YOLO V4 -- 学习笔记
参考文章:深入浅出Yolo系列之Yolov3&Yolov4&Yolov5核心基础知识完整讲解 – 江大白*
参考视频教程:目标检测基础——YOLO系列模型(理论和代码复现)-- PULSE_
YOLO V4主要创新
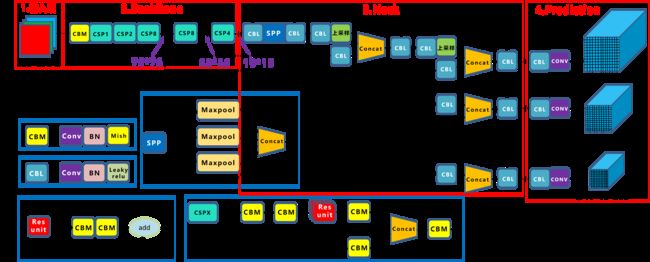
·输入端创新:Mosaic数据增强、cmBN、SAT自对抗训练
·BackBone(CNN)主干网络:CSPDarknet53、Mish激活函数、Dropblock
·Neck:在BackBone和最后的输出增之间加一些模块,如SPP模块,FPN+PAN结构
·Prediction:损失函数的改进,训练时Ground-truth和predict之间使用CIOU_LOSS,NMS变为DIOU_nms进行预测框的筛选
1.输入端创新
(1) Mosaic数据增强
原理:4张图片,以随机缩放、随机裁剪、随机排布的方式拼接成一张新图片,再进行训练
解决问题:小目标数量少(随即缩放会增加小目标的数量)、数据集中大中小目标占比不均匀(合并让大中小合在一起,分布更加均匀)
(2) cmBN

batch normalization的变体,BN是对当前一个批次的数据做批规范化,cmBN则是对当前及以往三次的mini-batch的结果一起做规范化,并且在当前Batch中进行累积。(尽可能保留更多的信息?)
(3)SAT自对抗训练
数据增强方法的一种,分为两个阶段:
第一个阶段:神经网络更改原始图像
第二阶段:训练神经网络以正常方式在修改后的图像上执行目标检测任务
作用:尽可能覆盖所有样本,增加样本的多样性,从而增加目标分类检测的能力
2.BackBone创新
(1)CSPDarknet53
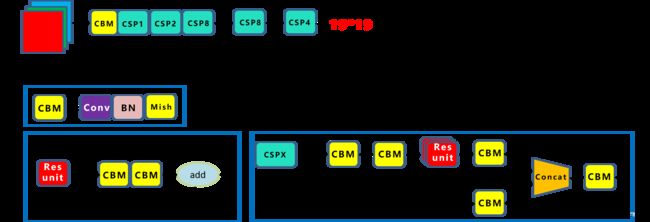
CSP模块前面的卷积核大小为3x3,步长为2,可以起到下采样的作用,而Backbone有5个CSP模块,等于5次下采用一样,效果和之前版本一样。(若输入为608x608,则变化规律为608,304,152,76,38,19)
CBM与之前DBL(CBL)不同之处在于激活函数变成了Mish,V4网络中Backbone的激活函数为mish,Neck区域仍是采用Leaky_relu激活函数.
CSP的工作原理是先将基础层的特征映射划分为两部分,然后通过跨层次结构将它们合并,在减少计算量(减少梯度信息重复)的同时还可以保证准确率。通过使用CSP模块,有三个方面的好处:增强CNN的学习能力,让模型更加轻量化的同时还保证了准确性、降低内存成本、降低计算瓶颈
(2)Mish激活函数
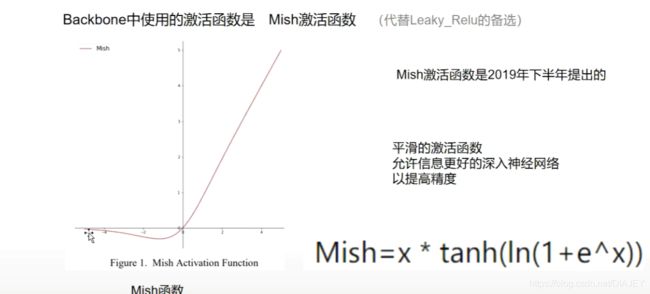
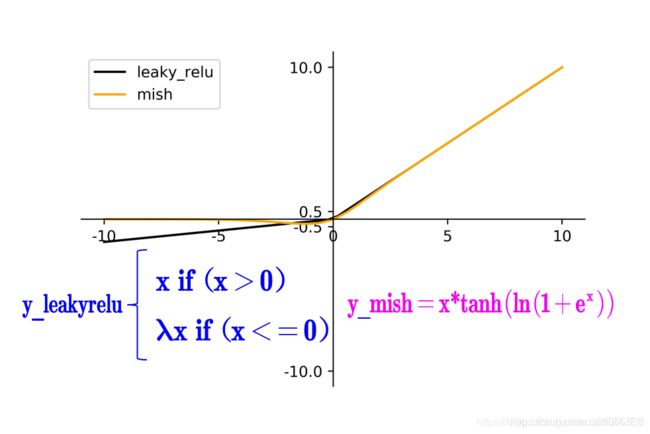
Leaky_relu虽然让负区域的信息都起到一定的作用,达到保存尽可能多信息的作用,但是有一个不合理的地方是,越往负值区域(左边)走的信息反而影响更大。
因此Mish的改进在于减弱了负值大的区域的影响,而是让越接近0的区域起到更大的作用,此外是让激活函数更加光滑,有利于精度的提高。
(3) DropBlock
Dropblock的作用和Dropout相似,都是防止过拟合。和Dropout不同在于,Dropout是随机删除神经元从而让网络变简单,Dropblock则是将某个局部区域进行删除丢弃。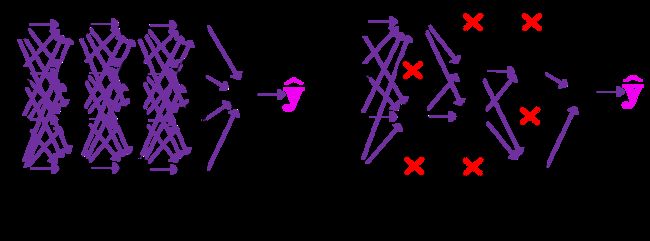

