Transformer系列:Detection--> Deformable DETR (ICLR2021)
文章地址:https://arxiv.org/pdf/2010.04159.pdf。首先介绍文章的内容,后面附上自己的一些疑惑和思考,欢迎讨论。
1. Motivation
DETR 减少了目标检测中手工设计的过程(如anchor生成, NMS后处理,rule-based training target assignment),但它有两个缺点:
1)收敛慢,比如在COCO上收敛需要500 epoch,比Faster RCNN慢了10到20倍;attention module在初始化时对每个pixel的attention weight是均匀分布的,因此需要较长时间使它学习去关注有意义的位置。
2)小目标检测能力相对较弱。高分辨率的特征有利于小目标的检测,然而高分辨率特征的attention weight计算复杂度高,是pixel数量的平方![]() 。
。
Deformable conv是处理稀疏位置的一种有效机制。文章提出一种deformable attention module,只关注所有pixel中有着突出关键作用的一小部分sampling pixel。这个module也可以拓展到融合多尺度特征上,从而增强小目标检测能力。
除此之外,文章还提出了iterative bounding box refinement,并尝试two-stage方式进一步提高检测能力。
2. Method
Deformable DETR用它提出的(multi-scale)deformable attention module替代原始Transformer中的attention module,网络结构如下图。我们首先介绍deformable attention module。

2.1 Deformable Attention Module
Transformer中attention的问题在于它会查看feature map中所有的pixel位置,文章借鉴了deformable conv的思想,为每个query安排指定数量(远小于pixel数)的key,如此就可以改善收敛性和feature map分辨率的问题。

给定一个feature map ![]() ,q,m,k分别是query,attention head,sampled key的下标。K是是采样的key的数量,K远小于HW。原始multi-head attention feature的计算方式为:
,q,m,k分别是query,attention head,sampled key的下标。K是是采样的key的数量,K远小于HW。原始multi-head attention feature的计算方式为:

改进后的deformable attention feature的计算方式为:

其中![]() 是相对于reference point
是相对于reference point ![]() 的位置偏移。
的位置偏移。 ![]() 和
和  是通过
是通过![]() 经过一个输出通道数为3MK的线性映射操作获得的。输出的前2MK是偏移量的坐标,后MK经过softmax后得到attention weight。
经过一个输出通道数为3MK的线性映射操作获得的。输出的前2MK是偏移量的坐标,后MK经过softmax后得到attention weight。
2.2. Multi-scale Deformable Attention Module
给定multi-scale feature map ![]() ,其中
,其中 ![]() ,则 multi-scale deformable attention feature的计算方式如下式。它与上述deformable attention feature的不同之处就在于它是从multi-scale feature中采样了LK个点。
,则 multi-scale deformable attention feature的计算方式如下式。它与上述deformable attention feature的不同之处就在于它是从multi-scale feature中采样了LK个点。

当L=1,K=1,W'是identity matrix时,上式退化为deformable conv。
2.3 Deformable Transformer Encoder
将Transformer中的attention module替换为multi-scale deformable attention module。Encoder中的multi-scale feature maps来自于ResNet的C3到C5 stage,最后C5经过stride为2的3*3卷积得到C6。使用了multi-scale deformable attention module后就不需要FPN来融合不同尺度信息了。
值得注意的是,为了辨别每个query pixel在哪一个feature level,需要向feature中加入scale-level embedding  。该embedding随着网络自动学习。
。该embedding随着网络自动学习。
2.4 Deformable Transformer Decoder
在decoder中,只将cross-attention module替换为multi-scale deformable attention module,而self-attention module保持不变。对于每个query,reference point通过query embedding经过线性映射后接sigmoid函数得到。并且在detection head预测bounding box时,改为预测相对于reference point的偏移量。
2.5 Iterative Bounding Box Refinement & Two-Stage Deformable DETR
在原始的DETR中,object queries与当前输入的图像是无关的。文章提出一种two-stage策略,在第一阶段生成region proposals,第二阶段将这些proposals作为object queries输入decoder,进一步修正bounding box。
在第一阶段,为了达到高recall,可以将multi-scale feature maps的每个pixel都作为object query,但是这会导致极大的复杂度。因此文章去掉了decoder,在encoder的输出直接预测bounding box,并选择分数高的作为region proposals。注意,此处不用NMS。
3. Experiment
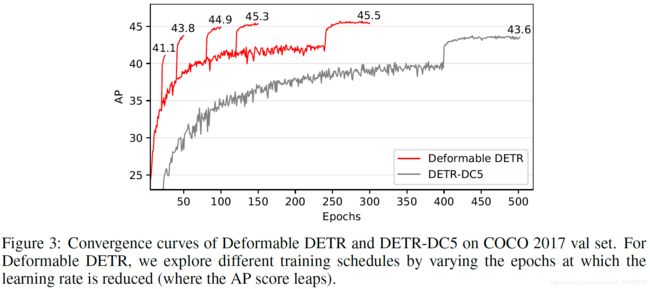
3.1 与DETR对比

3.2 Ablation Study

4. Questions & Discussion
4.1 Object queries的含义
Object queries 作为可学的参数,有点像learnable positional encoding,也是learnable anchors。原来的anchor based检测算法在每个feature pixel上设置了不同size和aspect ratio的anchor。而DETR学到的anchor数目固定设为100,远小于手工设置的anchor数,它们和当前输入的图像无关,是从整个数据集里学到的anchor位置。那么怎么保证这100个anchor对于当前图像是合适的呢?Deformable DETR提出的two-stage策略相对来说更加合理一些。
4.2 Deformable DETR和DETR中attention weights的不同
DETR中attention weights是通过query和key内积得到的,而Deformable DETR是用query学习到的,这样就没有了原始Transformer中key和value的区分。与其说是选了一些key的subset做self-attention,不如说就是deformable conv的增强版。
4.2 为什么不再需要NMS
DETR和Deformable DETR是怎么保证预测出来的框没有重叠的呢?