【pytorch】2.2 pytorch 自动求导、 Tensor 与 Autograd
目录
- 一、计算图
- 二、自动求导要点
- 三、标量反向传播的计算
- 四、使用Tensor 及 Autograd 实现机器学习
-
-
- 1)先来造一批数据,作为样本数据 x 和 标签值y
- 2)定义一个模型 y = wx +b, 我们要学习出 w 和 b 的值,用来你拟合 x 和 y
- 3)可视化一下,红色曲线是预测结果 -- 模型曲线,蓝色点是真值
-
在神经网络中,一个重要内容就是进行参数学习,而参数学习离不开求导。
现在大部分深度学习架构都有自动求导的功能,torch.autograd包 就是用来自动求导的。
torch.autograd 包为张量上 所有的操作 提供了自动求导功能
这一篇学习并记录一下 自动求导 的要点。
一、计算图
在整个向前计算过程中,PyTorch采用计算图的形式进行组织,该计算图为动态图,且在每次 前向传播时,将重新构建。其他深度学习架构,如TensorFlow、Keras一般为静态图。
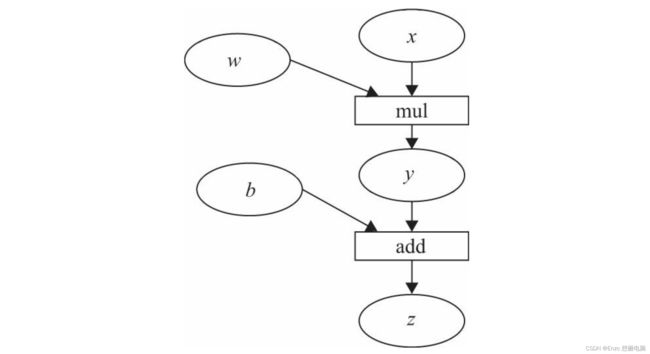
- 计算图是一种有向无环图像,用图形方式来表示算子与变量之间的关系,直观高效。
- 图中 圆形表示变量,矩阵表示算子
- 表达式:z=wx+b,可写成两个表示式: y=wx,z=y+b,
- 其中x、w、b为变量,是用户创建的变量,不依赖于其他变量,故又称 为叶子节点。为计算各叶子节点的梯度,需要把对应的张量参数requires_grad属性设置为 True,这样就可自动跟踪其历史记录。(后面会细说)
- y、z 是计算得到的变量,非叶子节点,z为根节点
- mul和add是算子(或操作或函数)
这些变量及算子就构成了一个完整的计算过程 (或前向传播过程)
二、自动求导要点
为实现对Tensor自动求导,需考虑如下事项:
1)创建叶子节点(Leaf Node)的Tensor,使用requires_grad参数指定是否记录对其 的操作,以便之后利用backward()方法进行梯度求解。requires_grad参数的缺省值为 False,如果要对其求导需设置为True,然后与之有依赖关系的节点会自动变为True。
2)可利用requires_grad_()方法修改Tensor的requires_grad属性(比如一开始在训练阶段,requires_grad 值设置为了True,在测试阶段修改为 False)。可以调用.detach()或 with torch.no_grad():,将不再计算张量的梯度,跟踪张量的历史记录。这点在评估模 型、测试模型阶段中常常用到。
3)通过运算创建的Tensor(即非叶子节点),会自动被赋予grad_fn属性。该属性表 示梯度函数。叶子节点的grad_fn为None。
4)最后得到的Tensor(根节点)执行backward()函数,此时自动计算各变量的梯度。
- 每次反向传播结束,叶子结点的梯度会被清空。如果需要多次反向传播的梯度累加,需要指定backward 中的参数retain_graph=True,这样子节点的梯度是累加的。
- 非叶子节点的梯度backward调用后即被清空
5)backward()函数接收参数,该参数应和调用backward()函数的Tensor的维度相同, 或者是可broadcast的维度。如果求导的Tensor为标量(即一个数字),则backward中的参数可省略。
三、标量反向传播的计算

- 假设x、w、b都是标量,则计算结果 z 也是标量 (z=wx+b)
- 对根节点z调用backward()方法,我们无须对 backward()传入参数
* 这里先提一嘴,后面会说到的是: 如果目标张量对一个非标量调用backward(),则需要传入一个 gradient参数,该参数也是张量,而且需要与调用backward()的张量形状相同。
以下是实现自动求导的主要步骤:
import torch
# 输入张量 x
x = torch.Tensor([2])
# 初始化 权重参数w, 偏移量b,并设置 require_grad 属性为 True, 为自动求导
w = torch.randn(1, requires_grad=True)
b = torch.randn(1, requires_grad=True)
# 实现向前传播
y = torch.mul(w, x)
z = torch.add(y, b)
# 分别查看叶子节点 x, w, b 和 非叶子节点 y、z 的require_grad属性
print(x.requires_grad, w.requires_grad, b.requires_grad) # False True True