为什么要使用这种神经元删除方式?
卷积层对于Dropout这种随机丢弃的方式不敏感,因为卷积层通常是三层连用:卷积+激活+池化层,池化层中都是对相邻单元起作用,即便随机丢弃了,卷积层仍然可以从相邻的激活单元学习到相同的信息(Dropout主要是在全连接层上起作用).因此随机丢弃的方式对特征图的影响并不大。
Dropout思想是借鉴2017年提出的Cutout数据增强的思想,只是从输入图像应用到了特征图上。变化规律不固定,在训练时以一个小的比例开始,随着训练过程中线性地增加该比例
3.Neck创新
(1) SPP模块
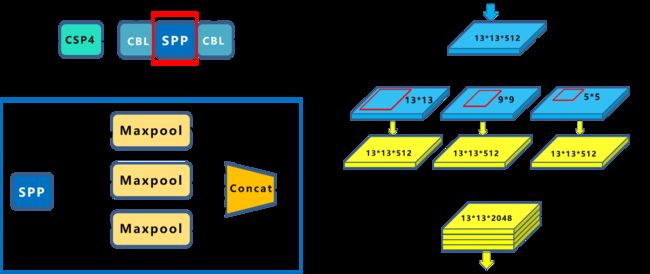

在SPP模块中,使用不同大小的卷积核对13x13的特征图进行最大池化操作,再将不同尺度的特征图进行Concat操作
如果最后统一为13x13尺寸?
主要使用padding操作,如当使用5x5-s-1的核时,当padding=2,池化后的特征图仍为13x13大小
这样做的好处在于,可以增加最后输出特征图所接受的特征尺寸,增加主干特征的接受范围,显著的分离重要的上下文特征(接受更多尺度的特征)
(2)FPN+PAN
在YOLO V3中,只有FPN一层,在FPN完成上采样后,便在尺寸小的特征图上检测大目标,尺寸大的特征图上检测小目标,这样做是因为更精细的特征图上检测小目标更精确。
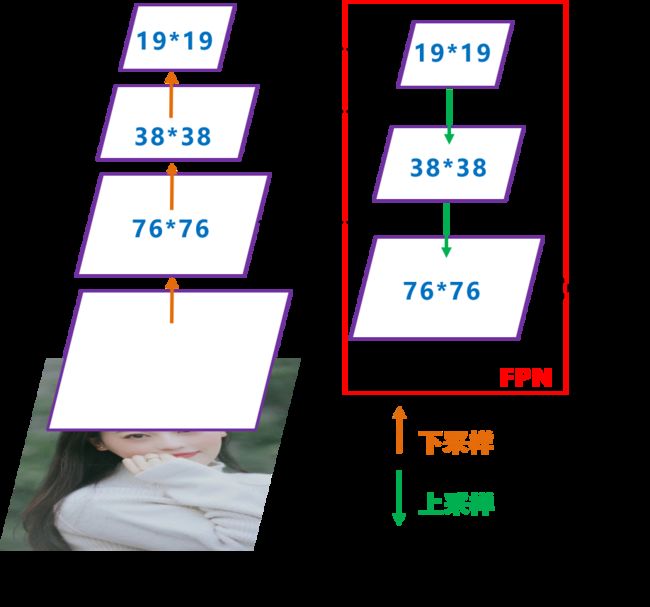
YOLO V4在此基础上,增加了PAN结构,也就是再下采样一次再进行检测,这样做的原因是:
·FPN层通过自顶向下传递了强语义特征,语义信息强,但是对于定位信息的获取还存在不足(v3对于一些小物体的检测还是无法实现)。而通过加入PAN让特征图在进行一次自底向上的操作,传递了强定位的特征。再通过融合操作,让最后输出的特征图既拥有了强语义特征,又有了强定位特征。进一步提高特征提取的能力。
可以看到,最终输出的特征图顺序也发生了改变,和V3正好相反:
第一个Yolo层是最大的特征图76×76,mask=0,1,2,对应最小的anchor box。
第二个Yolo层是中等的特征图38×38,mask=3,4,5,对应中等的anchor box。
第三个Yolo层是最小的特征图19×19,mask=6,7,8,对应最大的anchor box。
4.Prediction创新
(1) CIOU_LOSS
