【爬虫】爬取电影封面思路
前言:上篇博客我爬取了“最近上映的电影”的影评的做了打印处理和统计词频数据处理并绘制词云,那么我想在爬取一下这些电影的封面
目录
前言:上篇博客我爬取了“最近上映的电影”的影评的做了打印处理和统计词频数据处理并绘制词云,那么我想在爬取一下这些电影的封面
1、基本目标
2、思路
1、首先一些基本反爬措施:
2、如何得到直接链接?
3、保存到本地
4、main
3、效果
【爬虫】爬取影评并根据词频制作词云思路_Fx_2003的博客-CSDN博客
【爬虫】图片爬取思路_Fx_2003的博客-CSDN博客
1、基本目标
爬取最近上映电影的封面
2、思路
首先分析网页的结构找到图片的直接地址链接,并通过之前的博客“图片爬取思路”来保存到本地
1、首先一些基本反爬措施:
headers = {
'User-Agent': 'Mozilla/5.0 xxxxxx',
'Cookie': 'your Cookie xxxxxxx'
}2、如何得到直接链接?
我定义了下面这个函数来获取:
先看代码:
def getSrc():
url = "https://xxxxxxxxxx.com"
req = requests.get(url, headers=headers).content.decode("utf-8")
# print(req)
soup = BeautifulSoup(req, 'html.parser')
nowplaying = soup.find('div', id='nowplaying')
movie_list = nowplaying.find_all('img')
# print(movie_list)
imgDics = []
for imgUrl in movie_list:
imgDic = {'alt': imgUrl['alt'], 'src': imgUrl['src']}
print(imgDic)
imgDics.append(imgDic)
return imgDics
# print(imgDics)
再看网页结构,在要爬取的网页按F12
我们要爬取的“最近上映的”都在,id="nowplaying"下。所以
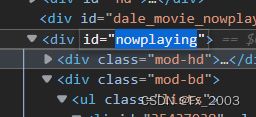
nowplaying = soup.find('div', id='nowplaying') #这样获取到nowplaying里的所有
而图片链接都在 img标签下的src中,所以我们先获取到img标签:
movie_list = nowplaying.find_all('img')
img标签下有alt,src,前者是电影名字,后者是链接,我们把每一个图片的信息用字典存放,所有的图片字典用一个列表存放
3、保存到本地
这里我给了两种方法(这个在博客”图片爬取思路“也有说)
- 第一种用的with open来写入二进制信息,文件名用alt下的电影名字来保存
- 第二种用
from PIL import Image
from io import BytesIO
来获取
第一种
def save_image1():
dics = getSrc()
for each in dics:
filename = r"H:/Project/PPython/ProjectQI/影评/img/{}.jpg".format(each['alt'])
req = requests.get(each['src'], headers=headers).content
with open(filename, "wb") as f:
print(each['src'])
f.write(req)
print(filename)
print('下载成功--{}'.format(each['alt']))第二种
def save_image2():
dics = getSrc()
for each in dics:
filename = r"H:/Project/PPython/ProjectQI/影评/img/{}.jpg".format(each['alt'])
req = requests.get(each['src'], headers=headers).content
a = Image.open(BytesIO(req))
a.save(r'H:/Project/PPython/ProjectQI/影评/img2/{}.jpg'.format(each['alt']))4、main
if __name__ == '__main__':
# url = input("输入网页图片直接地址")
# name = input("请输入您要保存图片的名字:")
save_image2()
print("下载完成!")
# print(getSrc())3、效果
在保存的地址上查看图片