推荐算法理论 :协同过滤
前文 万字入门推荐系统 提到了后续内容围绕两大系列:推荐算法理论+新闻推荐实战。
 推荐算法理论
推荐算法理论
本文是推荐算法理论系列的第一篇文章, 还是想从最经典的协同过滤算法开始。虽然有伙伴可能觉得这个离我们比较久远,并且现在工业界也很少直接用到原始的协同过滤, 但协同过滤的思想依然是非常强大,因为它借助于群体智能智慧,仅仅基于用户与物品的历史交互行为,就可以发掘物品某种层次上的相似关系或用户自身的偏好。这个过程中,可以不需要太多特定领域的知识,可以不需要物品画像或用户画像本身的特征,可以采用简单的工程实现,就能非常方便的应用到产品中。所以作为推荐算法"鼻祖",我们还是非常有必要先来了解一下这个算法的。
所谓协同过滤(Collaborative Filtering)算法,基本思想是通过用户的行为去挖掘某种相似性(用户之间的相似或者物品之间的相似), 通过相似性为用户做决策和推荐, 这其中,仅仅是用户的行为数据(评价,购买,加载等),而不依赖于任何附加信息(物品自身特征和用户自身特征)。目前应用比较广泛的协同过滤算法是基于邻域的方法, 主要是下面两种:
基于用户的协同过滤算法(UserCF): 给用户推荐和他兴趣相似的其他用户喜欢的产品(人以类聚)
基于物品的协同过滤算法(ItemCF): 给用户推荐和他之前喜欢的物品相似的物品(物以群分)
所以这篇文章主要是详细介绍这两种方法,从基本思想到原理,最后再进行一个编程的例子实战。
主要内容如下:
基于用户的协同协同过滤
基于物品的协同过滤算法
应用场景及存在问题分析
1. 基于用户的协同过滤
基于用户的协同过滤(UserCF)可以追溯到1993年, 可以说是非常早的一种算法了, 这种算法的思想其实比较简单, 当一个用户A需要个性化推荐的时候, 我们可以先找到和他有相似兴趣的其他用户, 然后把那些用户喜欢的, 而用户A没有听说过的物品推荐给A。

所以基于用户的协同过滤算法主要包括两个步骤:
找到和目标用户兴趣相似的用户集合
找到这个用户集合中用户喜欢的, 且目标用户没有听说过的物品推荐给用户。
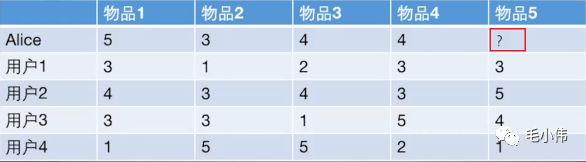
如果这样说比较抽象的话, 我们可以看一个例子, 了解一下给用户推荐物荐到底是怎么推荐的, 看下面这个表格:
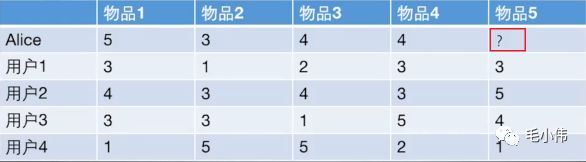 在这里插入图片描述
在这里插入图片描述
给用户推荐物品的过程可以形象化为一个猜测用户对商品进行打分的任务,上面表格里面是5个用户对于5件物品的一个打分情况,就可以理解为用户对物品的喜欢程度(这里多说一句,这种表格在实际情况中就是根据用户的行为进行统计出来的, 比如用户购买了某个物品, 那直接量化为5分, 用户收藏了某个物品, 量化为4分, 用户看某个物品很久量化为3分等, 通过这样的量化就相当于把每个用户对物品的行为刻画成了数字的形式, 方便我们计算相似), 我们的任务是判断到底该不该把物品5推荐给用户Alice呢?
如果是基于用户的协同过滤算法, 根据上面的算法步骤, 其实它会这么做:
首先根据前面的这些打分情况(或者说已有的用户向量)计算一下Alice和用户1, 2, 3, 4的相似程度, 找出与Alice最相似的n个用户
根据这n个用户对物品5的评分情况和与Alice的相似程度猜测出Alice对物品5的评分, 如果评分比较高的话, 就把物品5推荐给用户Alice, 否则不推荐。
所以这个过程相信很容易理解,但你心里一定至少有两个疑问,第一个是我怎么找与Alice最相似的用户, 这种用户之间的相似性怎么衡量?第二个是如果我选出了n个与Alice最相似的用户,那么我如何基于这n个用户对物品5的评分去猜测Alice对物品5的评分呢?
