一些特征融合技巧
文章目录
- 前言
- 一、一些特征融合方式
- 二、特征融合分类
- 三、晚融合方法归纳总结
-
- 1、[Feature Pyramid Network(FPN)](https://arxiv.org/abs/1612.03144)
- 2、[Path Aggregation Network for Instance Segmentation(PANet)](https://arxiv.org/abs/1803.01534)
- 3、[M2det: A single-shot object detector based on multi-level feature pyramid network(MLFPN)](https://arxiv.org/abs/1811.04533)
前言
目标检测中的特征融合技术。
一、一些特征融合方式
传统特征:像SPP net,Fast RCNN,Faster
RCNN是采用这种方式,即仅采用网络最后一层的特征。

图像金字塔:将原图片做成不同的尺寸,再进行特征提取,进行检测。可以在检测的时候尝试。
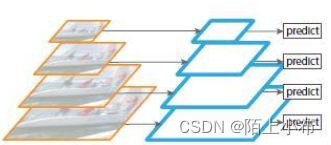
多尺度特征融合:像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。

特征金字塔(FPN):顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。

二、特征融合分类
-
在深度学习的很多工作中(例如目标检测、图像分割),融合不同尺度的特征是提高性能的一个重要手段。低层特征分辨率更高,包含更多位置、细节信息,但是由于经过的卷积更少,其语义性更低,噪声更多。高层特征具有更强的语义信息,但是分辨率很低,对细节的感知能力较差。如何将两者高效融合,取其长处,弃之糟泊,是改善分割模型的关键。
-
很多工作通过融合多层来提升检测和分割的性能,按照融合与预测的先后顺序,分类为早融合(Early fusion)和晚融合(Late fusion)。
-
早融合(Early fusion): 先融合多层的特征,然后在融合后的特征上训练预测器**(只在完全融合之后,才统一进行检测)。这类方法也被称为skip connection,即采用concat、add操作**。这一思路的代表是Inside-Outside Net(ION)和HyperNet。两个经典的特征融合方法:
(1)concat:系列特征融合,直接将两个特征进行连接。两个输入特征x和y的维数若为p和q,输出特征z的维数为p+q;
(2)add:并行策略,将这两个特征向量组合成复向量,对于输入特征x和y,z = x + iy,其中i是虚数单位。 -
晚融合(Late fusion):通过结合不同层的检测结果改进检测性能**(尚未完成最终的融合之前,在部分融合的层上就开始进行检测,会有多层的检测,最终将多个检测结果进行融合)**。这一类研究思路的代表有两种:
(1)feature不融合,多尺度的feture分别进行预测,然后对预测结果进行综合,如Single Shot MultiBox Detector (SSD) , Multi-scale CNN(MS-CNN)
(2)feature进行金字塔融合,融合后进行预测,如Feature Pyramid Network(FPN)等。
三、晚融合方法归纳总结
1、Feature Pyramid Network(FPN)
-
FPN(Feature Pyramid Network)算法同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,这和常规的特征融合方式不同。
-
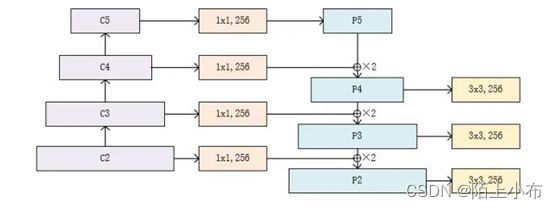
FPN将深层信息上采样,与浅层信息逐元素地相加,从而构建了尺寸不同的特征金字塔结构,性能优越,现已成为目标检测算法的一个标准组件。FPN的结构如下所示。
-
自下而上:最左侧为普通的卷积网络,默认使用ResNet结构,用作提取语义信息。C1代表了ResNet的前几个卷积与池化层,而C2至C5分别为不同的ResNet卷积组,这些卷积组包含了多个Bottleneck结构,组内的特征图大小相同,组间大小递减。
-
自上而下:首先对C5进行1×1卷积降低通道数得到P5,然后依次进行上采样得到P4、P3和P2,目的是得到与C4、C3与C2长宽相同的特征,以方便下一步进行逐元素相加。这里采用2倍最邻近上采样,即直接对临近元素进行复制,而非线性插值。
-
横向连接(Lateral Connection):目的是为了将上采样后的高语义特征与浅层的定位细节特征进行融合。高语义特征经过上采样后,其长宽与对应的浅层特征相同,而通道数固定为256,因此需要对底层特征C2至C4进行11卷积使得其通道数变为256,然后两者进行逐元素相加得到P4、P3与P2。由于C1的特征图尺寸较大且语义信息不足,因此没有把C1放到横向连接中。
-
卷积融合:在得到相加后的特征后,利用3×3卷积对生成的P2至P4再进行融合,目的是消除上采样过程带来的重叠效应,以生成最终的特征图。
-
FPN对于不同大小的RoI,使用不同的特征图,大尺度的RoI在深层的特征图上进行提取,如P5,小尺度的RoI在浅层的特征图上进行提取,如P2。FPN的代码实现如下:
import torch.nn as nn
import torch.nn.functional as F
