我们的工作可以结合模型压缩技术(Lan et al.,2020;Sanh et al.,2019),以实现敏捷和高效的NLP评估。
概观
将讨论Lets中的关键设计组件。具体的设计流程见算法1

动机
在实时多任务评估中,输入查询由多个微调transformer同时评估。每个任务集中在一个特定的子任务上,一些任务可能依赖于其他任务的计算结果。例如,文档编辑软件(如谷歌Doc或Microsoft Word)中存在多个任务,如分析音调、检查语法,然后生成编辑建议。传统的微调方法效率极低,所需的计算量和参数随子任务数量线性增长,导致服务质量和用户体验下降。在这项工作中,我们的目标是通过计算重用产生多任务评估加速。与之前的实时旁路计算(Xin et al.,2020;Bapna et al.,2020)不同,LeTS可以产生不依赖输入的保证加速。
传统微调程序的局限性
我们观察到传统的精细调优过程的并行化和计算共享的三个限制:
- (1)注意层的计算只有在其所有前一层都产生结果时才能开始执行。
- (2)底层的任何修改都会改变后续的计算,因此需要重新计算。
- (3)虽然之前的参数共享工作(Guo et al.,2020)使w δ变得稀疏以减少子任务中的参数增长,但不能利用这种稀疏性来减少计算。
LeTS设计
基于这些观察,我们提出了一种新的微调体系结构,可以通过重用计算结果来减少计算量。此外,新的体系结构将不同层的数据依赖解耦,以支持加速。

新架构的优点
-
绕过自注意层:当缓存的结果xp j被最后的池化层和下一个可训练层使用时,可以保存整个层的计算和参数。这可以应用于层Wp j这里j∈{0,1,2,6}。
-
利用w δ的稀疏化:更具体地说,当可训练注意层的输入是xp j−1时,Lets计算xp j−1·Wδj并且将其添加到缓存结果中。在图2 (b),当j∈{3,4,5,7,9},xp j−1和WfK j、WfQ j和wfv j(键/查询/值参数)之间的计算可以通过利用这种非结构化稀疏性来减少。注意,这种稀疏矩阵乘法可以很容易地在许多流行的机器学习库中实现。
-
在自注意中绕过线性层:池化层提取每一层输出的第一个隐藏向量作为聚合表示。对于wf j 这里 j∈{3,5,8,11},下游计算只使用输出的第一个隐藏向量;在这个场景中,我们将池操作移动到图2(a)中的n3和n4之间。因此,自我注意层中的n4和n5可以简化为矩阵向量乘法。标准化层(n6)将只应用于池向量,而不是原始层输出。
-
在每个transformer内启用并发执行:当子任务相互依赖且必须按顺序执行时,则执行模型可以在每个transformer内部的计算设备之间并行。这是因为底层的参数调优不再影响下游的计算。在图2(b)中,假设所有9个GLUE任务共享相同的架构,执行时间由关键路径决定,

-
图3显示了利用(i)(ii)(iii)对每个任务额外计算和参数的分解。额外线性层和Bi-LSTM的计算和参数开销为0.01%/0.75%(图3)。图2(b)中示例的额外计算和参数分解杠杆(i) (ii)和(iii)。

神经架构搜索的计算共享
- 所有可能的Lets微调体系结构都可以表述为一个搜索空间,如图4所示。每一层使用两个NAS选择器来搜索(i)下一层的输入(ii)到最终池层的输出。
- 所得到的体系结构应该在低额外计算操作的情况下达到具有竞争力的子任务精度。为了解决这个问题,我们利用具有计算感知损失的可微分NAS算法来反映子任务的计算成本和准确性。详细的搜索算法在第3节中给出。

