联邦学习--论文汇总(十)
两篇关于压缩模型的联邦学习文章
[1] He C , Annavaram M , Avestimehr S . Group Knowledge Transfer: Federated Learning of Large CNNs at the Edge[J]. 2020.
[2] Caldas S , J Konečny, Mcmahan H B , et al. Expanding the Reach of Federated Learning by Reducing Client Resource Requirements[J]. 2018.
引言概括
针对边缘计算,对于模型规模大、节点多、客户端带宽受限的挑战,今天的两篇都提出了新颖的思想:
在一些图像数据集进行有损压缩是可以接受的,保留关键参数就可以满足需求,现在采用的是将全局模型有损压缩为小模型,客户端对小模型训练后,再压缩至服务器进行解压后聚合,此处颠覆了我们的以往认知,这样的好处是既减少了通信量,又不是很影响精度,解决了客户端数量多、模型规模大的瓶颈。
Group Knowledge Transfer: Federated Learning of Large CNNs at the Edge(组知识迁移:边缘设备的大型CNN联邦学习)
思想: FedGKT可以有效地在边缘上训练小CNN,通过知识蒸馏周期性地将小CNN的知识转移到一个大容量的服务器端CNN。
瓶颈: 扩大卷积神经网络的规模(宽度、深度)有效提高模型的精度,模型太大阻碍边缘设备训练,边缘设备缺乏GPU加速器和足够的内存,无法在资源受限的边缘设备上训练大型CNN。
优点:
- 减少对边缘计算的需求
- 降低大型cnn的通信成本(带宽)
- 异步训练,同时保持与FL相当的模型精度
通信成本:
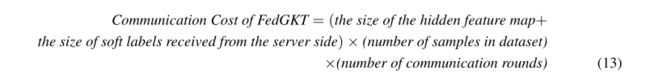
规则
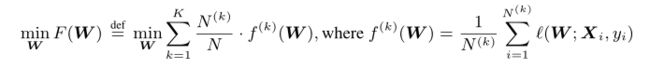
W表示全局CNN在每个用户的网络权重,以前的FedAvg算法:
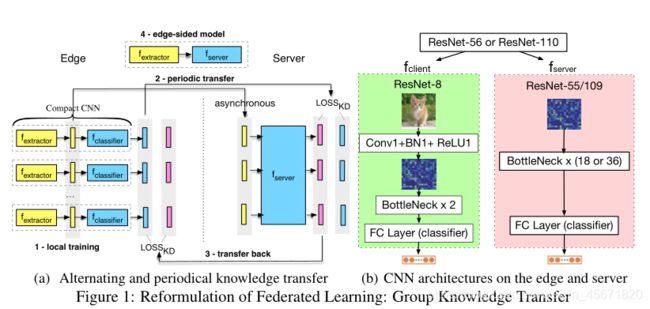
(1)特征提取器,分类,压缩至边缘本地训练
(2)周期性迁移到服务器端
(3)再迁移回边缘端(ResNet-56 or ResNet-110 压缩到边缘端和服务端)
(4)全局模型
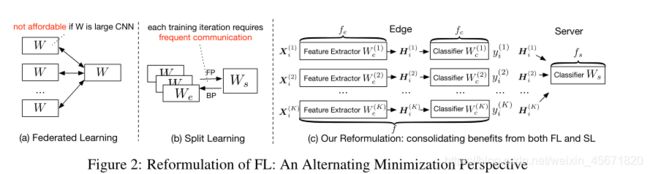
将全局模型优化到非凸模型问题,修改目标函数,同时求解服务端模型和边缘模型,两个分区:
(1)一个小的特征提取模型 W e W_e We, 加入分类器 W c W_c Wc