import math
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.bottleneck = nn.Sequential(
nn.Conv2d(in_planes, planes, 1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, planes, 3, stride, 1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, self.expansion * planes, 1, bias=False),
nn.BatchNorm2d(self.expansion * planes),
)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
out = self.bottleneck(x)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class FPN(nn.Module):
def __init__(self, layers):
super(FPN, self).__init__()
self.inplanes = 64
self.conv1 = nn.Conv2d(3, 64, 7, 2, 3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(3, 2, 1)
self.layer1 = self._make_layer(64, layers[0])
self.layer2 = self._make_layer(128, layers[1], 2)
self.layer3 = self._make_layer(256, layers[2], 2)
self.layer4 = self._make_layer(512, layers[3], 2)
self.toplayer = nn.Conv2d(2048, 256, 1, 1, 0)
self.smooth1 = nn.Conv2d(256, 256, 3, 1, 1)
self.smooth2 = nn.Conv2d(256, 256, 3, 1, 1)
self.smooth3 = nn.Conv2d(256, 256, 3, 1, 1)
self.latlayer1 = nn.Conv2d(1024, 256, 1, 1, 0)
self.latlayer2 = nn.Conv2d( 512, 256, 1, 1, 0)
self.latlayer3 = nn.Conv2d( 256, 256, 1, 1, 0)
def _make_layer(self, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != Bottleneck.expansion * planes:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, Bottleneck.expansion * planes, 1, stride, bias=False),
nn.BatchNorm2d(Bottleneck.expansion * planes)
)
layers = []
layers.append(Bottleneck(self.inplanes, planes, stride, downsample))
self.inplanes = planes * Bottleneck.expansion
for i in range(1, blocks):
layers.append(Bottleneck(self.inplanes, planes))
return nn.Sequential(*layers)
def _upsample_add(self, x, y):
_,_,H,W = y.shape
return F.upsample(x, size=(H,W), mode='bilinear') + y
def forward(self, x):
c1 = self.maxpool(self.relu(self.bn1(self.conv1(x))))
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
p5 = self.toplayer(c5)
p4 = self._upsample_add(p5, self.latlayer1(c4))
p3 = self._upsample_add(p4, self.latlayer2(c3))
p2 = self._upsample_add(p3, self.latlayer3(c2))
p4 = self.smooth1(p4)
p3 = self.smooth2(p3)
p2 = self.smooth3(p2)
return p2, p3, p4, p5
2、Path Aggregation Network for Instance Segmentation(PANet)
- (1)、缩短信息路径和用低层级的准确定位信息增强特征金字塔,创建了自下而上的路径增强
- (2)、为了恢复每个建议区域和所有特征层级之间被破坏的信息,作者开发了适应性特征池化(adaptive feature pooling)技术,可以将所有特征层级中的特征整合到每个建议区域中,避免了任意分配的结果。