Wδ的剪枝
最近的参数共享方法要么在注意层之间添加一个新的模块(Pfeiffer等人,2020;Houlsby等人,2019),要么在微调期间使用l0归一化同时生成权重掩模(Guo等人,2020)。Y等人的许多研究(Gale et al.,2019)表明,对于大规模任务,l0正则化输出是不一致的。此外,训练参数(即权重掩码和参数)在微调时加倍。
在这项工作中,我们将最终的微调权重wf作为处理为预训练权重wp与权重差(Wδ)之间的相加。通过提出一种称为delta - pruning的早期剪枝方法,我们计算了w δ的连接敏感性,揭示了给定任务中w δ中的重要连接(见3.1节)。通过这种方式,我们可以在微调开始时获得确定的特定于任务的掩码,并使用生成的掩码来指导NAS。
方法
详细介绍delta - pruning和计算感知神经架构搜索算法。
早期的delta - pruning
- Delta-Pruningis的动机是SNIP (Lee etal.,2019),目标是在训练前生成权重稀疏性。我们将最终的微调权重(Wf)分解为两部分,如Eq.(1)所示。Wδ是微调权重差异,c是生成的掩模是用于w δ,c∈ {0,1}d,点乘内积。给定一个任务数据集D,Delta-Pruning的目标是在不干扰搜索和最终微调阶段的情况下,在微调的开始阶段找到掩码c。

假设w δ中的k参数不变,约束优化问题可描述为式(2):
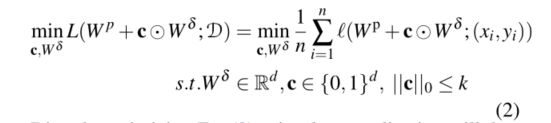
- 使用l0归一化直接优化Eq.(2)将使可学习参数加倍(Louizos et al.,2018),并且对于大规模任务是不稳定的(Galeet al.,2019)。在DNAS算法(Sec3.2)中搜索掩码和体系结构参数更加困难。
- 在这项工作中,我们打算测量w δ中的连接对损耗函数的影响e。具体来说,如果去除wδe没有显示足够的损失变化(∆Le),我们设置掩码ce=0训练期间的梯度w δ。计算∆Le存在两个挑战:(i)去除wδe中的每个连接并检查损失的变化是耗时的。(ii)在微调开始时Wδe是未知。随机初始化方法不能反省完全微调的w δ。
- 为了解决(i),我们将c二元约束松弛到连续空间,并计算L的梯度(Eq。(3))。根据关于ce的导数的大小直观地表明参数w δ e是否对L有相当大的影响,当去除w δ中的e连接时, 我们使用ge去近似∆Le。因此,我们将w δe的连接灵敏度定义为网络中ge的和的一般化(Eq.(4))。
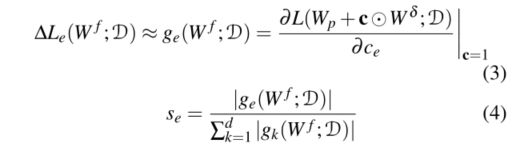
然后,假设w δ中的参数被修剪,我们生产掩码c采用由连接灵敏度计算的显著性准则

sk ~是向量中的第k大元素,1{}为指标函数。
为了解决(ii),我们首先通过使用数据D,和n step来获得Wf,预热微调来学习权值差值初始化。用特定任务初始化Wδ=Wf−Wp。我们的消融研究表明,与随机初始化相比,使用特定任务的热身具有更好的效果,因为梯度的积累可以更好地反映最终的权重差异分布。
计算共享的可微神经结构搜索
正如第2节所讨论的,一个很有前途的特定于任务的微调体系结构应该产生较低的额外计算成本和较高的任务精度。我们将微调模型的选择表述为一个双层非凸优化问题,如Eq.(6)所示。

这里,A是Lets中提出的一个新的搜索空间,a∈A是NAS选择器中指定一个可能架构的连续变量集,Wa是从搜索空间A中的a中选择的微调架构。损失函数不仅降低了精度,但增加了额外的计算量。
搜索空间
- 首先建立搜索阶段的随机超级网络。在搜索之前,我们从wp到wτ可训练层复制权值,并禁用基于cτ的梯度计算,这是Delta-Pruning得到的权值差掩模。每个注意层Wτj应该做两个决定:(i)可训练层的输入。它可以是缓存的结果(xp j−1)或前一个可训练层(xf j−1)的输出。(Ii)从层j到池化层的输出。它可以是xp j或者xf j,搜索空间的总大小为4N次N是预训练模式下的层数。
使用两个架构选择器(si j,i∈{0,1})分别决定层j中的(i)和(ii) (j∈1,…N 如图4所示)。每个sij都与一个结构向量ai j(1 × 2)相关联。我们将架构的选择放宽到Gumbel Softmax (Jang et al.,2016),而不是两个可能的来源:

- xin j为wτ中第j个可训练层的输入。
- […]是一个连接操作
- Gumbel converts ai j成为一个概率向量,用于近似离散类别选择 温度参数与gumbel function有关,控制其分布。当熵值高时,Gumbel(ai j)成为连续随机变量,当熵值低时,Gumbel(ai j)接近离散选择。在搜寻过程中,我们逐渐降Gumbel中的T以引导NAS。
搜索算法和最终的微调架构
- 我们在掩码cτ下交替更新两个变量a和wτ 求解Eq.(6)中的双级优化问题。更具体地说,我们利用二阶近似(Liu etal.,2019a)(公式在附录B)来更新,因为:(i)总参数不是很大(~100)。因此,使用二阶近似是可行的,尽管它需要更多的计算;(ii)与梯度下降(Liu et al.,2019a)相比,二阶近似在NAS中可以产生更好的解。
- 当搜索结束时,我们使用a作为第j层选择最终的连通性,准确地说,输入连接性被选择为x j-1=targ max t∈{p,f}a0jt,并且输出到池化层x j-1=targ max t∈{p,f}a1jt,然后,我们对注意力层进行优化,s1 j选择xf j−1并且s0,j+1选择xp j以减少更多的计算量。我们将最终的池操作移动到图2(a)中的n3和n4之间。这样,以下线性层(n4,n5)的计算可以简化为矩阵-向量乘法。归一化层(n6)将应用于n5的输出向量。
Computation-aware损失函数
为了兼顾任务精度和计算代价,我们定义LeTS在线搜索阶段的损失函数为:
![]()
- CE(a,Wτ)给定结构参数a和超级网络Wτ的交叉熵损失
- α、β是控制运算项大小的指数因子。对于Eops,我们通过架构参数计算操作的期望a:

- ops(Wτj)返回j层中基于s0j和s1jin的2 × 2矩阵的选择组合的数字操作。更具体地说(见图2(b))
- (I) 如果s1j 和 s0j 都选择 xp j−1作为他们的输入。这样就可以绕过整个层的计算。(ii)如果s0 j选择xp j−1和s1j选择xf j−1作为其输入,则xp j−1与WfK j的计算,通过利用w δ j的稀疏特性,Wfk j将成为稀疏矩阵乘法。根据wτ j的稀疏比计算运算次数。除了以上两种情况,还返回了传统自注意层的计算操作。注意,ops返回一个给定Wτj的常值矩阵。因此,E ops对体系结构参数的可微性有助于寻找计算效率高的模型。
评估
实验设置
数据集
我们在**General Language Understanding Evaluation (GLUE)基准(Wang et al., 2018)**上评估let,包括以下九个任务:斯坦福情绪树库(SST-2)。微软研究释义语料库(MRPC)。Quora问答(QQP)。语义文本相似性基准(STS-B)。多类型自然语言推理语料库(MNLI)(我们测试了匹配域mnlimm和不匹配域mnlimm)。斯坦福问答数据库(QNLI)。文本蕴涵的识别。
度量
我们报告了Matthew对CoLA、Spearman对STS-B、F1评分对MRPC/QQP、MNLI/QNLI/SST-2/RTE的相关性。为了提高计算效率,我们报告了子任务之间相互依赖的最大速度。此外,我们还通过调优的bert的FLOPs显示了每个任务的新FLOPs,以及计算这9个子任务所需的总操作。对于参数效率,我们报告每个任务的总参数和新参数。度量的方程在附录A中给出。
基线
所有之前的参数共享工作都在bertlargmodel上进行了测试(Devlin et al.,2019)。我们将let与以下基线进行比较:(i)以传统方式对bertlarge进行全面微调;(3)适配器(Houlsby et al ., 2019)。(iv) DiffPruning(郭et al ., 2020)。(v)BitFit(Ravfogel & Goldberg),使用较大的学习率对偏差参数进行微调。(见Sec.5)
此外,我们还将let与模型压缩工作进行了比较,如distilbert、MobileBERT(Sun et al.,2020)和tinybert (Jiao et al.,2020),它们通过知识蒸馏压缩了bertbase (Sec.5)。这个比较是在BERTBASE上进行的。
注意,前面所有的参数共享都不能减少多任务计算的计算开销。因此,我们建立了两个额外的基线:(vi)我们冻结底层的自我关注层,并微调顶层。(vii)我们在预训练模型的顶部添加已知层,并冻结预训练的权重(图2(d))。
LeTS设计设定
我们利用let为具有不同计算/存储预算的平台设计微调模型:(i)我们在GLUE中为每个任务搜索特定于任务的架构,并使用生成的稀疏掩码(记为asLeTS-(p,c)2)对其进行微调。(ii)在最后的微调过程中,我们还通过去除重量掩模来进行消融研究,以获得更好的精度(记为let -©)。这适用于存储预算低的计算平台。(ii)为了最大化搜索模型中的并行性,我们将注意层解耦为组(表示为lets -g -g),并要求每组中的第一层使用缓存的输入(xp j−1);因此,可以同时执行不同组的计算。在每个组内,我们仍然使用dna来决定连接。
超参数
dna法需要1天,4天,平均每个任务V100 gpu,不到bertlarge训练前成本的0.5% (Devlin et al.,2019)。BERT的最大输入长度被设置为128以匹配以前的基线。我们预先训练的模型和代码库来自(Wolf et al.,2020)。我们使用ensteps =100来初始化Wδ(Sec.3.1)。受(Ravfogel & Goldberg)偏见项需要更大的学习率才能达到更好的微调结果的启发,我们在最终的微调过程中,分别使用两个具有不同学习率调度程序的优化器对偏见项(lrb∈{1e−3,5e−4})和其他部分(lrw∈{2e−5,1e−5})进行更新。其他超参数的详细信息见附录a。培训时间和费用报告见附录B。
结果
与GLUE数据集上的基线比较
我们与基线方法的比较如表1所示。let -©/-(p,c)可以达到与完全微调的bertlargmodel相似的性能(平均+0.2%/0.2%),同时节省40.2%/49.5%的计算量。使用更激进的设置,let - g -4可以在匹配适配器的任务性能时减少57.0%的计算量(3.84×speedup)。同时,let -(p,c)/- g -4仅为每个任务添加1.4%的参数(包括Linear和Bi-LSTM层),这比适配器的参数效率更高。let说明了并发执行加速和多任务性能之间的权衡,这是以前的工作没有做到的。
与在bertbase上减少了50.4%/28.3%/50.4%总计算量的DistilBERT6、MobileBERT和TinyBERT6相比,let - g -3/-G-4显示了56%/62%的计算量减少,同时与微调模型相比保持了较高的任务性能(-0.5%/-0.8%)。对于高度压缩的模型(例如TinyBERT-4, MobileBERTTINY,DistilBERT-4),与完整的微调模型相比,尽管比let节省了更多的计算量,但它们表现出了较大的性能下降(-2.3%/-2.6%/-7.7%)。此外,与所有压缩模型相比,LeTS显示了最低的参数开销(1.15×)。
与“Freezing Bot-12”和“apppending Top-1”相比,let的任务表现平均也更好(+1.3%/+8.3%)。这是因为我们放松了所有层的微调约束,并聚合最终分类的结果。此外,当子任务数量增加时,let可以比Freezing Bot-12节省更多的计算(每个任务42.6%的新FLOPs,而50%)。

Delta-Pruning与其他参数共享方法的比较
表2显示了deltapruning与之前参数共享工作的性能比较。为了进行公平的比较,使用原始的微调体系结构对结果进行测试。当每个任务的稀疏率限制为0.1%/0.25%/0.5%时,let的平均性能比DiffPruning提高了2.4%/0.8/0.6%。这表明,与正则化方法相比,Delta-Pruning方法可以有效地保持任务的准确性。

敏感性和消融研究
改变BERTLARGEmodel / Weight mask分布的稀疏性约束
我们还使用Delta-Pruning对GLUE基准进行了敏感性分析(表2),该基准具有不同的稀疏率(0.1%/0.25%/0.5%)。随着稀疏比的增长,不同的任务表现出不同的灵敏度。通过对每个给定任务进行网格搜索,可以更好地在准确性和稀疏性之间取得平衡。此外,我们还显示了每个层的权重遮罩的分布在不同的基准测试中(图6)。我们假设当任务的输入或输出是相关的(如QQP和QNLI都编码问题/ MPRC和STS-B都产生相似性),它们显示相似的掩模分布。这表明在任务的每一层之间添加一个统一的模块(例如Adapter)是次优的。

