jsp中怎么读取图片保存到指定文件夹下最简单例子_PyTorch 中的 tensorboard 可视化...

如果我们实现了一个 CNN 网络,在 mnist 上通过两个卷积层完成分类识别。但是在我们调试代码的过程中,其实往往会想要知道我们的网络训练过程中的效果变化,比如 loss 和 accuracy 的变化曲线。
当然,我们可以将训练过程中的数据数据打印出来,但是一个是不够直观,另外一个是没有图形的表现力强。所以本篇笔记介绍了 tensorboard 来完成可视化的操作。
1. TensorBoard 介绍
tensorboard 一开始是在 TensorFlow 中的可视化工具,它可以用来展示网络图、数据的处理流程、执行过程中的指标变化。特别是在训练网络的时候,网络参数的不同设置(比如:权重、偏置、卷积层数、全连接层数等)。通俗点就是网络训练过程中的各种参数和指标的变化都可以展示成图表的形式,除此之外,还可以展示网络模型的结构,训练数据的照片等。 在 TensorFlow 中的优秀表现,使得 pytorch 从 1.2.0 版本开始,正式自带了 tensorboard。也就可以很方便的在 pytorch 训练中进行可视化了。2. 先 run 一个示例吧
按照我们的习惯,先找一个简单的例子 run 起来,再一步步去学习其中的原理吧。首先我们看一个官方文档的示例:
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter()x = range(100)for i in x: writer.add_scalar('y=2x', i * 2, i)writer.close()首先导入 SummaryWriter,这是一个类,需要实例化出一个对象,这里我们命名为 writer。初始化的参数我们最关心的一个就是 log 文件的地址。如果没有输入就默认为当前文件中的 runs 文件夹,如果没有 runs 文件夹则创建一个。
接下来,我们看到在 for 循环中调用了 writer 的一个方法:add_scalar(),这个函数的参数定义如下:
def add_scalar(self, tag, scalar_value, global_step=None, walltime=None):
我们介绍一下这个方法比较重要的几个参数。这个方法的作用是将我们想要的数据存入 log 文件中,那么这段数据的标签(也就是我们画图时的 title)就是参数 tag,而 scalar_value 就是当前存入的数值(也就是画图时的 y 轴),而 global_step 就是我们在哪一步存入了一次数据(也就是画图时的 x 轴)。
那么在这个循环中,我们可以看到存入的数据标签是 'y=2x',而在第 i 步时存入的数值是 2*i,通过循环相当于将每一步时刻的 y 值都存了进去,也可以理解为将一幅图的每个点坐标存入了 log 文件中。
最后使用 write.close() 终止掉这个对象。