下面我们一一来解答。
首先是用户之间的相似性衡量问题, 这个在具体解答之前,需要补充衡量两个向量相似度的知识。
1.1 计算两个向量之间的相似程度
计算相似度需要根据特点的不同选择不同的相似度计算方法, 比较常用的有下面几种:
杰卡德(Jaccard)相似系数 这个是衡量两个集合的相似度一种指标。 两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示。
余弦相似度 余弦相似度衡量了用户向量和之间的向量夹角的大小, 夹角越小, 说明相似度越大, 两个用户越相似。 公式如下:
这里面是向量表示的, 如果不太明白的话, 可以换成具体的数值表示, 假设两个用户的向量是维的, 分别是, 那么余弦相似度为:
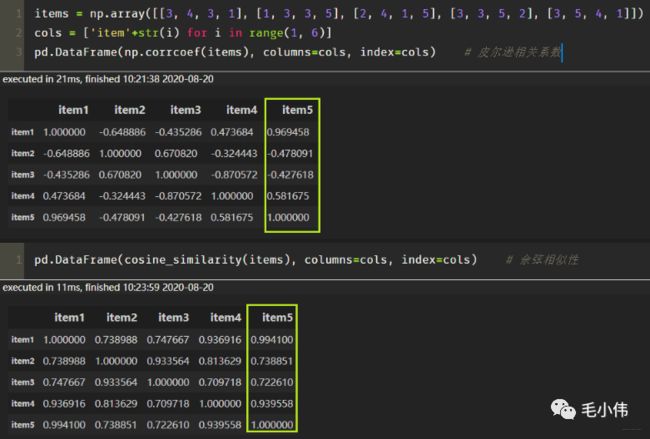
这个在具体实现的时候, 可以使用
cosine_similarity进行实现:from sklearn.metrics.pairwise import cosine_similarity i = [1, 0, 0, 0] j = [1, 0.5, 0.5, 0] consine_similarity([a, b])cosine相似度还是比较常用的, 一般效果也不会太差, 但是对于评分数据不规范的时候, 也就是说, 存在有的用户喜欢打高分, 有的用户喜欢打低分情况的时候,有的用户喜欢乱打分的情况, 这时候consine相似度算出来的结果可能就不是那么准确了, 比如下面这种情况:
 在这里插入图片描述
在这里插入图片描述 这时候, 如果用余弦相似度进行计算, 会发现用户d和用户f比较相似, 而实际上, 如果看这个商品喜好的一个趋势的话, 其实d和e比较相近, 只不过e比较喜欢打低分, d比较喜欢打高分。所以对于这种用户评分偏置的情况, 余弦相似度就不是那么好了, 可以考虑使用下面的皮尔逊相关系数。
皮尔逊相关系数 这个也是非常常用的一种计算相似度的一种方式, 相比余弦相似度, 皮尔逊相关系数通过使用用户平均分对个独立评分进行修正, 减少了用户评分偏置的影响。简单的说, pearson做的就是把两个向量都减去他们的均值, 然后再计算consine值。用pearson来计算用户相似进行推荐的话, 效果还是好于consine的。公式如下:
这个式子里面其实就是每个向量先减去了它的平均值, 然后在计算余弦相似度, 其中代表用户对物品的评分。代表用户对所有物品的平均评分, 代表所有物品的集合, 表示某个物品。具体实现, 我们也是可以调包, 这个计算方式很多, 下面是其中的一种:
from scipy.stats import pearsonr i = [1, 0, 0, 0] j = [1, 0.5, 0.5, 0] pearsonr(i, j)
我们可以把用户对于所有物品的交互行为打分看成一个向量, 来表示该用户对于物品的一种行为偏好,这样,我们就可以通过上面计算向量相似度的公式,去衡量每个用户之间的偏好相似程度。第一个问题解决。
.2 最终结果的预测
根据上面的几种方法, 我们可以计算出向量之间的相似程度, 也就是可以计算出Alice和其他用户的相近程度, 这时候我们就可以选出与Alice最相近的前n个用户, 基于他们对物品5的评价猜测出Alice的打分值, 那么是怎么计算的呢?
