卷积神经网络识别cifar10
- cifar10数据集描述:
提供5万张32* 32像素点的十分类彩色图片和标签,用于训练。
提供1万张的32* 32像素点的十分类彩色图片和标签,用于测试。
10 个类别的RGB彩色图片分别为:飞机( airlane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。 - cifar10数据集查看
代码如下:
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import cifar10
import numpy as np
np.set_printoptions(threshold=np.inf) # 设置Print输出可以无限
# 启用gpu加速
gpus = tf.config.list_physical_devices("GPU")
print(gpus)
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0], "GPU")
# 加载cifar数据
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
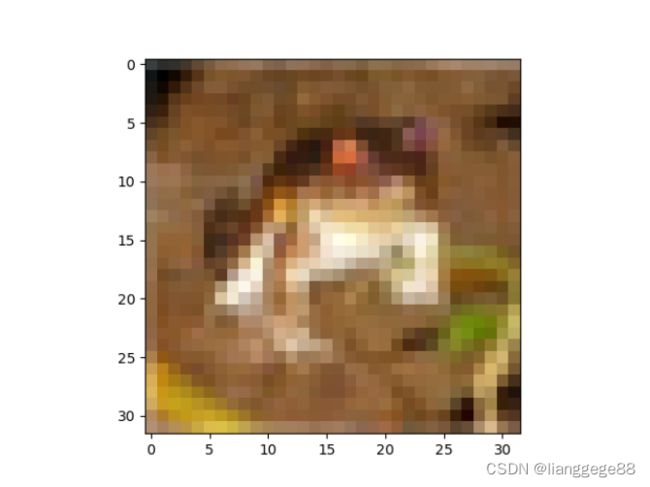
# 输出一张训练集的图片
plt.imshow(x_train[0])
plt.show()
print("x_train[0] \n",x_train[0])
print("y_train[0] \n",y_train[0])
print("x_test.shape\n",x_test.shape)
结果如下:

3. cifar10的卷积神经网络如下(待改进):
import tensorflow as tf
from tensorflow.keras import Model
from tensorflow.keras.layers import Flatten, Dense, Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout
from tensorflow.keras import losses
from tensorflow.keras import callbacks
from tensorflow.keras.datasets import cifar10
import os
import numpy as np
from matplotlib import pyplot as plt
np.set_printoptions(threshold=np.inf) # 设置Print输出可以无限
# 启用gpu加速
gpus = tf.config.list_physical_devices("GPU")
print(gpus)
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0], "GPU")
# 实现模型的保存和加载(即断点续训)
check_point_savepath = "./cifar_checkpoint/cifar.ckpt"
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0 # 归一化
class Baseline(Model):
def __init__(self):
super(Baseline, self).__init__()
self.c1 = Conv2D(filters=6, kernel_size=(5, 5), padding="same") # 卷积
self.b1 = BatchNormalization() # 批标准化
self.a1 = Activation("relu") # 激活
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2, padding="same") # 最大值池化
self.d1 = Dropout(0.2) # 舍弃20%的隐含层的神经元
self.flatten = Flatten() # 拉直
self.d2 = Dense(128, activation="relu") # 全连接层
self.d3 = Dropout(0.2) # 舍弃
self.d4 = Dense(10, activation="softmax") # 输出层
def call(self, x): # 定义一次前向传播
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.d1(x)
x = self.flatten(x)
x = self.d2(x)
x = self.d3(x)
y = self.d4(x)
return y
model = Baseline()
model.compile(optimizer='adam',
loss=losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 一般的断点续训需要卸载模型的编译之后
if os.path.exists(check_point_savepath+".index"): # 判断是否存在这个所有文件
print("------------load the model-------------")
model.load_weights(check_point_savepath) # 模型加载
# 模型的保存
cp_callback = callbacks.ModelCheckpoint(filepath=check_point_savepath,save_weights_only=True,save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1, callbacks=[cp_callback])
model.summary()
# print(model.variables) # 打印模型的参数
# 将模型的参数存放在txt中
with open("./cifar_wights.txt","w") as f:
for i in model.variables:
f.write(str(i.name)+'\n')
f.write(str(i.shape) + '\n')
f.write(str(i.numpy()) + '\n')
