NeRF神经辐射场学习笔记(五)——Mip NeRF 360论文创新点解读
NeRF神经辐射场学习笔记(五)——Mip NeRF 360论文创新点解读
- 声明
- 论文概述
- 创新点概述
- 1.非线性场景参数化(non-linear scene parameterization)
- 2.在线“蒸馏”(online distillation)
- 3.基于失真的优化器(novel distortion-based regularizer)
- 参考文献和资料
声明
本人书写本系列博客目的是为了记录我学习三维重建领域相关知识的过程和心得,不涉及任何商业意图,欢迎互相交流,批评指正。
论文概述
Mip-NeRF通过基于圆锥体的渲染方式解决了原始NeRF对不同距离视角场景建模的混叠问题,并提高了渲染的速度,但是在关于无界场景的重建问题上,由于相机不规则的指向以及场景点的极远距离,使得Mip-NeRF的渲染效果还是有待改进。所以谷歌研究科学家Jon Barron又提出了关于无界场景重建的新的观点——Mip-NeRF 360,该论文从三个方面提出了新的观点,使用非线性场景参数化(non-linear scene parameterization)、在线“蒸馏”(online distillation)和新颖的基于失真的优化器(novel distortion-based regularizer)来克服无界场景带来的挑战。与 mip-NeRF 相比,均方误差降低了 57%,并且能够生成逼真的合成视图和详细的深度用于高度复杂、无界的现实世界场景的地图。下图是Mip-NeRF的实际效果:
创新点概述

1.非线性场景参数化(non-linear scene parameterization)
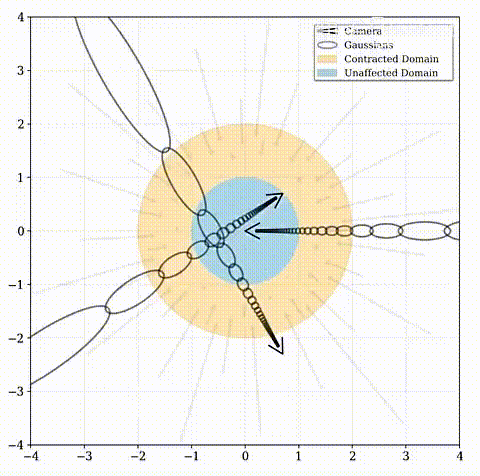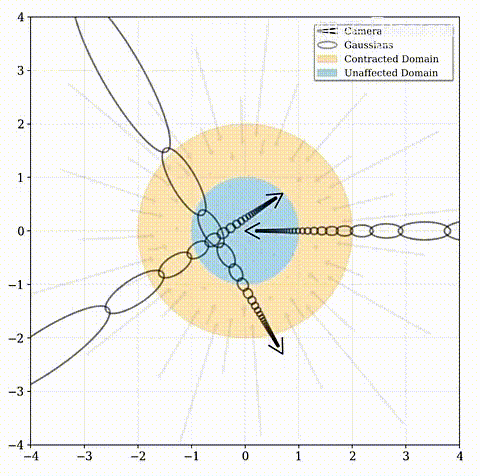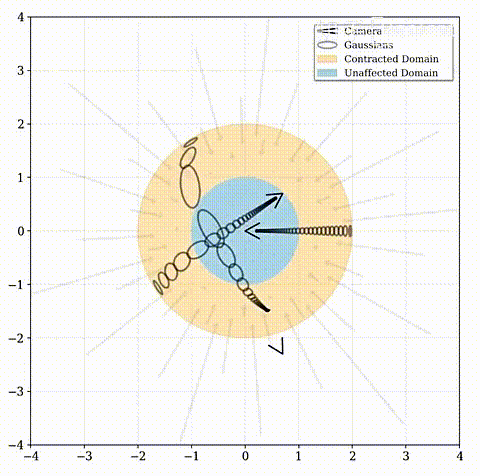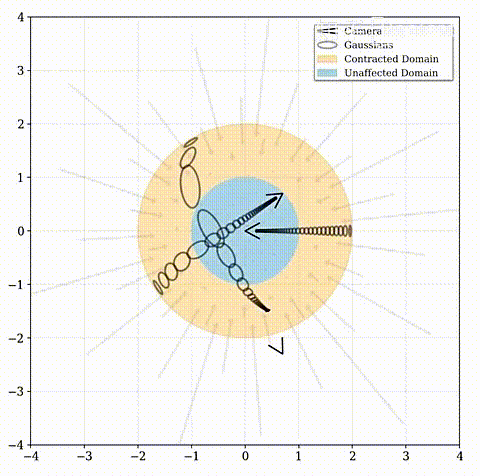
首先将 f ( x ) f(\textbf{x}) f(x)定义为从 R n → R n \mathbb{R}^n\to\mathbb{R}^n Rn→Rn(通常情况下n=3)映射的某个平滑坐标变换,然后可以计算这个函数的线性近似为: f ( x ) ≈ f ( μ ) + J f ( μ ) ( x − μ ) f(\textbf{x})\approx f(\pmb{\mu})+\pmb{J}_f(\pmb{\mu})(\pmb{x}-\pmb{\mu}) f(x)≈f(μμ)+JJf(μμ)(xx−μμ),其中 J f ( μ ) \pmb{J}_f(\pmb{\mu}) JJf(μμ)是 f f f在 μ \pmb{\mu} μμ处的雅可比矩阵。