这里常用的方式之一是利用用户相似度和相似用户的评价加权平均获得用户的评价预测, 用下面式子表示:
这个式子里面, 权重是用户和用户的相似度, 是用户对物品的评分。
还有一种方式如下, 这种方式考虑的更加全面, 依然是用户相似度作为权值, 但后面不单纯的是其他用户对物品的评分, 而是该物品的评分与此用户的所有评分的差值进行加权平均, 这时候考虑到了有的用户内心的评分标准不一的情况, 即有的用户喜欢打高分, 有的用户喜欢打低分的情况。
所以这一种计算方式更为推荐。下面的计算将使用这个方式。这里的是用户和用户的相似度, 和上面的代表的是一个意思。
在获得用户对不同物品的评价预测后, 最终的推荐列表根据预测评分进行排序得到。至此, 基于用户的协同过滤算法的推荐过程完成。
1.3 拿上面例子看一下
下面我们解决上面的问题, 把图拿过来:
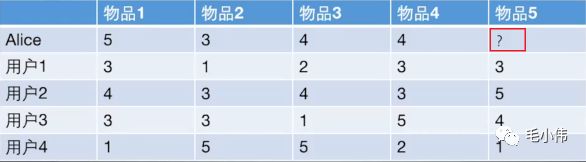 在这里插入图片描述
在这里插入图片描述
猜测Alice对物品5的得分:
计算Alice与其他用户的相似度(这里使用皮尔逊相关系数)
 在这里插入图片描述
在这里插入图片描述
这里我们使用皮尔逊相关系数, 也就是Alice与用户1的相似度是0.85。同样的方式, 我们就可以计算与其他用户的相似度, 这里可以使用numpy的相似度函数得到用户的相似性矩阵:
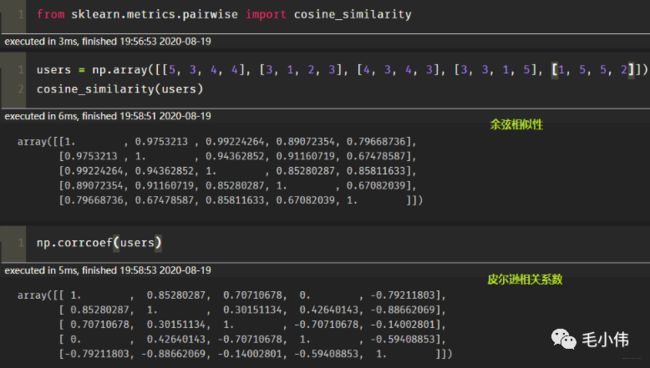 在这里插入图片描述
在这里插入图片描述
从这里看出, Alice用户和用户2, 用户3, 用户4的相似度是0.7, 0, -0.79。所以如果n=2, 找到与Alice最相近的两个用户是用户1, 和Alice的相似度是0.85, 用户2, 和Alice相似度是0.7
根据相似度用户计算Alice对物品5的最终得分 用户1对物品5的评分是3, 用户2对物品5的打分是5, 那么根据上面的计算公式, 可以计算出Alice对物品5的最终得分是
根据用户评分对用户进行推荐 这时候, 我们就得到了Alice对物品5的得分是4.87, 根据Alice的打分对物品排个序从大到小:
物品物品物品物品物品
这时候,如果要向Alice推荐2款产品的话, 我们就可以推荐物品1和物品5给Alice。
至此, 基于用户的协同过滤算法原理介绍完毕。基于用户协同过滤算法的代码,由于篇幅原因,这里就不放了,感兴趣的可以参考我们的fun-rec项目[基于用户的协同过滤代码](fun-rec/UserCF.py at master · datawhalechina/fun-rec · GitHub)
1.4优缺点
User-based算法存在两个重大问题:
数据稀疏性。一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。这导致UserCF不适用于那些正反馈获取较困难的应用场景(如酒店预订, 大件商品购买等低频应用)
算法扩展性。基于用户的协同过滤需要维护用户相似度矩阵以便快速的找出Topn相似用户, 该矩阵的存储开销非常大,存储空间随着用户数量的增加而增加,不适合用户数据量大的情况使用。
由于UserCF技术上的两点缺陷, 导致很多电商平台并没有采用这种算法, 而是采用了ItemCF算法实现最初的推荐系统。
2. 基于物品的协同过滤
基于物品的协同过滤(ItemCF)的基本思想是预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户喜欢的物品相类似的物品推荐给用户。比如物品a和c非常相似,因为喜欢a的用户同时也喜欢c,而用户A喜欢a,所以把c推荐给用户A。ItemCF算法并不利用物品的内容属性计算物品之间的相似度, 主要通过分析用户的行为记录计算物品之间的相似度, 该算法认为, 物品a和物品c具有很大的相似度是因为喜欢物品a的用户大都喜欢物品c。
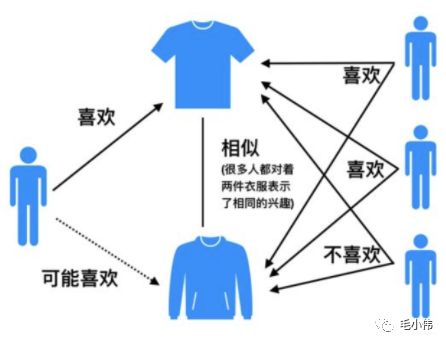 在这里插入图片描述
在这里插入图片描述
基于物品的协同过滤算法主要分为两步:
计算物品之间的相似度
