鸟哥Linux私房菜:第七章笔记
第七章:Linux磁盘与文件系统管理
- 7.1 认识Linux文件系统
-
- 文件系统特性
- Linux的Ext2文件系统
-
- 1. data block
- 2. inode table
- 3. Superblock
- 4. Filesystem Description
- 5. block bitmap(区块对照表)
- 6. inode bitmap(inode对照表)
- dumpe2fs
- 与目录树的关系
- EXT2/EXT3/EXT4 文件的存取与日志式文件系统的功能
-
- 日志式文件系统
- Linux文件系统的运行
- 挂载点(mount point)的意义
- 其他Linux支持的文件系统和VFS
- XFS文件系统简介
- 7.2 文件系统的简单操作
-
- 磁盘与目录的容量
- 实体链接与符号链接:ln
- 7.3 磁盘的分区、格式化、检验与挂载
-
- 观察磁盘分区状态
- 磁盘分区:gdisk/fdisk
- 磁盘格式化(创建文件系统)
- 文件系统校验
- 文件系统挂载与卸载
- 磁盘/文件系统参数修订
- 7.4 设置开机挂载
- 7.5 内存交换空间(swap)之创建
-
- 使用实体分区创建swap
- 使用文件创建swap
- 课后习题
7.1 认识Linux文件系统
文件系统特性
磁盘分区后要进行“格式化”,是因为:每种操作系统设置的文件属性/权限并不同,为了存放这些文件所需的数据,因此就需要将分区进行格式化,以成为操作系统能够利用的“文件系统格式(filesystem)”。
所以我们也能知道:不同操作系统能使用的文件系统也是不同的。
文件系统一般有inode, block, superblock等区块。每个inode和block都有编号。
superblock:记录filesystem的整体信息,包括inode/block的信息和文件系统的相关信息。
inode:记录文件的属性,一个文件占用1个inode,也记录文件数据所在block的号码。
block:记录文件的实际内容。一个文件如果过大可使用多个block。
所以找到了文件的inode,就可以知道文件的实际内容。这种数据存取方式称为索引式文件系统(indexed allocation)。

还有一种是inode只存储第一个block的编号,下一个block的编号存储在上一个block中。这样读取文件太麻烦。
Linux使用的Ext2是索引式文件系统。
Linux的Ext2文件系统
当文件系统过大时,将所有inode和block都放在一起并不容易管理,所以Ext2文件系统在格式化时会区分多个区块群组(block group),每个区块群组都有自己独立的 inode/block/superblock系统。

每一个block group的6个主要内容有:
1. data block
data block:用来放置文件内容数据的地方。
Ext2文件系统中的block大小有1K, 2K, 4K三种,格式化时block大小已固定且有编号。
block的限制:
block在格式化后大小与数量就不能再改了(除非重新格式化);
每个block内最多只能放置1个文件的内容(文件过大可以使用多个block,但block有剩空间不能给别的文件使用)。
2. inode table
inode会记录文件的属性和文件实际数据存放在哪些block里。inode记录的文件数据至少有:
文件的存取模式(read/write/excute);文件的拥有者和群组;文件的容量;ctime、atime、mtime;文件真正内容的指向(pointer)等。
inode数量和大小在格式化时也是固定了,每个innode大小固定为128Bytes,且每个文件只占用1个inode。
系统读取文件时要先找到inode,分析inode记录的权限和使用者是否符合,若符合才开始实际读取block的内容。
inode只固定有128Bytes,它记录一个block号码需要4Bytes。如果只是直接记录的话,文件过大时inode就记录不下了。所以系统将inode记录block的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区:
所谓直接,就是inode里直接存放记录文件内容的block的编码;间接,就是用一个block来当作记录block编码的记录区,然后inode里存放这个block的编码;双间接,就是inode记录第一个block的编码,第一个block记录第二个block的编码,记录存储文件实际内容的block编码的是在第二个block中。
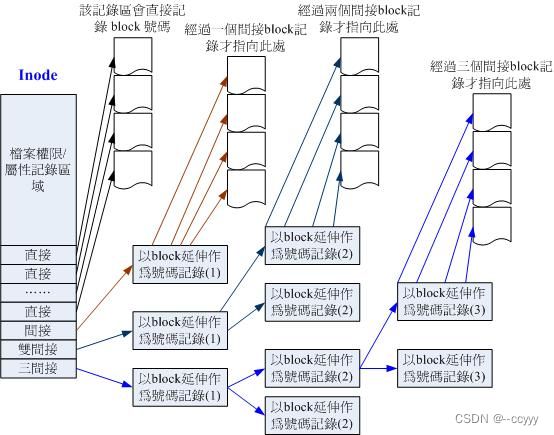
举例计算一下这样的inode能指定多大的文件:
假设block大小为1K,
12个直接指向:12x1K=12K;
间接:每笔block号码的记录会用4Bytes,所以1K能记录256笔数据,所以是256x1K=256K;
双间接:类似间接,256x256x1K;
三间接:256x256x256x1K;
所以总额是:12+256+256x256+256x256x256(K)=16GB
3. Superblock
它是记录整个filesystem相关信息的地方。记录了:
block和inode的总量、使用/未使用量;
block和inode的大小;
filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘 (fsck) 的时间等文件相关信息;
文件系统是否已被挂载(valid bit=1/0)。
一般一个文件系统只有一个Superblock(在第一个block group里),如果后面的block group也有,则是为了做备份(因为Superblock记录整个文件系统的信息,非常重要)。
4. Filesystem Description
这个区段可以描述每个 block group 的开始与结束的 block 号码,以及说明每个区段(superblock, bitmap, inodemap, data block) 分别介于哪一个 block 号码之间。
5. block bitmap(区块对照表)
记录使用与未使用的block号码。
如果删除某些文件,则这些文件对应的block号码的标志就要修改为“未使用中”。
6. inode bitmap(inode对照表)
记录使用与未使用的inode号码。
dumpe2fs
blkid # 这个指令可以得到系统有被格式化的设备,找出TYPE是Ext家族的设备来试指令
dumpe2fs 设备文件名
这个指令可以查询Ext家族superblock信息。
与目录树的关系
用文件系统创建一个目录时,文件系统会分配给目录一个inode和至少一个block。inode 记录该目录的相关权限与属性,并可记录分配到的那块 block 号码;而 block 则是记录在这个目录下的文件名与该文件名占用的inode号码数据。
要查看文件夹里的文件占用的inode号码,可以使用 ls -i:
ls -li
目录的inode本身并不记录文件名,是目录的block在记录。所以增/删/改名是跟目录的w权限有关。
目录树从根目录开始读起,先通过挂载的信息找到挂载点的inode号码,由此得到根目录的inode内容,再根据inode读取根目录的block的文件名数据,再一层层往下读到文件名。
比如读取/etc/passwd的文件,读取流程是:
/的inode -> /的block -> etc/的inode(使用者要有r和x权限才可以往下读) -> etc/的block -> passwd的inode(使用者要有r权限才可以往下读) -> passwd的block。
EXT2/EXT3/EXT4 文件的存取与日志式文件系统的功能
如果要新增一个文件或目录,文件系统的工作是:
- 确定使用者对该目录是否有w和x的权限;
- 根据inode bitmap找到未使用的inode号码,将新文件的权限和属性写入;
- 根据block bitmap找到未使用的block号码,将实际数据写入block,并更新 inode 的 block 指向数据;
- 更新inode bitmap和block bitmap和superblock的内容。
一般将inode table和data block称为数据存放区域,superblock、block bitmap 与 inode bitmap 等区段就被称为 metadata (中介数据)。
日志式文件系统
数据不一致状态:如果系统因故中断,可能会导致只写入了inode table和data block,而没有改变metadata的内容,这样就会导致metadata内容与实际数据存放不一致的情况。
早期的Ext2文件系统在开机时会进行数据一致性的检查,但是这样要针对metadata区域与实际数据存放区域来进行比对,费时。