紧接着将 ( μ , Σ ) (\pmb{\mu}, \pmb{\Sigma}) (μμ,ΣΣ)高斯模型用 f f f转换: f ( μ , Σ ) = ( f ( μ ) , J f ( μ ) Σ J f ( μ ) T ) f(\pmb{\mu}, \pmb{\Sigma})= (f(\pmb{\mu}), \pmb{J}_f(\pmb{\mu})\pmb{\Sigma}\pmb{J}_f(\pmb{\mu})^T) f(μμ,ΣΣ)=(f(μμ),JJf(μμ)ΣΣJJf(μμ)T);这在功能上等同于经典的卡尔曼滤波器,其中 f f f是状态转移模型(state transition model),文章中选择的 f f f是: contract ( x ) = { x ∣ ∣ x ∣ ∣ ≤ 1 ( 2 − 1 ∣ ∣ x ∣ ∣ ) ( x ∣ ∣ x ∣ ∣ ) ∣ ∣ x ∣ ∣ > 1 \text{contract}(\pmb{x})=\left\{ \begin{aligned} &\pmb{x} &||\pmb{x}||\leq1 \\ &\left(2-\frac{1}{||\pmb{x}||}\right)\left(\frac{\pmb{x}}{||\pmb{x}||}\right) & ||\pmb{x}||>1 \\ \end{aligned} \right. contract(xx)=⎩ ⎨ ⎧xx(2−∣∣xx∣∣1)(∣∣xx∣∣xx)∣∣xx∣∣≤1∣∣xx∣∣>1即远点应按视差(反距离)而不是距离成比例分布。该函数将坐标映射到半径为2(橙色)的球上,其中半径为1(蓝色)内的点不受影响。Mip-NeRF 360将这种收缩应用于欧氏三维空间中的基于圆锥体采样的高斯模型(灰色椭圆),类似于卡尔曼滤波器,以产生我们的Contracted高斯模型(红色椭圆),并且确保了其中心全部位于半径为2的球内。 contract ( x ) \text{contract}(\pmb{x}) contract(xx)的设计结合了根据视差线性划分光线间隔的选择,意味着从位于场景原点的相机投射的光线在橙色区域将具有等距间隔。
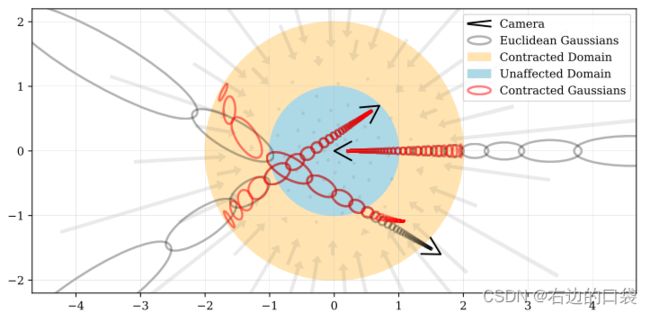