(2)一个大规模服务端模型 W s W_s Ws
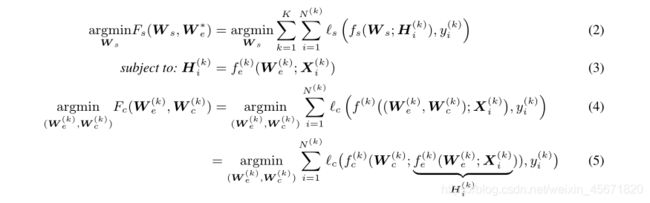
l s l_s ls和 l c l_c lc表示服务器模型和边缘模型的损失函数, f ( k ) f^{(k)} f(k)是包含特征提取器和分类器:
![]()
H i ( k ) H^{(k)}_i Hi(k)是由特征提取器 f e ( k ) f^{(k)}_e fe(k)对第i个样本的特征映射吗,服务器将 H i ( k ) H^{(k)}_i Hi(k)作为输入特征,最终结果由两者堆叠,在本地进行离线推理。
注:可能数据集太小,训练效果不好,易受到改变和干扰,输入不好
解决办法:引入知识蒸馏损失放入到优化方程中,双向迁移:
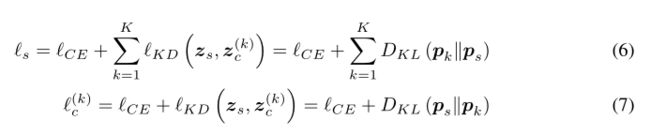
l C E l_{CE} lCE是预测值和真实标签的交叉熵,KL是散度函数

改进的交替最小化,重构优化:
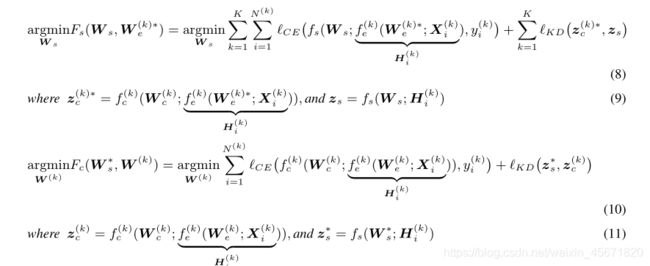
超参数(当精确率稳定,学习率下降):
1.通信轮
2.边缘的epoch:取1
3.服务器的epoch:iid 20 ,non-iid 10
4.服务端的学习率

步骤:
1.在每一轮的训练中,客户端使用本地SGD来训练几个epoch,然后将提取的特征图和相关的日志发送到服务器。
2. 当服务器接收到从每个客户端提取的特征和日志时,它训练更大的服务器端CNN。
3. 服务器将其全局logit发送回每个客户机。
实验
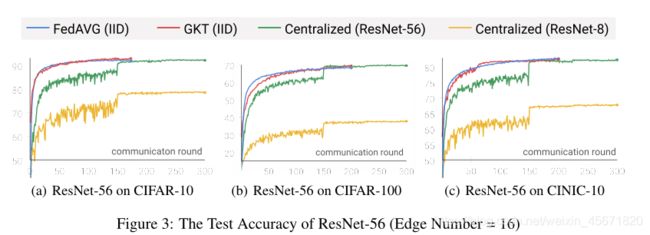
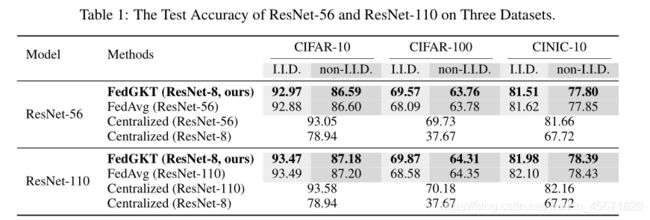
在16个客户端和一个GPU服务器上运行所有数据集和模型。任务是对CIFAR-10、CIFAR-100和CINIC-10上进行图像分类。
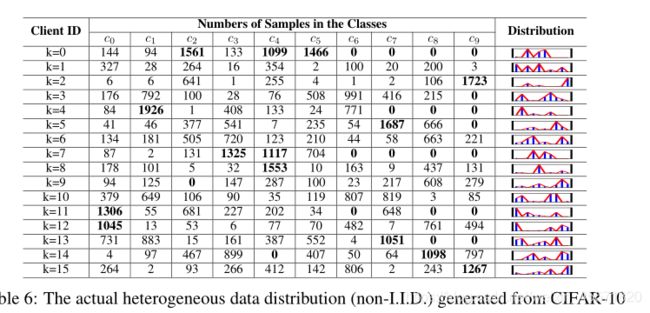
将训练样本分成K个不平衡的分区,测试精度采用top-1,与最好的FedAvg比较,FedProx在大型CNN下性能不如FedAvg,不采用FedMA,不包括归一化层,模型架构:ResNet-56和ResNet-110,设计一个小型的CNN架构ResNet-8,包含8个卷积层的紧凑CNN,有相同的输入维度匹配边缘特征提取器的输出。
数据分布(我之前也是想这样分组):
方法的局限性:
- 隐私安全:但基于以前的差分隐私和多方计算,交换隐藏的特征图比交换模型或梯度更安全。在训练阶段隐藏映射交换。模型或梯度交换可能泄露隐私,缺乏分析