根据物品的相似度和用户的历史行为给用户生成推荐列表(购买了该商品的用户也经常购买的其他商品)
2.1 还是前面的例子
基于物品的协同过滤算法和基于用户的协同过滤算法很像, 所以我们这里直接还是拿上面Alice的那个例子来看。
 在这里插入图片描述
在这里插入图片描述
如果想知道Alice对物品5打多少分, 基于物品的协同过滤算法会这么做:
首先计算一下物品5和物品1, 2, 3, 4之间的相似性(它们也是向量的形式, 每一列的值就是它们的向量表示, 因为ItemCF认为物品a和物品c具有很大的相似度是因为喜欢物品a的用户大都喜欢物品c, 所以就可以基于每个用户对该物品的打分或者说喜欢程度来向量化物品,可以理解成该物品被用户喜欢程度)
找出与物品5最相近的n个物品
根据Alice对最相近的n个物品的打分去计算对物品5的打分情况
下面我们就可以具体计算一下, 首先是步骤1:
 由于计算比较麻烦, 这里直接用python计算了:
由于计算比较麻烦, 这里直接用python计算了:
 根据皮尔逊相关系数, 可以找到与物品5最相似的2个物品是item1和item4(n=2), 下面基于上面的公式计算最终得分:
根据皮尔逊相关系数, 可以找到与物品5最相似的2个物品是item1和item4(n=2), 下面基于上面的公式计算最终得分:
这时候依然可以向Alice推荐物品5。
至此, 基于物品的协同过滤算法原理介绍完毕。
同样的, 基于物品的协同过滤算法代码,可以参考[这里](fun-rec/ItemCF.py at master · datawhalechina/fun-rec · GitHub)。
2.2优缺点分析
上面说UserCF存在两个问题, 数据稀疏性和算法扩展性问题, 而ItemCF算法因为物品直接的相似性相对比较固定,所以可以预先在线下计算好不同物品之间的相似度,把结果存在表中,当推荐时进行查表,计算用户可能的打分值,可以同时解决上面两个问题。在Item-to-Item论文中, 作者得出结论:
Item-based算法的预测结果比User-based算法的质量要高一点。
由于Item-based算法可以预先计算好物品的相似度,所以在线的预测性能要比User-based算法的高。
用物品的一个小部分子集也可以得到高质量的预测结果。
至于存在的问题, 应该是CF存在的共性问题了, 放在下面一块讨论。
3. 应用场景和存在问题分析
3.1 应用场景
这里首先介绍UserCF和ItemCF的应用场景, 因为其原理不同, 应用上也会有所区别。
UserCF 由于是基于用户相似度进行推荐, 所以具备更强的社交特性, 这样的特点非常适于用户少, 物品多, 时效性较强的场合, 比如新闻推荐场景, 因为新闻本身兴趣点分散, 相比用户对不同新闻的兴趣偏好, 新闻的及时性,热点性往往更加重要, 所以正好适用于发现热点,跟踪热点的趋势。另外还具有推荐新信息的能力, 更有可能发现惊喜, 因为看的是人与人的相似性, 推出来的结果可能更有惊喜,可以发现用户潜在但自己尚未察觉的兴趣爱好。
对于用户较少, 要求时效性较强的场合, 就可以考虑UserCF。ItemCF 这个更适用于兴趣变化较为稳定的应用, 更接近于个性化的推荐, 适合物品少,用户多,用户兴趣固定持久, 物品更新速度不是太快的场合, 比如推荐艺术品, 音乐, 电影。
下面是UserCF和ItemCF的优缺点对比:(来自项亮推荐系统实践)
 在这里插入图片描述
在这里插入图片描述
3.2 问题分析
这里分析一下协同过滤算法存在的共性问题, 协同过滤的特点就是完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息就可以实现推荐,是一个可解释性很强, 非常直观的模型, 但是也存在一些问题。
3.2.1 较差的稀疏向量处理能力
第一个问题就是泛化能力弱, 即协同过滤无法将两个物品相似的信息推广到其他物品的相似性上。 导致的问题是热门物品具有很强的头部效应, 容易跟大量物品产生相似, 而尾部物品由于特征向量稀疏, 导致很少被推荐。比如下面这个例子:
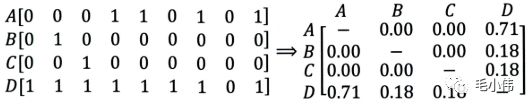 在这里插入图片描述