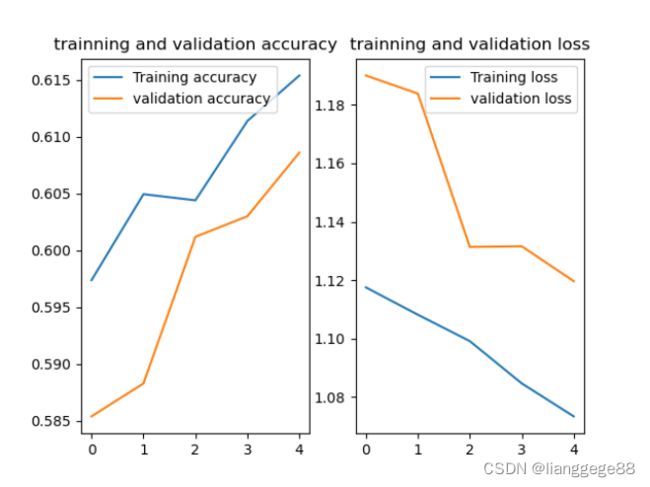
# 显示训练集和测试集的acc和loss曲线
acc = history.history["sparse_categorical_accuracy"]
val_acc = history.history["val_sparse_categorical_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
plt.subplot(1,2,1) # 建立一个一行两列的图 第三个参数表示为第一个图
plt.plot(acc,label="Training accuracy")
plt.plot(val_acc,label="validation accuracy")
plt.title("trainning and validation accuracy")
plt.legend()
plt.subplot(1,2,2) # 建立一个一行两列的图 第三个参数表示为第一个图
plt.plot(loss,label="Training loss")
plt.plot(val_loss,label="validation loss")
plt.title("trainning and validation loss")
plt.legend()
plt.show()
结果如下:
Python 3.8.3 (default, Jul 2 2020, 17:30:36) [MSC v.1916 64 bit (AMD64)] on win32
runfile(‘D:/pythonProject/cifar_2.py’, wdir=‘D:/pythonProject’)
[PhysicalDevice(name=‘/physical_device:GPU:0’, device_type=‘GPU’)]
2022-10-07 17:43:12.289218: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-10-07 17:43:12.657962: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 1659 MB memory: -> device: 0, name: NVIDIA GeForce RTX 3050 Ti Laptop GPU, pci bus id: 0000:01:00.0, compute capability: 8.6
------------load the model-------------
2022-10-07 17:43:13.053227: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 614400000 exceeds 10% of free system memory.
2022-10-07 17:43:13.169131: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)
Epoch 1/5
2022-10-07 17:43:14.350361: I tensorflow/stream_executor/cuda/cuda_dnn.cc:369] Loaded cuDNN version 8401
2022-10-07 17:43:15.648351: I tensorflow/stream_executor/cuda/cuda_blas.cc:1760] TensorFloat-32 will be used for the matrix multiplication. This will only be logged once.
1563/1563 [] - 7s 3ms/step - loss: 1.1175 - sparse_categorical_accuracy: 0.5974 - val_loss: 1.1900 - val_sparse_categorical_accuracy: 0.5854
Epoch 2/5
1563/1563 [] - 4s 3ms/step - loss: 1.1082 - sparse_categorical_accuracy: 0.6049 - val_loss: 1.1839 - val_sparse_categorical_accuracy: 0.5883
Epoch 3/5
1563/1563 [] - 4s 3ms/step - loss: 1.0992 - sparse_categorical_accuracy: 0.6044 - val_loss: 1.1314 - val_sparse_categorical_accuracy: 0.6012
Epoch 4/5
1563/1563 [] - 4s 3ms/step - loss: 1.0847 - sparse_categorical_accuracy: 0.6114 - val_loss: 1.1316 - val_sparse_categorical_accuracy: 0.6030
Epoch 5/5
1563/1563 [==============================] - 4s 2ms/step - loss: 1.0734 - sparse_categorical_accuracy: 0.6154 - val_loss: 1.1197 - val_sparse_categorical_accuracy: 0.6086
Model: “baseline”
Layer (type) Output Shape Param #
conv2d (Conv2D) multiple 456
batch_normalization (BatchNo multiple 24
activation (Activation) multiple 0
max_pooling2d (MaxPooling2D) multiple 0
dropout (Dropout) multiple 0
flatten (Flatten) multiple 0
dense (Dense) multiple 196736
dropout_1 (Dropout) multiple 0
dense_1 (Dense) multiple 1290
Total params: 198,506
Trainable params: 198,494
Non-trainable params: 12