- 通信成本:隐藏向量比权重或梯度小,每个数据点的隐藏向量可以独立传输,FedGKT比梯度或模型交换要求更小的带宽,通信代价取决于数据点的数量,在样本数量非常大,图像分辨率非常高的情况下,方法和分割学习总的来说都有很高的通信成本。
- 标签缺陷:只能用于监督学习,缺乏足够的标签
- 可伸缩性:在跨设备设置中,我们需要使用大量的智能手机协同训练模型(如客户端数量高达100万)。
Expanding the Reach of Federated Learning by Reducing Client Resource Requirements(通过减少客户机资源需求扩展联邦学习的范围)
背景
网络速度和节点数量是区分FL与传统数据中心分布式学习的两个核心系统方面,网络带宽可能会慢几个数量级,而工作节点的数量可能会大几个数量级,导致在训练阶段系统地排除带宽或网络访问受限的客户端,从而降低了这些模型的用户体验。
在训练和推理方面,深度模型往往需要大量的计算资源、大模型,采用有损压缩方法:修剪网络和模型蒸馏
方法可行性:
1.服务器和客户端可以交换
2.基于Dropout ,使每个设备在更小的模型上进行本地操作,提供可应用于服务器上更大的全局模型的更新。
3.彼此兼容,而且与现有的客户机到服务器压缩兼容。
4.客户机到服务器的更新大小减少。
5.局部训练过程现在对每个梯度计算需要更少的FLOPS,减少了局部计算代价。
思想
(1)在服务器到客户端的全局模型上使用有损压缩;
(2) Federated Dropout,它允许用户在全局模型的更小的子集上进行有效的本地训练,同时也减少了客户端到服务器的通信和本地计算,降低了通信成本,同时也降低了本地训练的计算成本。
(3) 使用随机的Hadamard变换减少后续量化产生的误差,向量的信息更均匀地分布在其分量上。
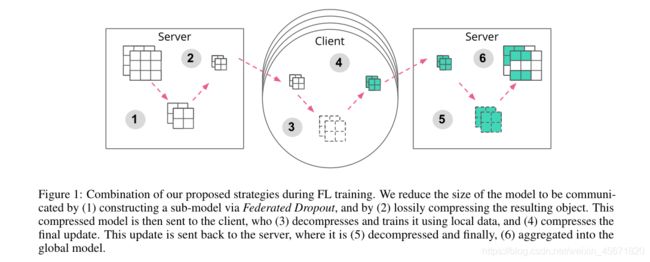
方法:
-
有损压缩: 使用轻量级有损压缩技术,应用于已经训练过的模型,并且在反向时(即解压后)保持模型的质量。
-
将模型中的每个待压缩权矩阵重新塑造为向量w,基变换,子样本,量化结果向量,通过网络发送,逆变换,获得w的噪声版本
基变换:减少量化等扰动产生的误差,Hadamard变换更均匀地将矢量的信息分布在其维度之间,应用Kashin[1977]的经典结果,在每个维度上尽可能多地传播矢量信息,与使用随机Hadamard变换相比,Kashin的表示减少了后续量化产生的错误。
子样本:每个权重矩阵中元素的1−s部分归零,适当地重新缩放剩下的值,只传递非零值和允许恢复相应索引的随机种子