按照此逻辑,除了参数化3D坐标外,文章还提出了一种选择光线距离t的方式——即根据视差参数化光线ray,随之定义了欧式光线距离 t t t与“归一化”光线距离 s s s之间的可逆映射: s ≜ g ( t ) − g ( t n ) g ( t f ) − g ( t n ) , t ≜ g − 1 ( s ⋅ g ( t f ) + ( 1 − s ) ⋅ g ( t n ) ) s\triangleq\frac{g(t)-g(t_n)}{g_(t_f)-g(t_n)}, t\triangleq g^{-1}(s·g(t_f)+(1-s)·g(t_n)) s≜g(tf)−g(tn)g(t)−g(tn),t≜g−1(s⋅g(tf)+(1−s)⋅g(tn)),其中 g ( ⋅ ) g(·) g(⋅)是一个可逆的标量函数,文中取 g ( x ) = 1 / x g(x)=1/x g(x)=1/x,这就给出了映射到 [ t n , t f ] [t_n, t_f] [tn,tf]的“归一化”光线距离 s ∈ [ 0 , 1 ] s\in[0, 1] s∈[0,1],另一种说法为 t t t-距离在视差中线性分布的射线样本。这很好地对应了原始NeRF中发挥有效作用的观点——在有界空间中均匀间隔的光线间隔(evenly-spaced ray intervals within a bounded space)。
2.在线“蒸馏”(online distillation)
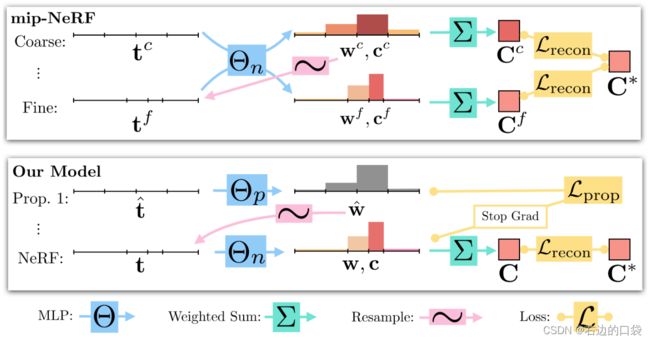
Mip-NeRF 360 训练了两类MLP网络:一个是“NeRF MLP” Θ NeRF \Theta_{\text{NeRF}} ΘNeRF(与传统NeRF使用的MLP网络类似)、一个是“proposal MLP” Θ prop \Theta_{\text{prop}} Θprop。proposal MLP值预测体密度,并根据NeRF相关公示转换为一个proposal权重向量 w ^ \hat{\pmb{w}} ww^,但是并不预测颜色信息。这些proposal权重向量 w ^ \hat{\pmb{w}} ww^被用于采样 s s s-间隔,然后提供给NeRF MLP——用来预测最终的权重 w \pmb{w} ww并预测颜色信息 c \pmb{c} cc以渲染图像。文章通过使用一个小的proposal MLP和一个大的NeRF MLP,并用许多采样点从proposal MLP中反复预测和重采样,但是只通过NeRF MLP预测一次。由此生成了一种新的训练模型,使得学习效率更高。
为了使该网络模型起效,文章提出一种新的损失函数——使得proposal MLP的权重直方图与NeRF MLP的权重直方图区域一致。