在这里插入图片描述
A, B, C, D是物品, 看右边的物品共现矩阵, 可以发现物品D与A、B、C的相似度比较大, 所以很有可能将D推荐给用过A、B、C的用户。但是物品D与其他物品相似的原因是因为D是一件热门商品, 系统无法找出A、B、C之间相似性的原因是其特征太稀疏, 缺乏相似性计算的直接数据。所以这就是协同过滤的天然缺陷:推荐系统头部效应明显, 处理稀疏向量的能力弱。
为了解决这个问题, 同时增加模型的泛化能力,2006年, 矩阵分解技术(Matrix Factorization,MF)被提出, 该方法在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品, 挖掘用户和物品的隐含兴趣和隐含特征, 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。后面有机会也会整理一下矩阵分解,这里先做一个铺垫。
3.2.2 无法利用更多的信息
协同过滤的特点就是完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息就可以实现推荐,比较简单高效, 但这也是它的一个短板所在, 由于无法有效的引入用户年龄, 性别,商品描述,商品分类,当前时间,地点等一系列用户特征、物品特征和上下文特征, 这就造成了有效信息的遗漏,不能充分利用其它特征数据。
为了解决这个问题, 在推荐模型中引用更多的特征, 推荐系统慢慢的从以协同过滤为核心到了以逻辑回归模型为核心, 提出了能够综合不同类型特征的机器学习模型。
4. 总结
这篇文章围绕着推荐系统比较经典的协同过滤算法进行的展开, 这个算法虽然比较古老, 但是思想和原理还是值得我们研究, 毕竟这个算法不依赖于任何物品本身或者用户自身的属性, 而仅仅靠用户和物品的交互信息就可以完成推荐任务, 所以还是非常powerful的, 并且后面的很多算法都是基于该算法存在的问题进行的改进, 比如矩阵分解算法, 解决了其泛化能力和稀疏能力弱的问题, LR或者GBDT+LR那些机器学习模型解决了无法利用其它用户属性, 物品属性和上下文属性的问题, 即使近几年的深度学习模型, 也都是在前面的那些模型上进行改进过来的。如果把推荐系统模型的发展看成一棵树, 协同过滤算法可是当之无愧的根。
协同过滤算法比较常用的是基于邻域的方法, 主要包括UserCF和ItemCF, 这篇文章首先介绍了它们的原理,UserCF的基本思想是如果用户A喜欢物品a,用户B喜欢物品a、b、c,用户C喜欢a和c,那么认为用户A与用户B和C相似,因为他们都喜欢a,而喜欢a的用户同时也喜欢c,所以把c推荐给用户A。该算法用最近邻居(nearest-neighbor)算法找出一个用户的邻居集合,该集合的用户和该用户有相似的喜好,算法根据邻居的偏好对该用户进行预测。而ItemCF的基本思想是如果用户A, 用户B喜欢物品a, 物品c, 用户C喜欢物品a, 那么就认为物品a和物品c相似,因为用户C喜欢物品a, 所以也可以把物品c推荐给C。
然后从一个例子出发进行解释这两种算法。最后分析了它们各自的优缺点和应用场景, UserCF比较适用于实时性强的任务, 偏向于社会化推荐, 容易推进出新事物, 而ItemCF比较适合推荐兴趣比较固定的产品, 偏向于个性化推荐,推荐的大都类似产品。
参考:
王喆 - 深度学习推荐系统
项亮 - 推荐系统实践
协同过滤推荐算法的原理及实现
协同过滤推荐算法总结
【推荐系统算法实战】协同过滤 CF 算法(Collaborative Filtering)
机器学习中的相似性度量
协同过滤算法(collaborative filtering)
论文:
Using collaborative filtering to weave an information tapestry, 1992
Item-to-Item collaborative filtering, 2003
转自:毛小伟 微信公众号;
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。