print(y.requires_grad, z.requires_grad ) # True True
# 查看各节点是否为叶子节点
print(x.is_leaf, w.is_leaf, b.is_leaf, y.is_leaf, z.is_leaf) # True True True False False
# 分别查看 叶子节点 和 非叶子节点 的 grad_fn 属性
print(x.grad_fn, w.grad_fn, b.grad_fn) # None None None
print(y.grad_fn, z.grad_fn) #
z.backward() # 梯度不会累加
# z.backward(retain_graph=True) # 如果多次使用backward,需要梯度累加,则需要修改参数retain_graph为True
# 查看叶子节点的梯度,x是叶子节点但它无须求导,故其梯度为None
print(w.grad,b.grad,x.grad) # tensor([2.]) tensor([1.]) None
#非叶子节点的梯度,执行backward之后,会自动清空
print(y.grad,z.grad) # None None
四、使用Tensor 及 Autograd 实现机器学习
1)先来造一批数据,作为样本数据 x 和 标签值y
import torch
import matplotlib.pyplot as plt
%matplotlib inline
torch.manual_seed(100)
# 生成 x坐标数据,形状为 100 x 1
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
# 生成 y坐标数据,,形状为 100 x 1,加上一些噪声
y = 3 * x.pow(2) + 2 + 0.2 * torch.rand(x.size())
# 画图,把tensor数据转换为numpy数据
plt.scatter(x.numpy(), y.numpy())
plt.show()

2)定义一个模型 y = wx +b, 我们要学习出 w 和 b 的值,用来你拟合 x 和 y
# 初始化权重参数,参数 w、b 为需要学习的,故需要设置参数 requires_grad=True
w = torch.randn(1, 1, dtype=torch.float, requires_grad=True)
b = torch.zeros(1, 1, dtype=torch.float, requires_grad=True)
print(w) # tensor([[1.1046]], requires_grad=True)
print(b) # tensor([[0.]], requires_grad=True)
lr = 0.001 # 学习率
for i in range(800):
# 向前传播,得到预测的y值,记为 y_pred
y_pred = w * x.pow(2) + b
# 定义损失函数
loss = (y - y_pred) ** 2
loss = loss.sum()
# 反向传播,自动计算梯度,存放在 grad 属性中
loss.backward()
# 手动更新参数,需要用torch.no_grad(), 使上下文环境中切断自动求导的计算
with torch.no_grad():
# 更新参数
w -= lr * w.grad
b -= lr * b.grad
# 梯度清零
w.grad.zero_()
b.grad.zero_()
print(w) # tensor([[2.9668]], requires_grad=True)
print(b) # tensor([[2.1138]], requires_grad=True)
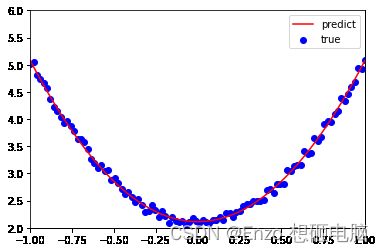
3)可视化一下,红色曲线是预测结果 – 模型曲线,蓝色点是真值
plt.plot(x.numpy(), y_pred.detach().numpy(),'r-',label='predict')#predict
plt.scatter(x.numpy(), y.numpy(),color='blue',marker='o',label='true') # true data
plt.xlim(-1,1)
plt.ylim(2,6)
plt.legend()
plt.show()