经典神经网络 -- RetinaNet的Focal_Loss : 设计原理与pytorch实现
原理
损失函数: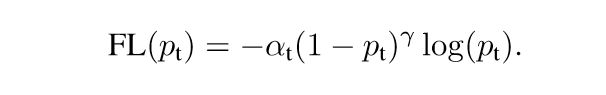
a 是用来调解正负样本,根据不同的比例来减少正负样本loss的比例,从而提高模型学习能力,一般情况下正样本远远小于负样本,所以设置a=0.25,负样本为0.75就能缩小loss的比例。
γ 负责降低简单样本的损失值, 以解决加总后负样本loss值很大,这样可以让模型学习的时候多学习到困难样本的特征来达到更好的识别效果。
(1-pt)这里可以代表预测的分值越高则值越小,pt越小值越大,这种的好处是一旦分很低,造成的loss更大,让模型学习效果更好。
特点:
在模型学习的时候注意力集中在分值很低的预测来降低loss。在进行梯度下降的时候,模型通过训练只是为了loss的降低,这样就专门针对导致loss大的值进行修改来降低loss,就能获得好的模型。
代码实现
重要的是loss公式实现,以及一些tensor函数使用。
# focal loss是retinanet网络提出的新型损失函数,重点就是当正负样本差距过大,导致训练效果低下时,
# 该如何减少负样本的loss,增加正样本占全部loss的比重,从而有效的控制样本差距带来的好的模型学习能力。
from torch import nn
import torch
from torch.nn import functional as F # 必要
class focal_loss(nn.Module):
def __init__(self, alpha=0.25, gamma=2, num_classes=5, size_average=True):
super(focal_loss, self).__init__()
self.size_average = size_average # 是否将每一个batch的loss加总后平均
if isinstance(alpha, (float, int)): # 仅仅设置第一类别的权重
self.alpha = torch.zeros(num_classes) # [0.,0.,0.,0.,...,0.]
self.alpha[0] += alpha # [alpha,0.,0.,0.,...,0.]
# [alpha,1 - alpha,1 - alpha,1 - alpha,...,1 - alpha]
self.alpha[1:] += (1 - alpha)
if isinstance(alpha, list): # 全部权重自己设置
self.alpha = torch.Tensor(alpha)
self.gamma = gamma
def forward(self, inputs, targets):
alpha = self.alpha
# tensor([0.2500, 0.7500, 0.7500, 0.7500, 0.7500])
print('aaaaaaa', alpha)
N = inputs.size(0)
print('nnnnnnnnnnn', N) # 5
C = inputs.size(1)
print('ccccccccccc', C) # 5
P = F.softmax(inputs, dim=1) # 将inputs进行softmax,杂乱的数据映射到0-1区间内
print('ppppppppppp', P)
# tensor([[0.0635, 0.2920, 0.4117, 0.1595, 0.0734],
# [0.4445, 0.1057, 0.0810, 0.1186, 0.2501],
# [0.1678, 0.2101, 0.0960, 0.1782, 0.3480],
# [0.2171, 0.2126, 0.3949, 0.1447, 0.0306],
# [0.0577, 0.1277, 0.5094, 0.1682, 0.1370]], grad_fn=)
# ---------one hot start--------------#
# .data取出数据部分 .new生成和input一样shape的tensor,且无内容 .fill_(0)填充为0
class_mask = inputs.data.new(N, C).fill_(0)
print('依照input shape制作:class_mask\n', class_mask)