对计算共享比率的敏感性/对计算感知损失函数的消融
为了展示let在减少计算的同时保持高任务精度的能力,我们对2个任务执行多次NAS(在损失函数中具有不同的α,β),并从分布中取样不同的结构。图5显示了额外操作与任务准确性之间的结果(在GLUE开发集上)。随着k的增加,冻结bot-klayers不能保持任务的准确性,而从let中搜索的架构并没有显示出很大的性能下降。与随机抽样架构相比,let也表现出更好的任务准确率,这表明我们的dna算法可以提高搜索模型的质量。当去除计算感知损失函数时,dna倾向于选择更多的可训练矩阵以保持任务性能,搜索模型不能充分利用计算共享。

相关工作
迁移学习的微调
通过微调单个任务的所有权重,可以将预先训练的模型转移到感兴趣的任务(Howard & Ruder,2018)。文本分类的最新进展(Dai et al.,2019;Liu Joshi等人,2020;Y等人,2019)已经通过微调预训练变压器实现(V aswani等人,2017)。但是,它修改了网络的所有权值,使得下游任务的参数效率低下。
多任务学习
多任务学习(MTL)在多个任务上同时学习模型,并在不同范围的任务中使用它们(Caruana,1997)。MTL已被广泛利用BERT进行开发,并在多个文本分类任务中显示出良好的性能(Liu et al., 2019b;Clark et al.,2019)。在本工作中,我们假设多个任务到达流中(即在线设置),因此无法像第1节中讨论的那样进行联合训练。此外,在培训中平衡多个任务并同样很好地解决它们是具有挑战性的(Stickland & Murray,2019)。let可以与MTL结合使用。这将改变我们对在线设置(任务一个接一个到达)的假设,变成“n个任务同时到达”。然后将一起搜索和微调任务。我们把这个组合留作未来的工作。
参数共享用于微调
适配器是用于在线设置的参数高效BERT模型的一种替代(Houlsby等人,2019)。它适用于机器翻译(Bapna & Firat,2019)、跨语言迁移(¨Ust¨un et al.,2020)和迁移学习的任务合成(Pfeiffer et al.,2020)。这些特定于任务的适配器被插入到层之间,并且由于底层的修改而不能利用计算共享。最近的工作(Guo et al.,2020)使用归一化在多任务NLP的微调过程中训练掩模。在本文中,我们提出了一种基于SNIP (Lee et al.,2019)的删减权差的新方法,以压缩特定任务的知识,实现更好的参数效率。
Hardware-aware NAS。
NAS的最新进展利用可微分方法,放松了连续空间架构的选择,以降低基于rl的NAS的高搜索成本(Zoph & Le,2016;Tan et al.,2019;Tan & Le,2019)。以前的可区分NAS工作(Wu et al.,2019;Liu et al.,2019a;Wan et al.,2020;Fu et al.,2020)主要专注于计算机视觉任务。在let中,我们结合(Wu et al.,2019)和(Liu et al.,2019a)的搜索算法来解决NLP中的一个独特问题。let还提出了一种新的搜索空间,该空间具有计算感知的搜索损失模型,具有较高的任务准确率和计算共享率。
模型压缩
模型剪枝是另一种减少单个模型大小和计算量的方法。(Gordon et al., 2020)基于量级的BERT中修剪权重,(Guo et al.,2019)使用迭代重加权l1minimization, (Lan et al.,2019)利用跨层参数共享。其他的研究从预先训练的模型中提取知识到更小的学生模型(Sanh et al.,2019;Sun et al.,2020;Jiao et al.,2020)。注意,let与所有这些方法都是正交的,因为我们没有修改预先训练的参数。我们把这个组合留作未来的工作。
结论
我们提出了一个迁移学习框架LeTS,当多个任务到达流时实现计算和参数共享。LeTS提出了一种新的架构空间,可以重用计算结果来减少计算量。通过利用具有计算感知损失功能的NAS, LeTS可以找到具有高任务性能和低计算开销的模型。将优化后的权值作为预训练权值与权值差之和,提出了一种早期剪枝算法,在不降低任务性能的前提下压缩权值差。上述新颖性的整合利用了权值差的稀疏性,可以进一步减少计算量。与之前只共享参数的方法相比,LeTS实现了更好的任务性能。此外,通过利用计算共享,LeTS产生了大量的计算减少,以支持可扩展的迁移学习。LeTS可以与多任务学习相结合,以达到更好的任务表现,我们将其作为未来的工作。