Federated Machine Learning: Concept and Applications
Federated Machine Learning: Concept and Applications
背景
打破数据源之间的障碍是困难的,甚至是不可能的。大多数行业中,数据以孤岛形式存在。
各国都在加强保护数据安全和隐私的法律。这些法规的建立显然有助于建立一个更加文明的社会,但是也将对人工智能目前普遍使用数据交易程序提出新的挑战。
联邦学习概述
联邦学习定义
定义 N N N个数据拥有者 F 1 , . . . , F N {\mathcal{F}_1,...,\mathcal{F}_N} F1,...,FN, 他们都希望整合自己的数据 D 1 , . . . , D N {\mathcal{D}_1,...,\mathcal{D}_N} D1,...,DN。一种传统的方法是将所有数据放在一起,即用 D = D 1 ∪ , . . . , ∪ D N \mathcal{D}={\mathcal{D}_1\cup,...,\cup\mathcal{D}_N} D=D1∪,...,∪DN去训练模型 M s u m \mathcal{M}_{sum} Msum。联邦系统是一个学习过程,在这个学习过程中,所有数据拥有者协同训练一个模型 M F E D \mathcal{M}_{FED} MFED。在学习过程中,任何数据拥有者 F i \mathcal{F}_i Fi都不会将数据泄露给其他。另外, M F E D \mathcal{M}_{FED} MFED的性能应该与 M s u m \mathcal{M}_{sum} Msum近似。定义模型 M \mathcal{M} M准确率为 V \mathcal{V} V。假设为非负实数 δ ( 1 ) \delta(1) δ(1),如果 ∣ V F E D − V S U M ∣ |\mathcal{V}_{FED}-\mathcal{V}_{SUM}| ∣VFED−VSUM∣,则成联邦学习算法存在精度损失。
联邦学习隐私性
隐私是联邦学习的基本属性。
安全多方计算(SMC)。SMC安全模型自然涉及多方,在定义良好的仿真框架中提供安全证明,以保证完全的零知识,即每一方只知道自己的输入和输出。零知识是非常理想的,无法有效实现。
差分隐私。差分隐私、K-匿名和多样化在数据中添加噪声,或使用泛化方法模糊某些敏感属性,直到第三方无法区别个体,从而无法十数据恢复以保护隐私。这些工作通常涉及准确性和隐私之间的权衡。
通态加密。与差分隐私不同,数据和模型本身不传输,也不能被对方的数据猜到。因此,在原始数据级别上几乎没有泄露的可能性。在实践中,加性同态加密被广泛使用,在机器学习算法中,需要用多项式近似来评估非线性函数,这导致了准确性和隐私之间的权衡。