# tensor([[0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.]])
class_mask = class_mask.requires_grad_() # 需要更新, 所以加入梯度计算
# requires_grad=True 的作用是让 backward 可以追踪这个参数并且计算它的梯度
# 最开始定义你的输入是 requires_grad=True ,那么后续对应的输出也自动具有 requires_grad=True
# 只有 requires_grad=True 的参数才会参与求导
# 如果你想取的参数是由 torch.tensor(requires_grad=True) 定义的,可以直接取它的 grad
# 如果你的参数是如 y 和 z 这样计算出来的,那么根据编译器警告,需要定义 y.retain_grad() 就可以取得 y 的 grad
# 还有一个方法是使用钩子可以保存计算的中间梯度
# 梯度的计算会在计算完成后遗弃,并且 requires_grad=False 的参数不计算它的梯度,如此可以减少内存使用和降低计算量
# 在使用 Pytorch 的 nn.Module 建立网络时,其内部的参数都自动的设置为了 requires_grad=True ,故可以直接取梯度
# 叶子节点:只有定义的 Tensor 参数才是叶子节点;只有 requires_grad=True 和叶子节点 is_leaf=True 才有 grad 的值
'''
使用backward()函数反向传播计算tensor的梯度时,并不计算所有tensor的梯度,而是只计算满足这几个条件的tensor的梯度:
1.类型为叶子节点、
2.requires_grad=True、
3.依赖该tensor的所有tensor的requires_grad=True。
在pytorch中,神经网络层中的权值w的tensor均为叶子节点;
自己定义的tensor例如a=torch.tensor([1.0])定义的节点是叶子节点
'''
ids = targets.view(-1, 1) # 展开一维 取得标签的索引
print('取得targets的索引\n', ids)
# tensor([[4],
# [4],
# [4],
# [4],
# [4]])
class_mask.data.scatter_(dim=1, index=ids.data, value=1.) # 利用scatter将索引丢给mask
# scatter_(input,dim,index,value) 将value对应的值按照index确定的索引写入input张量中,其中索引是根据给定的dim(维度)来确定的。
"""
Args: input.scatter_(dim, index, value)
input:要进行scatter_填充的tensor
dim:在input张量进行scatter_填充的维度
index:input对应dim的填充索引,要小于对应填充维度的长度,且index维度要与input张量维度一致
value:填充值
"""
# scatter() 不会直接修改原来的 Tensor
# scatter_() 会在原来的基础上对Tensor进行修改
print('targets的one_hot形式\n', class_mask) # one-hot target生成 在最后一列填充了1.
# tensor([[0., 0., 0., 0., 1.],
# [0., 0., 0., 0., 1.],
# [0., 0., 0., 0., 1.],
# [0., 0., 0., 0., 1.],
# [0., 0., 0., 0., 1.]], requires_grad=True)
# ---------one hot end-------------------#
probs = (P * class_mask).sum(1).view(-1, 1) # 求和 展开
print('留下targets的概率(1的部分),0的部分消除\n', probs)
# 将softmax * one_hot 格式,P中的0的部分被消除 留下1的概率, shape = (5, 1), 5就是每个target的概率
# tensor([[0.0734],
# [0.2501],
# [0.3480],
# [0.0306],
# [0.1370]], grad_fn=)
log_p = probs.log() # 取得对数
print('取得对数\n', log_p)
# tensor([[-2.6114],
# [-1.3858],
# [-1.0556],
# [-3.4873],
# [-1.9875]], grad_fn=)
loss = torch.pow((1 - probs), self.gamma) * log_p # 公式(1-p)^gamma * log_p
batch_loss = -alpha * loss.t() # 公式 .t()是转置
print('每一个batch的loss\n', batch_loss)
# batch_loss就是取每一个batch的loss值
# 最终将每一个batch的loss加总后平均
if self.size_average: # 默认
loss = batch_loss.mean() # 平均
else:
loss = batch_loss.sum() # 求和
print('loss值为\n', loss)
return loss
if __name__ == '__main__':
torch.manual_seed(50) # 随机种子确保每次input tensor值是一样的
input = torch.randn(5, 5, dtype=torch.float32,
requires_grad=True) # [5,5] 浮点型数据 有梯度计算的需要
print('input值为\n', input)
# tensor([[-1.1588, 0.3673, 0.7110, -0.2373, -1.0129],
# [ 0.5580, -0.8784, -1.1446, -0.7629, -0.0170],
# [-0.0477, 0.1770, -0.6058, 0.0125, 0.6818],
# [ 0.4508, 0.4299, 1.0491, 0.0453, -1.5092],
# [-1.5502, -0.7564, 0.6274, -0.4808, -0.6856]], requires_grad=True)
targets = torch.randint(5, (5, ))
targets[:] = 4
print('targets值为\n', targets) # tensor([4, 4, 4, 4, 4])
criterion = focal_loss() # 实例化focal_loss 使用默认init参数
# 实例化后,调用net(x)或者net(x,y),就是调用net里重载的forward函数
loss = criterion(input, targets)
loss.backward() # 反传 只需调用.backward()不需重载
a = F.cross_entropy(input, targets) # 交叉熵损失 对比
print('CE loss', a)
参考文章:
叶子节点和tensor的requires_grad参数 - 知乎
pytorch 深入理解 tensor.scatter_ ()用法_aoi997的博客-CSDN博客_tensor.scatter
Pytorch中的scatter_函数_.我心永恒_的博客-CSDN博客_pytorch scatter_函数
pytorch 实现Focal loss 详细讲解 代码简洁易懂_视觉盛宴的博客-CSDN博客_focal loss pytorch