目标检测论文解读复现之十七:融合注意力机制的YOLOv5口罩检测算法
前言
此前出了目标改进算法专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读最新目标检测算法论文,帮助大家解答疑惑。解读的系列文章,本人已进行创新点代码复现,有需要的朋友可关注私信我。
一、摘要
新冠疫情期间正确佩戴口罩可以有效防止病毒的传播,针对公共场所存在的人员密集、检测目标较小等加大检测难度的问题,提出一种以YOLOv5s模型为基础并引入注意力机制融合多尺度注意力权重的口罩佩戴检测算法。在YOLOv5s模型的骨干网络中分别引入4种注意力机制,抑制无关信息,增强特征图的信息表达能力,提高模型对小尺度目标的检测能力。实验结果表明,引入CBAM模块后较原网络mAP值提升了6.9个百分点,在4种注意力机制中提升幅度最明显,而引入NAM模块后在损失少量mAP的情况下参数量最少,最后通过对比实验选用GIoU损失函数计算边界框回归损失,进一步提升定位精度,最终结果较原网络mAP值提升了8.5个百分点。改进模型在不同场景下的检测结果证明了算法对小目标检测的准确率和实用性。
二、网络模型及核心创新点
1. 注意力机制
2. 改进边框回归损失函数
融合CBAM主干网络的yaml文件如下所示:
backbone:
# [from, number, module, args] # [c=channels,module,kernlsize,strides]- 1代表来自上一层输出
[[-1, 1, Focus, [64, 3]], # 0-P1/2 [c=3,64*0.5=32,3] 举例,输出通道数*width_multiple:=64*0.5
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 3, CBAM, [128]], # 举例,3*width_multiple:=3*0.33=1
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 3, CBAM, [256]] ,
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 3, CBAM, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
[-1, 3, CBAM, [1024]], #13
]三、应用数据集
本文所使用的数据集主要挑选自WIDER Face人脸检测数据集和MAFA口罩数据集,在此基础上,通过网络爬虫和实地拍摄对原数据集进行扩充,最终收集到8 880张图片数据,将图片数据按照8∶1∶1的比例划分为训练集、验证集和测试集。
四、实验效果(部分展示)
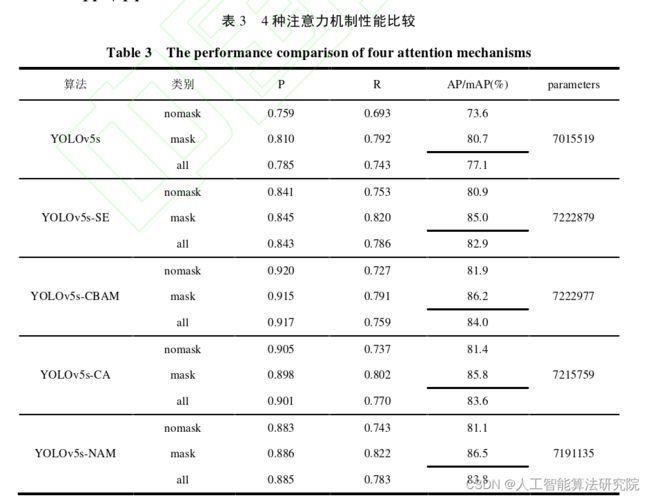
1. 训练时上述参数以及其他超参数均采用相同设置,通过对比实验比较4种注意力机制的引入对于模型性能的影响,得到的结果见下表,根据P、R、m AP以及参数量对几种模型进行多方位比较分析。
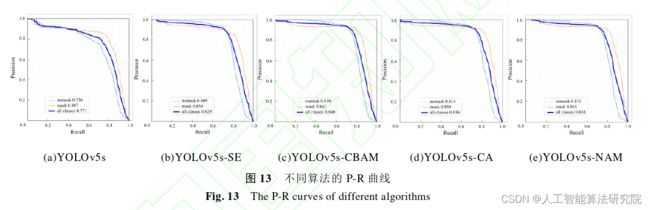
2. P-R曲线作为评估性能的指标之一,以召回率为横轴,精确率为纵轴,同样可以反映出训练的信息,原始YOLOv5s模型以及引入四种注意力机制训练完成后的P-R曲线如下图所示。
3. 分别使用原始YOLOv5s模型以及引入四种注意力机制后的模型对4张图片进行对比检测,检测结果如下图所示,从左到右目标越小、越密集,图中黄色框表示漏检目标。
五、实验结论
通过对比实验发现,YOLOv5s-CBAM模型相较于原模型的m AP值提高了6.9个百分点,是4种注意力机制中提升幅度最大的模块,通过4张不同密集程度的检测图片对比检测效果,YOLOv5s-CBAM在检测的精确度和置信度得分上均取得了不错的效果,证明了引入注意力机制对于模型性能提升的有效性以及对场景中小目标检测的准确性,之后在YOLOv5s-CBAM模型中使用GIoU计算边界框回归损失使模型的m AP值又提高了1.6个百分点,总体较原模型m AP值提高了8.5个百分点,基本满足在人群密集情况下的口罩佩戴检测。
六、投稿期刊介绍
注:论文原文出自李小波,李阳贵,郭宁,范震.融合注意力机制的YOLOv5口罩检测算法[J/OL].图学学报.
https://kns.cnki.net/kcms/detail/10.1034.T.20220823.0910.002.html
解读的系列文章,本人已进行创新点代码复现,有需要的朋友可关注下面公众号,私信我。