间接数据泄露。联邦学习的先驱工作暴露了中间结果,如随机梯度下降等优化算法的参数更新,没有提供安全保证,当这些梯度与数据结构一起暴露时,这些梯度的泄露实际上会泄露重要的隐私信息。研究人员考虑将区块链作为促进联邦学习的平台。
联邦学习种类
水平联邦学习:数据集贡献相同特征空间但样本不同。例如,两个地区银行在各自的地区可能有非常不同的用户组,它们的用户交集集非常小。然而,他们的业务非常相似,所以功能空间是相同的。
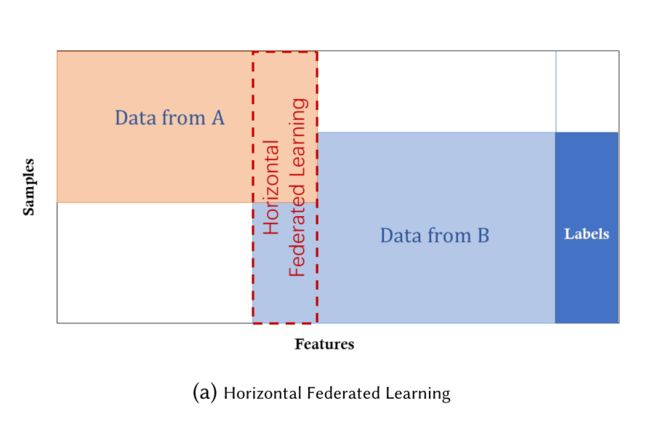
垂直联邦学习:适用于两个数据集共享的样本ID空间但是特征空间不同的情况。例如,假设在同一个城市有两家不同的公司,一家是银行,另一家是电子商务公司。它们的用户集很可能包含该地区的大多数居民,因此它们的用户空间的交集很大。但是,由于银行记录的是用户的收支行为和信用评级,而电子商务则保留的是用户的浏览和购买历史,因此它们的特征空间是截然不同的。假设我们希望双方都有一个基于用户和产品信息的产品购买预测模型。
垂直联邦学习将这些不同的特征进行聚合,并以保护隐私的方式计算训练损失和梯度,以合作的方式使用双方的数据构建模型的过程。在这样的联邦制机制下,参与各方的身份和地位是相同的。
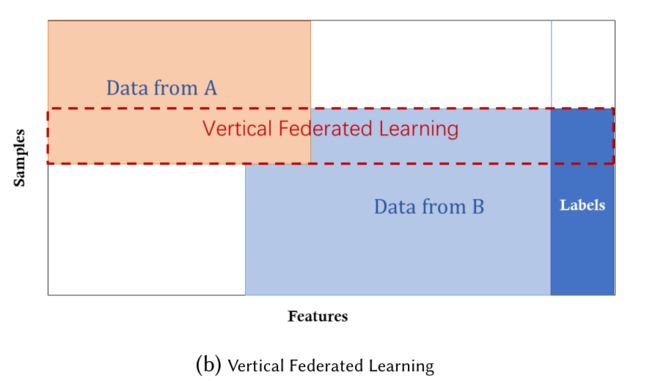
联邦迁移学习适用于两个数据集不仅在样本上不同,且在特征空间上也不同。比如一个是位于中国的银行,另一个是位于美国的电子商务公司,两家两家机构的用户群体有较小的交集。由于业务的不同,双方只有一小部分功能空间是重叠的。联邦迁移学习利用有限的公共样本集学习两个特征空间之间的公共表示,然后应用于对只有单侧特征的样本进行预测。
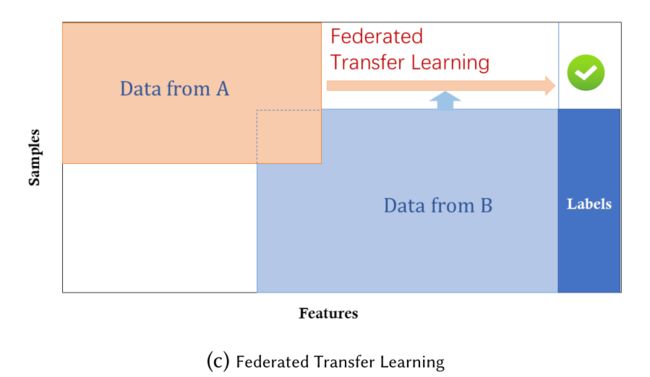
联邦学习系统的体系结构
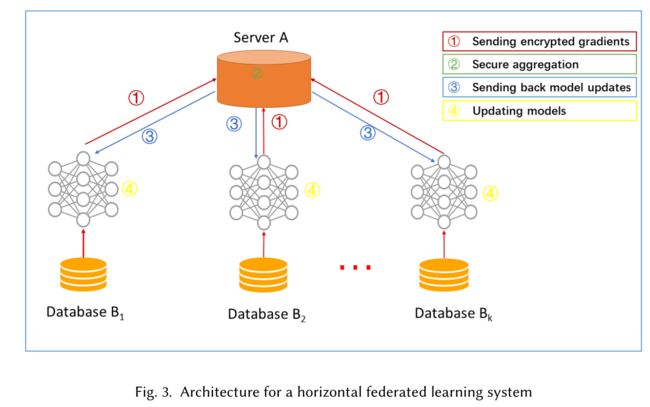
水平联邦学习:水平联邦学习典型体系结构如图3。一个典型假设是,参与者是诚实的,而服务器是诚实但好奇的,因此不允许任何参与者向服务器泄露信息。训练过程包括以下四步:
-
步骤1:参与者在本地计算训练梯度,用加密、差异隐私或秘密共享技术对选择的梯度进行掩码,并将掩码结果发送给服务器;
-
步骤2:服务器执行安全聚合,不学习任何参与者的信息;
-
步骤3:服务器将聚合的结果发送回参与者;
-
步骤4:参与者用解密的梯度更新各自的模型。
通过上述步骤进行迭代,直到损失函数收敛,从而完成整个训练过程。该架构独立于特定的机器学习算法(逻辑回归、DNN等),所有参与者将共享最终的模型参数。