首先定义一个函数,该函数计算与区间T重叠的所有proposal权重 w ^ \hat{\pmb{w}} ww^之和: bound ( t ^ , w ^ , T ) = ∑ j : T ⋂ T ^ j ≠ ∅ w ^ j \text{bound}(\hat{\pmb{t}}, \hat{\pmb{w}}, T)=\sum_{j:T\bigcap \hat{T}_j\neq \varnothing}\hat{w}_j bound(tt^,ww^,T)=∑j:T⋂T^j=∅w^j,如果两个直方图彼此一致,那么它必须对于 ( t , w ) (\pmb{t}, \pmb{w}) (tt,ww)中的所有internals ( T i , w i ) (T_i, w_i) (Ti,wi)保持 w i ≤ bound ( t ^ , w ^ , T i ) w_i\leq\text{bound}(\hat{\pmb{t}}, \hat{\pmb{w}}, T_i) wi≤bound(tt^,ww^,Ti)。进而定义损失函数为: L p r o p ( t , w , t ^ , w ^ ) = ∑ i m a x ( 0 , w i − bound ( t ^ , w ^ , T i ) ) 2 w i \mathcal{L}_{prop}(\pmb{t}, \pmb{w}, \hat{\pmb{t}}, \hat{\pmb{w}})=\sum_i\frac{max(0, w_i-\text{bound}(\hat{\pmb{t}}, \hat{\pmb{w}}, T_i))^2}{w_i} Lprop(tt,ww,tt^,ww^)=i∑wimax(0,wi−bound(tt^,ww^,Ti))2
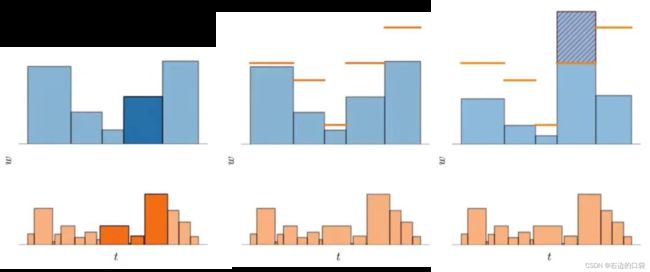
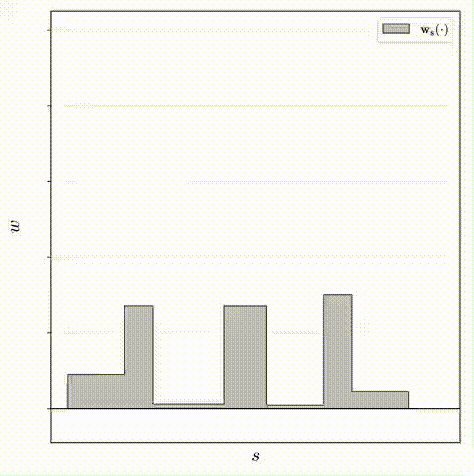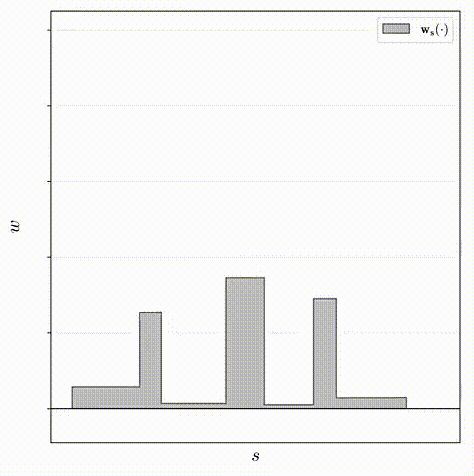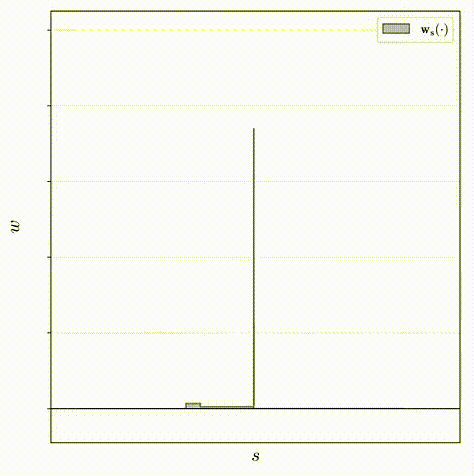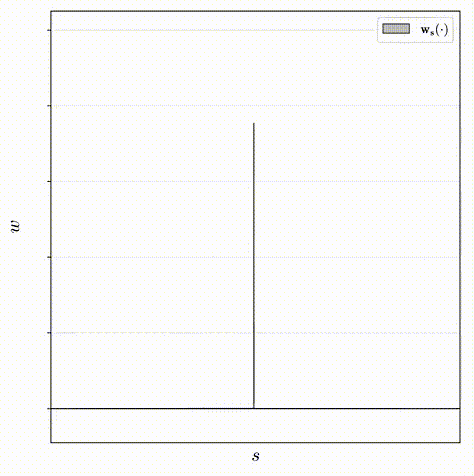
对于该原理的解释如下,其中下图为同一个分布的不同采样方式所构造的两个权重直方图(蓝色和橙色):
- 如下图左一所示,因为这两个直方图刻画同一个分布,所以上面突出显示的那个区间的权重一定不会超过在下面的直方图中与其重叠的区间权重的总和;
- 如下图左二所示,基于这个事实,则可以使用一个直方图的权重来构造另一个直方图权重的上限;
- 如下图右一所示,若这两个直方图同时刻画相同的真实分布的,上界是必须确定的。因此,在训练期间,会对proposal MLP和NeRF MLP分别生成的直方图之间构造了损失,该损失会惩罚任何违反此处以红色显示的边界的多余部分,以此来鼓励proposal MLP学习什么是有效的上界。
3.基于失真的优化器(novel distortion-based regularizer)
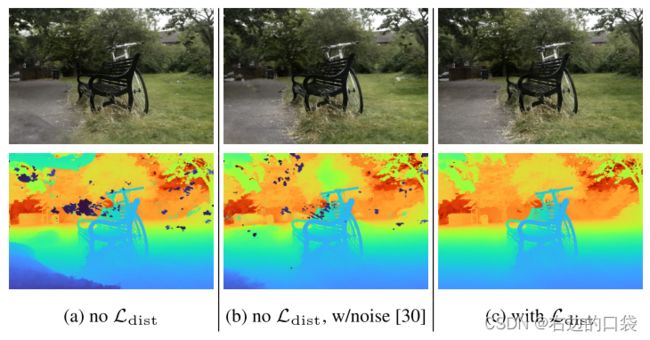