所以出现了日志式文件系统(Journaling filesystem)。文件系统会划分出一个区块专门记录写入或修改文件时的步骤,从而简化了一致性的检查。
- 预备:系统要写入文件时,会先在日志记录区块中记录某个文件准备要写入的信息;
- 实际写入:写入文件的权限和数据,同时更新metadata的数据;
- 结束:完成写入后,在日志记录区块当中完成该文件的记录。
Linux文件系统的运行
磁盘写入/读取的速度要比内存慢很多,为了解决这个效率问题,Linux使用的方式是非同步处理(asynchronously):
当系统载入一个文件到内存后,如果文件没有被改动过,则设置为干净(clean)的,否则是脏的(dirty)。系统会不定期将dirty的数据写回磁盘。也可以用 sync 指令手动强迫写入磁盘。关机指令会主动调用sync指令。
内存的速度比磁盘快很多,所以系统会将常用的文件数据放置到内存的缓冲区。
挂载点(mount point)的意义
一个文件系统要能够链接到目录树才能被我们使用。 将文件系统与目录树结合的动作我们称为“挂载”。注意:挂载点一定是目录,该目录为进入该文件系统的入口。
其他Linux支持的文件系统和VFS
要想知道 Linux 支持的文件系统有哪些,可以查看下面的目录:
ls -l /lib/modules/$(uname -r)/kernel/fs
查看内核支持的文件系统:
cat /proc/filesystems
整个Linux系统是使用Virtual Filesystem Switch(VFS)的核心功能去读取 filesystem 的,也就是说VFS管理着系统的filesystem。
XFS文件系统简介
由于Ext文件系统格式化需要划分好所有inode/block/metadata等数据,所以遇到大容量磁盘和巨型文件格式化会非常慢。
为了提高效率,会使用XFS系统。
XFS是一个日志式文件系统,数据分布主要分为三部分:一个数据区(data section)、一个文件系统活动登录区(log section)以及一个实时运行区 (realtime section)。
1. 数据区:
类似于ext家族,这个区块包括inode/data block/superblock等数据。它也分为多个存储区群组(allocation groups)。每个group包含了:(1)文件系统的superblock;(2)剩余空间的管理机制;(3)inode的分配与追踪。
它与ext家族不同的一点在于:inode和block都是在系统要用到时才动态配置产生(所以格式化更快),且inode和block的容量不是固定的。
2. 文件系统活动登录区:
主要用来记录文件系统的变化。
因为系统所有动作都会在这个区块记录,所以这个区块的磁盘活动频繁。可以指定外部磁盘来作为这个区块,比如SSD磁盘,这样工作更快。
3. 实时运行区:
当有文件要被创建时,xfs会在这个区段里找一个或多个extent区块,将文件放置在这里。等到分配完毕后,再写到inode和block里。
extent区块的大小在格式化的时候就指定。
用 xfs_info 指令查看superblock的内容。
xfs_info 设备文件名
例:
# df指令查看文件系统磁盘使用情况,参数-T显示文件系统的格式
df -T /root
# 从上面指令的输出得知设备文件名是/dev/vda2
xfs_info /dev/vda2
7.2 文件系统的简单操作
磁盘与目录的容量
df [参数] [目录或文件名] # 列出文件系统的整体磁盘使用量
du [参数] [目录或文件名] # 列出文件系统的磁盘使用量
实体链接与符号链接:ln
格式:
ln [-sf] 来源文件 目标文件
# 参数-s:没有这个参数就是建立hard link,有就是建立symbolic link
# 参数-f:如果目标文件存在,则将存在的文件移除后再创建
1. Hard Link(实体/实际/硬式链接):
一个文件占用一个inode,而hard link就是实现多个文件名对应一个inode,也就是把多个文件名链接到同一个inode,这多个文件名的所有相关信息都是一模一样的。
例如:
ll -i /etc/crontab
# 在root下,建立/root/crontab为/etc/crontab的hard link
# 格式:ln 原文件 hardlink
ln /etc/crontab .