- (3)、全连接融合层:使用一个小型fc层用于补充mask预测
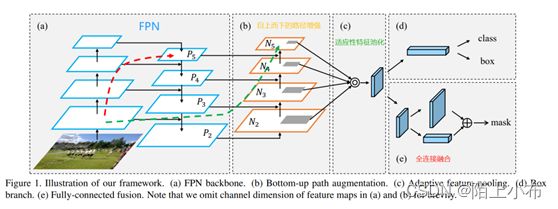
- 自下而上的路径增强
Bottom-up Path Augemtation的提出主要是考虑到网络的浅层特征对于实例分割非常重要,不难想到浅层特征中包含大量边缘形状等特征,这对实例分割这种像素级别的分类任务是起到至关重要的作用的。因此,为了保留更多的浅层特征,论文引入了Bottom-up Path Augemtation。
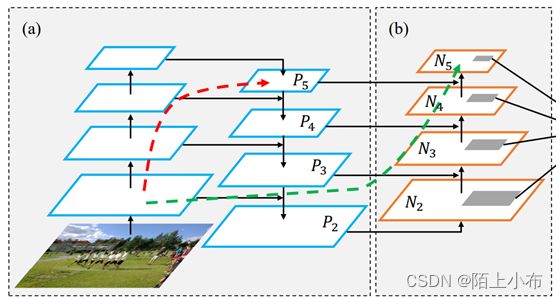
红色的箭头表示在FPN中,因为要走自底向上的过程,浅层的特征传递到顶层需要经过几十个甚至上百个网络层,当然这取决于BackBone网络用的什么,因此经过这么多层传递之后,浅层的特征信息丢失就会比较严重。
绿色的箭头表作者添加了一个Bottom-up Path Augemtation结构,这个结构本身不到10层,这样浅层特征经过原始FPN中的横向连接到P2然后再从P2沿着Bottom-up Path Augemtation传递到顶层,经过的层数不到10层,能较好的保存浅层特征信息。注意,这里的N2和P2表示同一个特征图。 但N3,N4,N5和P3,P4,P5不一样,实际上N3,N4,N5是P3,P4,P5融合后的结果。
Bottom-up Path Augemtation的详细结构如下图所示,经过一个尺寸为,步长为的卷积之后,特征图尺寸减小为原来的一半然后和这个特征图做add操作,得到的结果再经过一个卷积核尺寸为,的卷积层得到。
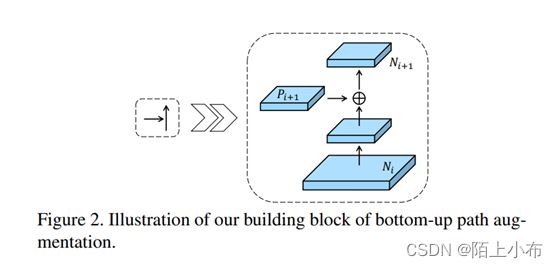
- Bottom-up Path Augemtation详细结构
- 适应性特征池化(adaptive feature pooling)
论文指出,在Faster-RCNN系列的标检测或分割算法中,RPN网络得到的ROI需要经过ROI Pooling或ROI Align提取ROI特征,这一步操作中每个ROI所基于的特征都是单层特征,FPN同样也是基于单层特征,因为检测头是分别接在每个尺度上的。
本文提出的Adaptive Feature Pooling则是将单层特征换成多层特征,即每个ROI需要和多层特征(论文中是4层)做ROI Align的操作,然后将得到的不同层的ROI特征融合在一起,这样每个ROI特征就融合了多层特征。
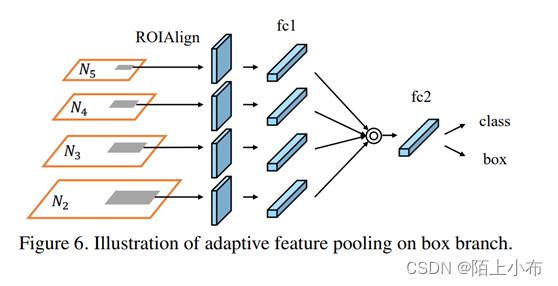
RPN网络获得的每个ROI都要分别和特征层做ROI Align操作,这样个ROI就提取到4个不同的特征图,然后将4个不同的特征图融合在一起就得到最终的特征,后续的分类和回归都是基于此最终的特征进行。
- 全连接融合层(Fully-Connected Fusion)
全连接融合层对原有的分割支路(FCN)引入一个前景二分类的全连接支路,通过融合这两条支路的输出得到更加精确的分割结果。这个模块的具体实现如图所示。
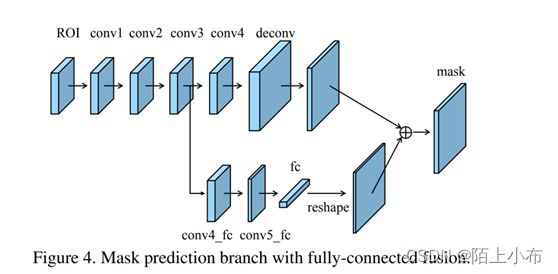
- Fully-Connected Fusion模块
从图中可以看到这个结构主要是在原始的Mask支路(即带deconv那条支路)的基础上增加了下面那个支路做融合。增加的这个支路包含个的卷积层,然后接一个全连接层,再经过reshape操作得到维度和上面支路相同的前背景Mask,即是说下面这个支路做的就是前景和背景的二分类,输出维度类似于文中说的。而上面的支路输出维度类似,其中代表数据集目标类别数。最终,这两条支路的输出Mask做融合以获得更加精细的最终结果。
3、M2det: A single-shot object detector based on multi-level feature pyramid network(MLFPN)
- 之前的特征金字塔目标检测网络共有的两个问题是:
(1)、原本 backbone 是用于目标分类的网络,导致用于目标检测的语义特征不足;
(2)、每个用于目标检测的特征层主要或者仅仅是由单级特征层(single-level layers)构成,也就是仅仅包含了单级信息;
这种思想导致一个很严重的问题,对分类子网络来说更深更高的层更容易区分,对定位的回归任务来说使用更低更浅的层比较好。此外,底层特征更适合描述具有简单外观的目标,而高层特征更适合描述具有复杂外观的目标。在实际中,具有相似大小目标实例的外观可能非常不同。例如一个交通灯和一个远距离的人可能具有可以比较的尺寸,但是人的外表更加复杂。因此,金字塔中的每个特征图主要或者仅仅由单层特征构成可能会导致次优的检测性能。
为了更好地解决目标检测中尺度变化带来的问题,M2det提出一种更有效的特征金字塔结构MLFPN, 其大致流程如下图所示:首先,对主干网络提取到的特征进行融合;然后通过TUM和FFM提取更有代表性的Multi-level&Mutli-scale特征;最后通过SFAM融合多级特征,得到多级特征金字塔用于最终阶段的预测。M2Det使用主干网络+MLFPN来提取图像特征,然后采用类似SSD的方式预测密集的包围框和类别得分,通过NMS得到最后的检测结果。
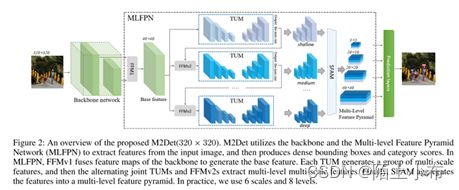
- 如上图所示,MLFPN主要有3个模块组成:
1)特征融合模块FFM;
2)细化U型模块TUM;
3)尺度特征聚合模块SFAM.