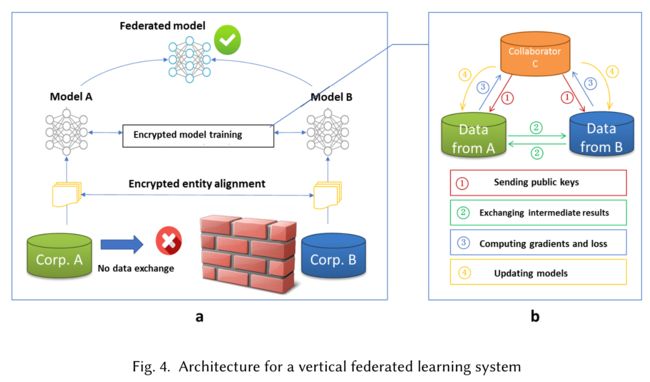
垂直联邦学习:假设A公司和B公司想要联合训练一个机器学习模型,他们的业务系统都有自己的数据。另外,B公司还有模型需要预测的标签数据。出于数据隐私和安全的考虑,A和B不能直接交换数据。为了保证培训过程中数据的保密性,第三方合作者C参与其中。第三方不与A或B勾结。联邦学习系统由两部分组成:
第1部分。加密的实体对齐。由于两家公司的用户组不相同,系统采用基于加密的用户ID比对技术,在A和B不暴露各自数据的情况下,对双方的普通用户进行确认。在对齐过程中,系统不会暴露不重叠的用户。
第2部分。加密模型训练。在确定了公共实体之后,我们可以使用这些公共实体的数据来训练机器学习模型。训练过程可分为以下四个步骤(如图4所示):
-
步骤1:合作方C创建加密对,向A和B发送公钥;
-
步骤2:A和B加密和交换梯度和损失计算的中间结果;
-
步骤3:A和B分别计算加密梯度并添加额外的掩码,B也计算加密损耗;A和B将加密值发送给C;
-
步骤4:C解密后将解密后的梯度和损耗发回给A和B;A和B揭开梯度的掩码,相应地更新模型参数。
联邦迁移学习:甲方和乙方只有非常小的重叠样本集,我们感兴趣的是学习甲方中所有数据集的标签。到目前为止,上节中描述的体系结构只适用于重叠的数据集。为了将其覆盖范围扩展到整个样本空间,我们引入了迁移学习。这并不改变图4所示的整体架构,而是改变了在甲乙双方之间交换的中间结果的细节。具体来说,迁移学习通常涉及学习甲乙双方特征之间的共同表示,并通过利用源域方(在本例中为B方)中的标签来最小化预测目标域方标签的错误。因此,甲乙双方的梯度计算不同于垂直联合学习场景下的梯度计算。在推理时,仍然需要双方计算预测结果。
激励机制:为了使不同组织之间的联合学习完全商业化,需要建立一个公平的平台和激励机制。模型建立后,模型的性能将体现在实际应用中,这种性能可以记录在一个永久的数据记录机制中(如区块链)。
相关工作
保护隐私的机器学习、联邦学习和分布式学习、联邦学习和边缘计算、联邦学习和联邦数据库系统
应用
以智能零售为例。其目的是利用机器学习技术为客户提供个性化的服务,主要包括产品推荐和销售服务。联邦学习和迁移学习解决两个问题,数据壁垒和三方存储的数据是异构的。
智能医疗保健。疾病症状、基因序列、医疗报告等医疗数据非常敏感和隐私,但医疗数据很难收集,它们存在于孤立的医疗中心和医院。
联邦学习和企业数据联盟
联邦学习机制使机构和企业可以共享一个统一的模型,而不需要进行数据交换。此外,联合学习可以借助区块链技术的共识机制,制定公平的利润分配规则。
更多博客请看:aidenz.gitee.io