在V4版本前,损失函数使用的时IOU_Loss,即计算Predict和Ground-truth的交并比作为损失值
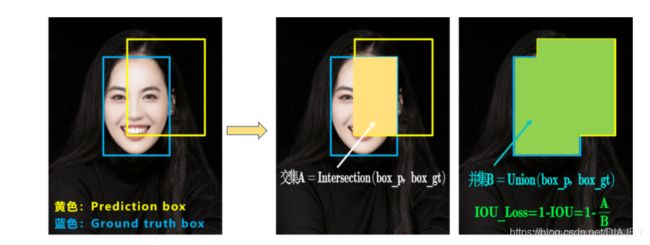
这种计算方法有两个问题就是,
1.当prediction和ground-truth不相交时,无法让网络知道如何调整才能让loss值变小(IOU为0,不可导,即不能优化);
2.在prediction和ground-truth相交时,无法判断两者的相交情况(比如谁左谁右),这样也无法准确指导调整
GIOU_Loss
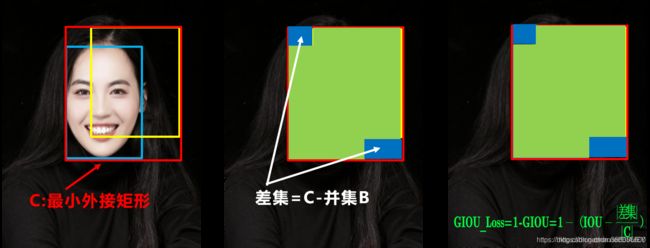
通过找到不相交的区域(差集)来指导网络调整
但有一个不足是,当预测框在目标框内,且大小不一致时,差值是相同的,此时也无法知道变化(和IOU一样)

DIOU_Loss
考虑了预测框和目标框中心点的欧式距离以及对角线距离

通过这种方式,当面对包裹情况时,可以通过计算欧氏距离,让DIOU_Loss实现收敛。
这种方法还存在一个问题,就是当出现两框中点距离抑制,对角线距离相等,但长宽比不一样时,还是无法指导收敛
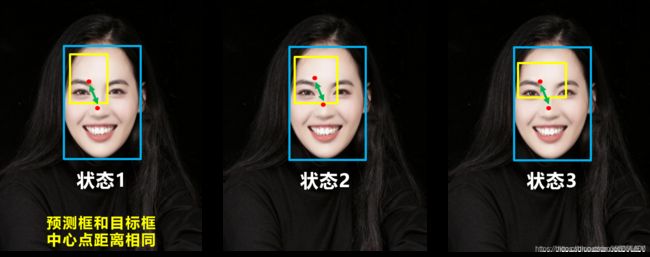
CIOU_Loss
CIOU增和了重叠面积、中心点面积、长宽比等几何因素,能够解决上面提到的所有问题。

其中v是衡量长宽比一致性的参数,可以定义如下:
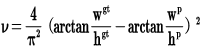
通过CIOU_Loss可以让预测框回归的速度和精度更高一些
(2)DIOU_nms
YOLO V4对于nms也做了一定的优化,结合了上面提到的DIOU_Loss计算两个框之间的重合度进行筛选。(CIOU会添加一个影响因子,包含了ground-truth的信息,因此测试过程中不能使用)
从上面的摩托车检测中,中间的摩托车因为考虑边界框中心点的位置信息,因此也可以回归出来。
总结
YOLOV4除了在精确度和效率上有很大的提升外,还有以下贡献:
1.提出了一种高效而强大的目标检测模型,并且使用单GPU就能训练出来
2.在训练过程中,引进了很多最新的成果,并验证了它们对目标检测器的影响
3.改进了SOTA方法,使其更有效,更适合单CPU训练
代码解读
Tensorflow版本代码:
代码地址:https://github.com/hunglc007/tensorflow-Yolov4-tflite