ll -i /etc/crontab crontab
# 从输出可以看出两个文件的信息一模一样
示意图:

图的意思是:可以通过1或2的目录的inode指定的block找到2个不同的文件名,它们都可以指向real这个inode从而读取到同样的数据。无论用哪个文件名来编辑文件,最终结果都会写入到相同的inode和block里。
一般来说,使用hard link设置链接文件时,inode数目与磁盘空间不会改变。它只是在block中多写入了一个关联数据。而由于block里要写入内容,如果block满了,是有可能增加block数目的。而增加的block数目一般很小,所以一般不会影响到inode和磁盘。
hard link的限制:
(1)不能跨文件系统;(2)不能link目录。(第2点主要是因为如果建立了链接,那么目录下的文件都要建立,太复杂。)
2. Symbolic Link(符号链接):
它就是文件会让数据的读取指向文件link的那个文件的文件名,只用文件来做指向动作。示意图如下:

# ln -s表示建立符号链接
ln -s /etc/crontab crontab2
ll -i /etc/crontab /root/crontab2
# 从输出可以看出两个文件的信息是不同的,且/root/crontab2的文件大小刚好是/etc/crontab的字符数
如果建立的是符号链接,那么当目标文件(例如/etc/crontab)被删除,就无法通过链接读取文件了。如果建立的是实际链接,如果删除了/etc/crontab,它只是把/etc下关于crontab的关连数据拿掉,crontab所在的inode和block并没有改变,仍然可以通过/root/crontab访问文件内容。
关于目录的link数量:
当我们以hard link建立文件链接时,文件的链接数会加1。
而当我们创建一个新的目录时,新目录link数为2,上层目录link数加1。这是因为:一个新目录基本有3样东西(举例新目录叫/tmp/test):/tmp/test,/tmp/test/. ,/tmp/test/. . 。其中/tmp/test和/tmp/test/.是一样的,都代表本目录;/tmp/test/. .则代表/tmp这个目录。
7.3 磁盘的分区、格式化、检验与挂载
在系统里新增一块磁盘时,要做:
- 对磁盘分区,创建可用的patition;
- 对patition进行格式化,以创建系统可用的filesystem;
- 对刚创建好的filesystem进行检验;
- 在Linux系统上创建挂载点,并将它挂载上来。
观察磁盘分区状态
一:lsblk (list block device) 列出系统上的所有磁盘列表
lsblk [参数] [device]
默认输出信息有:
NAME:设备文件名;
MAJ:MIN:主要:次要设备代码;
RM:是否为可卸载设备;
SIZE:容量;
RO:是否为只读设备;
TYPE:是磁盘 (disk)、分区 (partition) 还是只读存储器 (rom) 等输出;
MOUTPOINT:挂载点。
二:blkid列出设备的UUID等参数
UUID是是全域单一识别码(universally unique identifier),每个设备有独一无二的识别码。
blkid
输出的每一行代表一个文件系统,列出设备名称、UUID名称和文件系统的类型。
三、parted列出磁盘的分区表类型与分区信息
parted 设备名字 print
磁盘分区:gdisk/fdisk
MBR分区用fdisk进行分区,GPT用gdisk进行分区。
首先要通过lsblk和blkid找到磁盘,再通过parted指令得到分区表类型是MBR还是GBT,之后采用gdisk/fdisk进行分区。
以gbisk为例:
gdisk 设备名称
离开gdisk时按下 q ,则刚才所有动作都不会生效;按下 w 反之。
这里的指令对应的字母不用记住,按下 ?就可以得到对应指令和字母。
例:增加和删除分区:
先查看一下当前磁盘的状态:
gdisk /dev/vda
p # p指令列出磁盘信息(磁盘文件名,总容量,分区表...)
