【论文笔记】RepLKNet论文阅读笔记
paper:Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
github:https://github.com/DingXiaoH/RepLKNet-pytorch
aistudio:没有GPU?模型在线一键体验
自从VGG提出以后,各种CNN网络层出不穷,但是他们都遵循了VGG的设计思想,通过多个小卷积核叠加来得到大的感受野同时保证较少的参数量(2各3x3的卷积核感受野和5x5的卷积核感受野相同,但是参数18<25)。随着ViT逐渐在各类视觉任务种拿到SOTA的表现,CNN似乎有点后继无力。RepLKNet打破了这种现象,提出使用在CNN网络中使用大的卷积核,RepLKNet在各类视觉任务中获得了SOTA表现。
目录
一、引言
二、大卷积
1、大的深度可分离卷积实际上很有效率
2、 identity shortcut结构对大卷积核非常重要
3、结构重参数化
4、大卷积核在下游任务上的表现比ImageNet分类任务更好
5、大卷积核在小特征图上同样有效(13x13的卷积核、7x7特征图)
三、网络结构
四、实验结果
五、讨论
1、大卷积有更大的感受野
2、大卷积能够学到更多的形状信息
3、密集(普通)卷积和空洞卷积
一、引言
随着ViT在各类任务中刷榜,ViT已经成为了研究热门。是什么让ViT如此给力?有些人认为是多头注意力机制(multi-head self-attention, MHSA),但是也有很多研究者持有不同的观点。
ViT注意力机制的存在,使其能够更容易获得全局信息和局部信息。但是CNN中,除了第一层外很少会采用较大的卷积核,一般都是通过多个小卷积核叠加来增加感受野,只有一些比较老的网络和采用神经网络搜索搜索出来的网络结构会使用较大的卷积核(大于5x5)。那么问题来了:“如果使用大卷积而不是小卷积会怎么样呢?”
作者在卷积神经网络中引入了大尺寸的深度可分离卷积核做实验,发现如下几点使用大卷积核的指导:
(1)大的卷积核计算也可以很有效率;
(2)残差连接结构对大核卷积网络非常重要;
(3)使用小卷积核重参数化来补优化问题;
(4)对比ImageNet分类任务,在下游任务上大卷积核网络表现更好;
(5)即使特征图很小,使用大卷积核也会很有效。
二、大卷积
1、大的深度可分离卷积实际上很有效率
卷积核越大,计算成本越高,使用深度可分离卷积可以有效地降低计算成本。在现代GPU的并行计算架构中,卷积核越小计算效率就越低,卷积核越大,计算密度越大。随着卷积核变大,计算时间应该不会核FLOP增加的一样多,对卷积计算进行底层优化后,计算速度可以更快。
2、 identity shortcut结构对大卷积核非常重要
使用MobileNetV2进行对比,使用13x13的卷积核取代深度可分离卷积中的3x3的卷积核,使用大的卷积增加准确率0.77%,但是没有了identity shortcut结构,准确率只有53.98%。
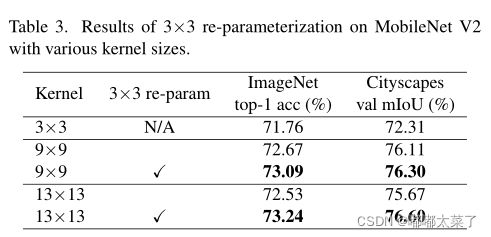
3、结构重参数化
如下图,在MobileNetV2上使用更大的卷积,当卷积核从9增加到13时,模型性能有下降,使用小卷积核进行重参数化,模型性能有了显著的提高(13卷积核好于9)。
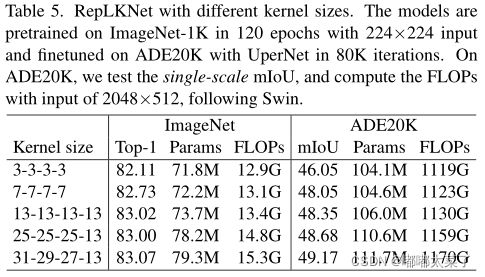
4、大卷积核在下游任务上的表现比ImageNet分类任务更好
下表为RepLKNet在分类任务核语义分割任务上的对比,随着卷积核增加,语义分割任务mIoU指标增加更多。在下游任务大卷积核更有效的原因有2点:
(1)对下游任务来说,感受野越大越好,大卷积核可以带来更大的感受野;
(2)对分类任务来说,形状比较重要,但是传统的CNN更多的是学习到纹理特征,增加卷积核可以使网络学习到更多的形状信息。
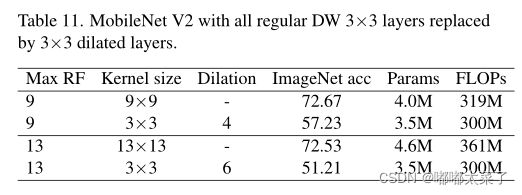
5、大卷积核在小特征图上同样有效(13x13的卷积核、7x7特征图)
将MobielNetV2的last stage卷积核增大,由下表可以看出,大的卷积核在小的特征图同样有效。

三、网络结构
网络结构如下所示。

四、实验结果
1、图像分类

2、语义分割

3、目标检测

五、讨论
1、大卷积有更大的感受野
从下图可以看出,ResNet101核ResNet152感受野几乎相同,而RepLKNet可以明显看到随着卷积核增加,感受野增大。

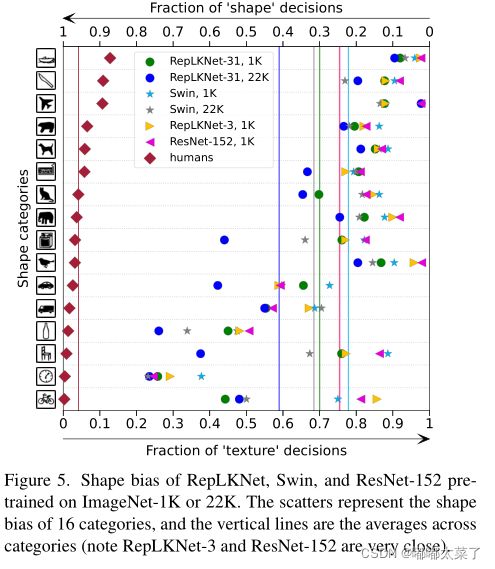
2、大卷积能够学到更多的形状信息
人类视觉对图片进行分类更关注于物体的形状,而卷积网络更多学习到图片的纹理信息,下图对比了几种网络在16种物体上学习到的形状信息的比例,可以看出随着卷积核增加,网络能够学习到更多的形状信息。
3、密集(普通)卷积和空洞卷积
通常采用空洞卷积来增加感受野,下表为MobileNetV2使用空洞卷积和大卷积核的对比,可以看出,稀疏的空洞卷积没法学习到足够的信息,从而导致模型性能下降。