概率量化:量化后区间是w的无偏估计,分成 2 q 2^q 2q个区间,当落入区间后,用此区间的最大或最小值代替[第一篇汇总的论文,Konen J , Mcmahan H B , Yu F X , et al. Federated Learning: Strategies for Improving Communication Efficiency[J]. 2016]。
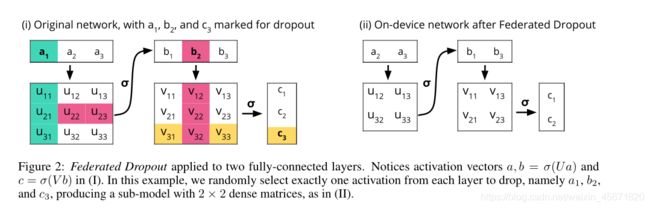
Federated Dropout: 每个客户端不是局部训练一个更新到整个全局模型,而是训练一个更新到更小的子模型。这些子模型是全局模型的子集,因此,计算出的局部更新可以很自然地解释为对更大的全局模型的更新。为了节约计算和通信成本,用0代替固定数量的全连接层激活函数,紫墨鑫具有相同的简化架构。即使一些单位被删除了,激活仍然与原始的权重矩阵相乘,它们只是有一些无用的行和列。服务器可以将必要的值映射到这个简化的体系结构中,这意味着只有必要的系数被传输到客户端,重新打包为更小的密集矩阵。
所有矩阵相乘的维数都更小, 2.需要应用更少的滤波器(对于卷积层)
(1)通过Federated Dropout 构造子模型
(2)有损压缩,并发送到客户端
(3)客户端解压,使用本地数据训练
(4)压缩更新,发送到服务器
(5)解压
(6)聚合到全局更新
实验:
数据集 MNIST , CIFAR-10 和扩展MNIST或EMNIST ,测试FedAvg和有损压缩
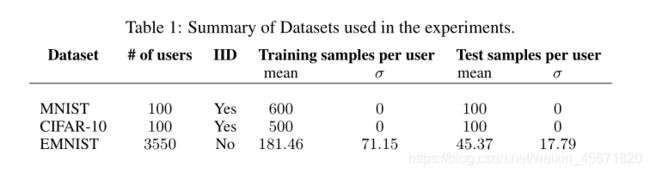
模型组成: 两个5X5的卷积层CNN,32通道,第二个是64通道,每个连接2X2的最大池化层,有512个单元的全连接层和reLu激活函数,最后连接softmax输出层,超过 1 0 6 10^6 106参数。
有损压缩(改变三个变量):
- 基变换类型:无变换或单位变换、随机Hadamard transform (HD) and Kashin’s representation (K).
- 子样本率s,保留的重量比例
- 量化位q的个数
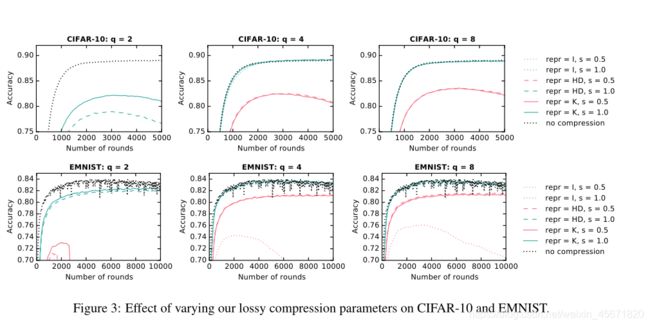
实验结果:
(1)对于每个模型,我们都能够找到一个至少与我们的基线匹配的压缩参数设置
(2) Kashin表示对激进量化值是最有用的
(3)子抽样在服务器到客户端设置中似乎并不是那么有用
(4)改变了模型每一层上保留的神经元(或卷积层的过滤器)的百分比(联邦退出率)

未来:
- 引入步长,考虑对不同子模型的使用有效性
- 更小的、也许是个性化的子模型最终被聚合成一个更大、更复杂的模型,可以由服务器管理。