开始新增分区:
n # n指令新增分区
接下来会输出:
Partition number (4-128, default 4):
直接按enter键默认,也可以输入4。
接下来会输出:
First sector (34-83886046, default = 65026048) or {+-}size{KMGTP}:
输入新增分区的开始扇区号码位置,或按enter键取默认值。
接下来会输出:
Last sector (65026048-83886046, default = 83886046) or {+-}size{KMGTP}:
输入新增分区的结束扇区号码位置或者他的容量(例如+1G)。不要按enter键,因为默认值是用完整个磁盘。
接下来输出:
Current type is 'Linux filesystem'
Hex code or GUID (L to show codes, Enter = 8300):
直接enter使用默认值。
新增分区完毕,按下 p 查看分区表,再按下 w 将更改写入磁盘分区表。
查看一下分区:
cat /proc/partirions
发现新增的分区还没有更新进来。这是因为Linux还在使用这块磁盘,为了防止系统出问题就还没更新。可以重新开机进行更新,也可以用 partprobe 指令。
partprobe [-s] # 加上-s显示信息
此时再查看分区,已经更新了。
开始删除分区:
gdisk /dev/vda
d # d指令删除分区
输出:
Partition number (1-6):
输入要删除的分区号码。
再按下w写入前面的更改。
partprobe更新分区状态:
partprobe -s
磁盘格式化(创建文件系统)
分区完进行格式化。用mkfs(make filesystem)这个指令。
XFS文件系统 mkfs.xfs:
mkfs.xfs [一堆可选参数] 设备名
EXT4文件系统 mkfs.ext4:
mkfs.ext4 [可选参数] 设备名
想知道系统还支持什么文件系统的格式化:
mkfs[tab][tab]
连按两下tab键得到前缀为mkfs的所有指令。
文件系统校验
当文件系统出现问题时,可以用 xfs_repair(XFS文件系统) / fsck.ext4(ext4文件系统) 指令来检查修复文件系统。
xfs_repair [参数] 设备名
fsck.ext4 [参数] 设备名
执行这个指令时设备不能被挂载。
不要随便用这个指令。
文件系统挂载与卸载
要注意的点:一个文件系统不能挂载在多个目录中;一个目录不能挂载多个文件系统;要作为挂载点的目录要是空目录(如果挂载在非空的目录中,目录里的内容会暂时被隐藏,当文件系统卸载掉后恢复)。
挂载指令是 mount。
mount -a # -a表示将所有未挂载的磁盘都挂载上来
mount [-l] # 只输入mount会显示目前挂载的信息,加上-l会显示Label名称
mount [-t 文件系统类型] LABEL='...' 挂载点
mount [-t 文件系统类型] UUID='...' 挂载点
mount [-t 文件系统类型] 设备文件名 挂载点 # -t指定文件系统,不加参数-t系统会自动安排类型
mount还可以将一个目录挂载到另一个目录去,例如:
mkdir /data/var
mount --bind /var /data/var
ls -lid /var /data/var # 可以看到输出内容一样的
这样子进入/data/var就是进入/var。
根目录无法被卸载。若要修改挂载参数,或者根目录出现只读状态,可以重新挂载:
mount -o remount, rw, auto /
# -o rw, auto是mount的参数,表示文件系统为可读写状态,
# 并允许该文件系统被以 mount -a 自动挂载
卸载指令是umount。
umount [-fnl] 设备文件名或挂载点
# -f: 强制卸载
# -l: 立即卸载
# -n: 不更新 /etc/mtab 情况下卸载
磁盘/文件系统参数修订
mknod:
硬件文件名系统已可以自动产生,有时候可能会需要手动,就需要mknod指令来创建。
Linux是通过文件的major和minor(主要和次要设备代码)数值来知道文件代表哪个设备的。那我们创建硬件文件时就要指定好文件的major和minor。
mknod 设备文件名 [bcp] [major] [minor]
# 参数b: 设置设备名称成为一个周边储存设备文件
# 参数c: 设置设备名称成为一个周边输入设备文件
# 参数p: 设置设备名称成为一个 FIFO 文件
xfs_admin:
这个指令可修改XFS文件系统的UUID和Label name。