首先, FFMv1对主干网络提取到的浅层和深层特征进行融合,得到base feature;
其次,堆叠多个TUM和FFMv2,每个TUM可以产生多个不同scale的feature map,每个FFMv2融合base feature和上一个TUM的输出,并给到下一个TUM作为输入(更高level)。
最后,SFAM通过scale-wise拼接和channel-wise attention来聚合multi-level&multi-scale的特征。
- 特征融合模块FFM
FFM用于融合M2Det中不同级别的特征,先通过1x1卷积压缩通道数,再进行拼接。

FFM1 用于融合深层和和浅层特征,为 MLFPN 提供基本输入的特征层(Base Feature);由于 M2Det 使用了 VGG 作为 backbone,因此 FFM1 取出了 Conv4_3 和 Conv5_3 作为输入:FFMv1使用两种不同scale的feature map作为输入,所以在拼接操作之前加入了上采样操作来调整大小;
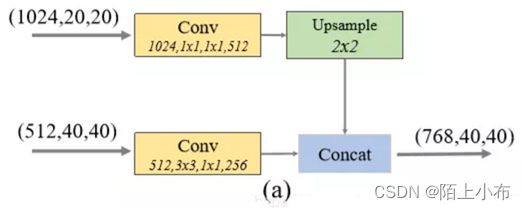
FFMv2用于融合 MLFPN 的基本输入(Base Feature)和上一个 TUM 模块的输出,两个输入的scale相同,所以比较简单。

- 细化U型模块TUM
TUM使用了比FPN和RetinaNet更薄的U型网络。在上采样和元素相加操作之后加上1x1卷积来加强学习能力和保持特征平滑度。TUM中每个解码器的输出共同构成了该TUM的multi-scale输出。每个TUM的输出共同构成了multi-level&multi-scale特征,前面的TUM提供low level feature,后面的TUM提供high level feature。
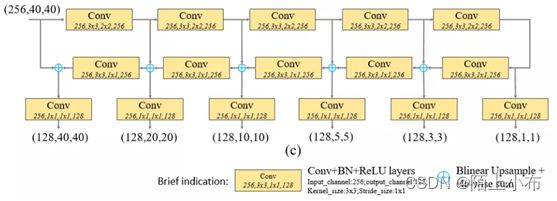
TUM 的编码器(encoder)使用 3×3 大小、步长为 2 的卷积层进行特征提取,特征图不断缩小;解码器(decoder)同过双线性插值的方法将特征图放大回原大小。
- 尺度特征聚合模块SFAM
SFAM旨在聚合TUMs产生的多级多尺度特征,以构造一个多级特征金字塔。在first stage,SFAM沿着channel维度将拥有相同scale的feature map进行拼接,这样得到的每个scale的特征都包含了多个level的信息。然后在second stage,借鉴SENet的思想,加入channel-wise attention,以更好地捕捉有用的特征。SFAM的细节如下图所示:

- 网络配置
M2Det的主干网络采用VGG-16和ResNet-101。
MLFPN的默认配置包含有8个TUM,每个TUM包含5个跨步卷积核5个上采样操作,所以每个TUM的输出包含了6个不同scale的特征。
在检测阶段,为6组金字塔特征每组后面添加两个卷积层,以分别实现位置回归和分类。
后处理阶段,使用soft-NMS来过滤无用的包围框。