U-net网络框架 学习笔记
一 U-net 提出的背景及好处
原论文为:U-Net: Convolutional Networks for Biomedical Image Segmentation
1.1提出背景:
-
Unet提出的初衷是为了解决医学图像分割的问题;
- 一种U型的网络结构来获取上下文的信息和位置信息
- 为了解决细胞层面的分割的任务
1.2在医学领域的优势 :
1.医疗影像语义较为简单、结构固定。需要去筛选过滤无用的信息。医疗影像的所有特征都很重要,因此低级特征和高级语义特征都很重要,所以U型结构的skip connection结构(特征拼接)更好派上用场
2. 医学影像的数据较少,获取难度大,数据量可能只有几百甚至不到100,因此如果使用大型的网络例如DeepLabv3+等模型,很容易过拟合。大型网络的优点是更强的图像表述能力,而较为简单、数量少的医学影像并没有那么多的内容需要表述。
3.医学影像任务中,往往需要自己设计网络去提取不同的模态特征,因此轻量结构简单的Unet可以有更大的操作空间。
二 U-net网络的核心框架
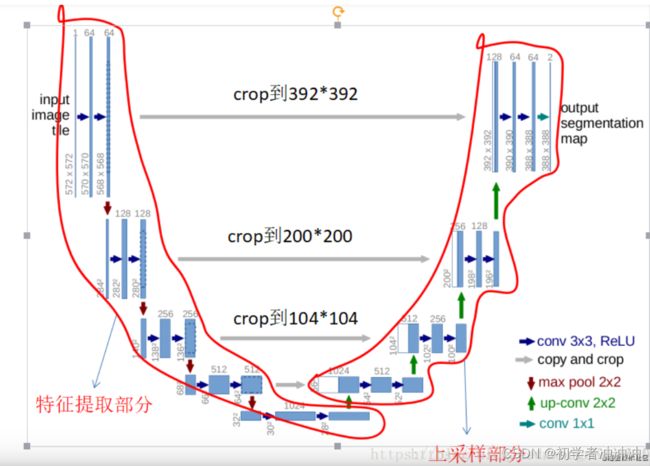 U-net网络框架
U-net网络框架
相当于 Encoder-Decoder的结构:
Unet网络非常的简单,前半部分就是特征提取,后半部分是上采样。
Encoder:左半部分,由两个3x3的卷积层(RELU激活函数)再加上一个2x2的maxpooling层(最大池化层)组成一个下采样的模块
Decoder:有半部分,由一个上采样的卷积层(去卷积层)+特征拼接concat+两个3x3的卷积层(ReLU)反复构成
关于CNN网络的一些知识复习(之前学过但忘记了)
1.卷积操作(向上采样):


具体计算例子:中间滤波器filter与数据窗口做内积,其具体计算过程则是:4*0 + 0*0 + 0*0 + 0*0 + 0*1 + 0*1 + 0*0 + 0*1 + -4*2 = -8
主要有一下几个重要参数:
输入图像的尺寸 (n*n)、卷积核的尺寸(Kernel)、填充尺寸(Padding)、
步长(Stride)、卷积核的个数 n(对应生成的通道)、输出尺寸(m*m)
输出图像的尺寸满足这个公式:
输出的尺寸=(输入的尺寸-核的尺寸+2*填充尺寸)÷步长+1
m=(n-k+2*p)/s+1
2 最大池化操作(max pooling):
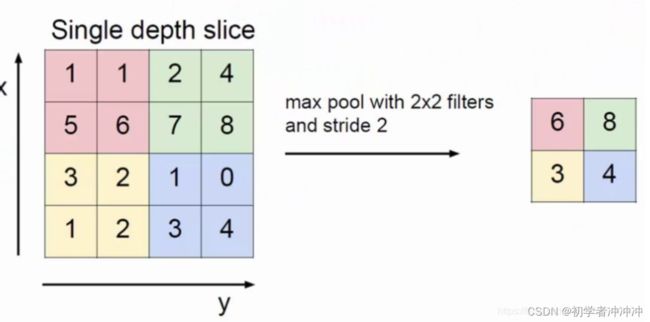
从上图可以看出,池化的结构和卷积一样,都是在输入的数组内以一个指定的大小扫描全图,但是池化不用计算,只做筛选。最大池化就是筛选出区域内最大值,平均池化就是计算区域的平均值。
3.RELU(激活函数):

4.反卷积操作(向下采样):
转置卷积不是卷积的逆运算,转置卷积也是卷积,(实际就是按照一定规则在图像周围补充0,在进行卷积)具体规则:

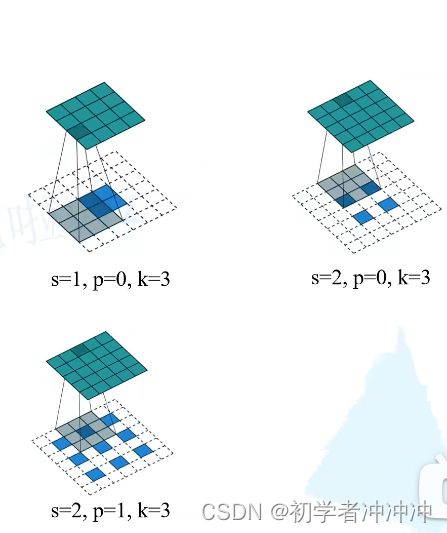
输出的高度和宽度计算公式:

U-net包括两部分,基于FCN 。第一部分,特征提取。第二部分上采样部分。由于网络结构像U型,所以叫Unet网络。
特征提取部分:每经过一个池化层就一个尺度,包括原图尺度一共有5个尺度。收缩路径就是常规的卷积网络,它包含重复的2个3x3卷积,紧接着是一个RELU,一个max pooling(步长为2),用来降采样,每次降采样我们都将feature channel减半。
上采样部分:每上采样一次,就和特征提取部分对应的通道数相同尺度融合,但是融合之前要将其crop。这里的融合也是拼接。扩展路径包含一个上采样(2x2上卷积),这样会减半feature channel,接着是一个对应的收缩路径的feature map,然后是2个3x3卷积,每个卷积后面跟一个RELU,因为每次卷积会丢失图像边缘,所以裁剪是有必要的,最后来一个1x1的卷积,用来将有64个元素的feature vector映射到一个类标签。
5.overlap-tile重叠平铺策略(可以把分辨率较大的图像化分成小区域图片有利于计算):
overlap-tile策略:
该策略的思想是:对图像的某一块像素点(黄框内部分)进行预测时,需要该图像块周围的像素点(蓝色框内)提供上下文信息(context),以获得更准确的预测。简单地说,就是在预处理中,对输入图像进行padding,通过padding扩大输入图像的尺寸,使得最后输出的结果正好是原始图像的尺寸, 同时, 输入图像块(黄框)的边界也获得了上下文信息从而提高预测的精度,本文用的是mirror padding(以边的对角线为中轴线进行镜像)。
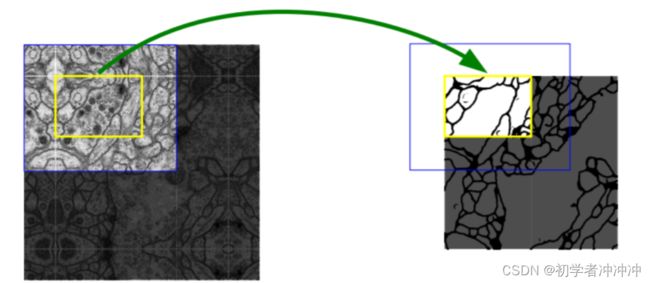
医学图像是一般相当大,但是分割时候不可能将原图太小输入网络,所以必须切成一张一张的小patch,在切成小patch的时候,Unet由于网络结构的原因,因此适合用overlap的切图 overlap部分可以为分割区域边缘部分提供文理等信息, 并且分割结果并没有受到切成小patch而造成分割情况不好。
6.细胞分割任务中的另一个挑战是分离同一类别的接触物体。
参见图3。为此,我们使用了加权损失,这些位于touching cells之间的背景在损失函数的权重很高。
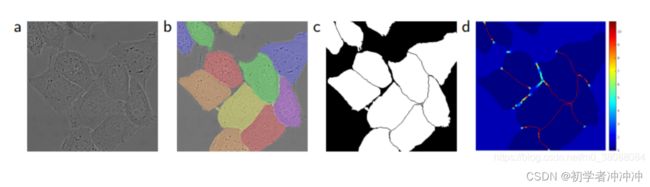
我个人的理解就是,在不同的区域之下设置不同的权重,在细胞边界分割之处可以设置较大的权重,在其他的区域可以设置一些较小的权重,在原论文中并没有提出这样做法所提升的效能。
7. 训练部分:(这个暂时未搞明白)

8.论文中的一些不足:
就是在拼接(crop)过程中,特征提取部分的图像大小和向上采样部分的图像大小不同,这就需要裁剪,这就会导致最终提取的图像大小会比原图像小,会有图像的损失。
主流的解决方法,在特征提取部分进行Padding处理,在卷积和RELU中间加入 bn(batch normalization) 。
9.接下来学习
1. 交叉损失函数(在逻辑回归学习时接触过)
2.batch normalization
3.搞清损失函数以及具体训练过程