xfs_admin [-lu] [-L label] [-U uuid] 设备文件名
# -l:列出设备的label name
# -u:列出设备的uuid
# -L:设置设备的label name
# -U:设置设备的uuid
(uuidgen 指令可以生成新的uuid。)
tune2fs:
该指令修改ext4的label name和UUID。
tune2fs [-l] [-L label] [-U uuid] 设备文件名
7.4 设置开机挂载
本节要让系统可以在开机时自动进行挂载。可以直接到 /etc/fstab(filesystem table) 这个文件里修改。
这个文件的内容格式是:
# [设备/uuid/label name等] [挂载点] [文件系统] [文件系统参数] [dump] [fsck]
文件系统参数有:async/sync,auto/noauto,rw/ro,exec/noexec,user/nouser,suid/nosuid,defaults。
dump是用来做备份的指令,要用dump来备份就设为1,不要就0。现在有很多备份方案,直接设为0。
fsck设为1表示会在开机时检验文件系统,设为0不检验。因为xfs系统会自己进行检验,直接设为0就好。
例:将/dev/vda4开机自动挂载到/data/xfs
nano /etc/fstab
UUID="..." /data/xfs xfs defaults 0 0
# UUID是/dev/vda4的
7.5 内存交换空间(swap)之创建
当有某个程序用掉大部分内存导致内存不足时,内存交换空间就可以用来暂时存放内存里暂不使用的程序和数据,使内存挪出足够的空间给需要的程序使用。
使用实体分区创建swap
步骤:分区 -> 格式化 -> 启动 -> 观察(free和swapon -s指令)。
# 分区
gdisk /dev/vda # 分的时候partition number默认为6
# w指令写入更改
# partprobe让分区生效
# 开始创建
mkswap /dev/vda6
free # free指令查看
# 启动
swapon /dev/vda6
free
swapon -s # 查看目前使用的swap设备
# 写入配置文件
nano /etc/fstab
UUID='...' swap swap defaults 0 0
# 因为不是文件系统没有挂载点,所以第二个参数写swap即可
使用文件创建swap
如果磁盘已无未分区的容量,可以考虑使用大型文件取代磁盘设备的处理方式。
# dd指令创建128MB的文件
dd if=/dev/zero of=/tmp/swap bs=1M count=128
# if:input file,/dev/zero是会一直输出0的设备
# of:output file,将一堆0写入该文件
# 创建
mkswap /tmp/swap
# 启动
swapon /tmp/swap
# 查看正在使用的swap设备
swapon -s
# 设置自动启用
nano /etc/fstab
/tmp/swap swap swap defaults 0 0
# 关掉swap file
swapoff /tmp/swap /dev/vda6
# 关掉之后恢复原来状态,用swapon -s查看
swapon -a
swapon -s
课后习题
题目:我的用户希望能够独立一个 filesystem附挂在 /srv/myproject 目录下。 那你该如何创建新的 filesystem ,并且让这个 filesystem每次开机都能够自动的挂载到 /srv/myproject , 且该目录是给 project 这个群组共享的,其他人不可具有任何权限。且该 filesystem 具有 1GB 的容量。
答:
① 创建新的partition。
gdisk /dev/vda
按下 ‘n’ 新建分区,按下 ‘enter’ 默认分区号码,按下 ‘enter’ 默认启动柱面,输入 ‘+1G’ 创建1G的磁盘分区,按下 ‘enter’ 默认文件系统,最后按下 ‘w’ 写入更改。
partprobe
用该指令更新分区表。
② 格式化文件系统。
mkfs.xfs -f /dev/vda4
③ 挂载。
mkdir /srv/myproject # 创建挂载点
# 自动挂载
nano /etc/fstab
/dev/vda4 /srv/myproject xfs defaults 0 0
# 看有无挂载成功
mount -a # 自动挂载
df /srv/myproject
④ 设置权限。
chgrp project /srv/myproject
chmod 2770 /srv/myproject