传统的NeRF经训练后会表现出两种模糊的现象:“floaters”——体积密集空间中的小而不相连的区域渲染后的结果像模糊的云一样、“background collapse”——远处的表面被错误地建模为靠近相机的密集内容的半透明云的现象。文章定义了一个优化器用来减少“floaters”和“background collapse”,该优化器的目的为最小化沿光线的所有样本之间的归一化加权绝对距离的值,即上图中所示的直方图的面积: L d i s t ( s , w ) = ∫ ∫ ∞ ∞ w s ( u ) w s ( v ) ∣ u − v ∣ d u d v \mathcal{L}_{dist}(\pmb{s}, \pmb{w})={\int\int}^{\infty}_{\infty}\pmb{w}_s(u)\pmb{w}_s(v)|u-v|d_ud_v Ldist(ss,ww)=∫∫∞∞wws(u)wws(v)∣u−v∣dudv其中 w s ( u ) \pmb{w}_s(u) wws(u)是在 u u u处对由 ( s , w ) (\pmb{s}, \pmb{w}) (ss,ww)定义的阶跃函数(step function)的插值: w s ( u ) = ∑ i w i 1 [ s i , s i + 1 ) ( u ) \pmb{w}_s(u)=\sum_iw_i\mathbb{1}_{[s_i, s_{i+1})}(u) wws(u)=∑iwi1[si,si+1)(u),但是上述公式不易计算,所以观察到 w s ( u ) \pmb{w}_s(u) wws(u)在interval间离散的特性,将其离散化重写: L d i s t ( s , w ) = ∑ i , j w i w j ∣ s i + s i + 1 2 − s j + s j + 1 2 ∣ + 1 3 ∑ i w i 2 ( s i + 1 − s i ) \mathcal{L}_{dist}(\pmb{s}, \pmb{w})=\sum_{i,j}w_iw_j|\frac{s_i+s_{i+1}}{2}-\frac{s_j+s_{j+1}}{2}|+\frac{1}{3}\sum_iw_i^2(s_{i+1}-s_i) Ldist(ss,ww)=i,j∑wiwj∣2si+si+1−2sj+sj+1∣+31i∑wi2(si+1−si)下图是优化器的效果对比:
参考文献和资料
[1]CVPR 2022 | 谷歌提出mip-NeRF 360:全景NeRF越来越丝滑!
[2]Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields
[3]Mip-NeRF 360原文