 这里我们可以看到,做出了一个 step 从 0 到 99 的图像,而纵轴则是在对应 step 的 value,最终的图像刚好是一个 y=2x 的斜线。 通过这个例子,我们知道了如何使用 tensorboard 完成一个完整的可视化流程。知道了关键的几个步骤的含义,那么接下来,我们就修改一下之前第二篇笔记的代码,来完成对一个 CNN 训练过程中数据的可视化。
这里我们可以看到,做出了一个 step 从 0 到 99 的图像,而纵轴则是在对应 step 的 value,最终的图像刚好是一个 y=2x 的斜线。 通过这个例子,我们知道了如何使用 tensorboard 完成一个完整的可视化流程。知道了关键的几个步骤的含义,那么接下来,我们就修改一下之前第二篇笔记的代码,来完成对一个 CNN 训练过程中数据的可视化。
3. 可视化 CNN 训练数据
这里使用之前的代码进行修改,当时我们对代码训练过程中的 loss 进行了打印,每过 50 个 step 则计算一次在测试集上的 accuracy,然后打印训练集上的 loss 和测试集上的 accuracy。 我们这里主要看一下训练过程中的代码:writer = SummaryWriter('tb_mnist')for epoch in range(EPOCH): for step, (b_x, b_y) in enumerate(train_loader): # print(b_x.shape); break if cuda_gpu: b_x = b_x.cuda() b_y = b_y.cuda() output = cnn(b_x) loss = loss_func(output, b_y) optimizer.zero_grad() loss.backward() optimizer.step() if step % 50 == 0: test_output = cnn(test_x) pred_y = torch.max(test_output, 1)[1].data if cuda_gpu: pred_y = pred_y.cpu().numpy() else: pred_y = pred_y.numpy() accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0)) print('Epoch: ', epoch, '| train loss: %.4f' % loss.data, '| test accuracy: %.2f' % accuracy) writer.add_scalar("Train/Accuracy", accuracy, step) writer.add_scalar("Train/Loss", loss.item(), step)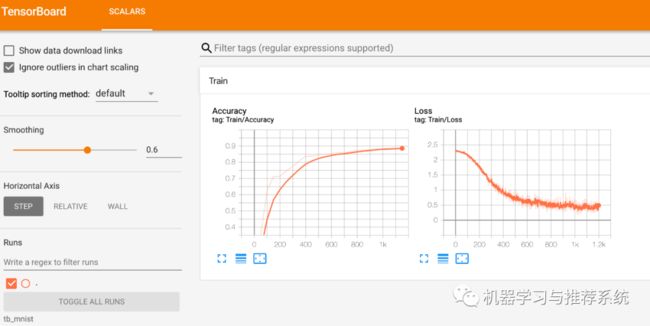
4. 图片和模型的可视化
介绍完了图表的绘制,我们再展示一个官方文档中的例子,来为大家进一步学习 tensorboard 的广泛用途。这里的例子分别是利用 tensorboard 展示图片和网络结构。先看一下官方的代码吧:import torchimport torchvisionfrom torch.utils.tensorboard import SummaryWriterfrom torchvision import datasets, transforms# Writer will output to ./runs/ directory by defaultwriter = SummaryWriter()transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])trainset = datasets.MNIST('mnist_train', train=True, download=True, transform=transform)trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)model = torchvision.models.resnet50(False)# Have ResNet model take in grayscale rather than RGBmodel.conv1 = torch.nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)images, labels = next(iter(trainloader))grid = torchvision.utils.make_grid(images)writer.add_image('images', grid, 0)writer.add_graph(model, images)writer.close()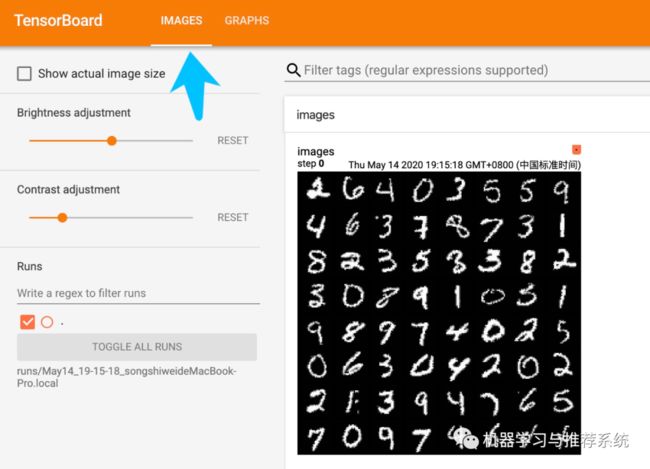
image 示例

graph 示例
这两张图分别展示了 image 和 graph 的效果,一个是 64 张训练时的照片进行展示,拼接成 8*8 的网格状;一个是 resnet50 的网络结构,这个网络结构还支持继续展开,只需要鼠标在上面双击即可,图中的情况就是我进行了适当的展开后的样子。总结
今天的文章我们介绍了 tensorboard 的用途,然后通过几个例子,逐步深入了 tensorboard 的使用,当然它的功能远不止我们文中介绍的内容,但是作为入门已经够用了。如果大家还想再继续深入了解 tensorboard,可以访问官方文档: https://pytorch.org/docs/stable/tensorboard.html 官方文档中还有很多其它 tensorboard 的使用方法介绍,接口清晰而且都有示例。 希望今天的文章可以让大家了解到 tensorboard 的入门使用,在网络训练过程中,有效的可视化可以帮助我们快速定位 bug,更加深入的理解网络的训练效果。动手尝试一下吧~
▼点击成为社区会员 喜欢就点个在看吧