YOLOv5模型环境搭建及使用google colab训练
环境搭建
环境
- ubuntu 18.04 64bit
- GTX 1070Ti
- anaconda with python 3.8
- pytorch 1.7.1
- cuda 10.1
- yolov5 5.0.9
为了方便使用 yolov5
目标检测,有网友已经将其做成了库,提交到了官方的索引库 pypi
上,这样,我们就可以直接使用 pip进行安装了,其项目地址: https://github.com/fcakyon/yolov5-pip
安装
首先创建一个干净的 python
虚拟环境
conda create -n yolov5pip python=3.8
conda activate yolov5pip
如果 python
版本大于3.7,直接使用 pip
安装
pip install yolov5
如果 python
的版本是3.6的话,需要安装指定版本的 numpy
和 matplotlib
pip install "numpy>=1.18.5,<1.20" "matplotlib>=3.2.2,<4"
pip install yolov5
命令行的使用
yolov5
库安装好后,同时会生成 yolov5
的命令行工具,其使用方法与源码中的 detect.py
非常类似,如下
yolov5 detect --source 0 # webcam
file.jpg # image
file.mp4 # video
path/ # directory
path/*.jpg # glob
rtsp://170.93.143.139/rtplive/470011e600ef003a004ee33696235daa # rtsp stream
rtmp://192.168.1.105/live/test # rtmp stream
http://112.50.243.8/PLTV/88888888/224/3221225900/1.m3u8 # http stream
测试发现,cpu的环境下,图片、视频检测都没问题,但是如果使用 gpu的话,就会报错了,这可能是目前版本的 bug
YOLOv5 2021-9-15 torch 1.7.1+cu101 CUDA:0 (NVIDIA GeForce GTX 1070 Ti, 8116.4375MB)
Fusing layers…
Model Summary: 283 layers, 7276605 parameters, 0 gradients
Traceback (most recent call last):
File “/home/xugaoxiang/anaconda3/envs/yolov5pip/bin/yolov5”, line 8, in
sys.exit(app())
File “/home/xugaoxiang/anaconda3/envs/yolov5pip/lib/python3.8/site-packages/yolov5/cli.py”, line 11, in app
fire.Fire(
File “/home/xugaoxiang/anaconda3/envs/yolov5pip/lib/python3.8/site-packages/fire/core.py”, line 141, in Fire
component_trace = _Fire(component, args, parsed_flag_args, context, name)
File “/home/xugaoxiang/anaconda3/envs/yolov5pip/lib/python3.8/site-packages/fire/core.py”, line 466, in _Fire
component, remaining_args = _CallAndUpdateTrace(
File “/home/xugaoxiang/anaconda3/envs/yolov5pip/lib/python3.8/site-packages/fire/core.py”, line 681, in _CallAndUpdateTrace
component = fn(*varargs, **kwargs)
File “/home/xugaoxiang/anaconda3/envs/yolov5pip/lib/python3.8/site-packages/torch/autograd/grad_mode.py”, line 26, in decorate_context
return func(*args, **kwargs)
File “/home/xugaoxiang/anaconda3/envs/yolov5pip/lib/python3.8/site-packages/yolov5/detect.py”, line 120, in run
model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.parameters()))) # run once
TypeError: zeros() argument after * must be an iterable, not int
除了 detect检测之外,yolov5还支持 train、val和export
模型训练的命令如下
yolov5 train --data coco.yaml --cfg yolov5s.yaml --weights '' --batch-size 64
yolov5m 40
yolov5l 24
yolov5x 16
另外关于 val和 export命令的使用,可以通过 --help来查看其具体支持的参数,如
yolov5 export --help
在Python中使用
库安装好了,就可以在 python中调用了,来看个最简单的示例
# 导入模块
import yolov5
# 载入模型
model = yolov5.load('yolov5s.pt')
# 待检测的图片
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# 推理,默认参数
# results = model(img)
# 使用特定尺寸进行推理
# results = model(img, size=1280)
# 数据增强,能够检测出更多的目标,当然也有可能出现误检
results = model(img, augment=True)
# 检测结果数据解析,所属类别、置信度、目标位置信息
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, x2, y1, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# 显示检测结果
results.show()
# 保存检测结果图片
results.save(save_dir='results/')
将官方提供的 yolov5s模型下载下来,然后执行上述脚本,检测结果如下

由于使用了 augment参数,检测结果多了个 person,默认参数的检测结果与原版 yolov5检测结果一致
使用GPU加速检测
首选需要安装 gpu版本的 pytorch,这里选择 1.7.1
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
跟原版一样,通过 device参数来指定 cuda加速
from yolov5 import YOLOv5
# 模型路径
model_path = 'yolov5s.pt'
device = "cuda" # or "cpu"
# 模型初始化
yolov5 = YOLOv5(model_path, device)
# 待检测图片
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# 推理,默认参数
results = yolov5.predict(image)
# 使用特定尺寸进行推理
results = yolov5.predict(image, size=1280)
# 数据增强,能够检测出更多的目标,当然也有可能出现误检
# results = yolov5.predict(image, augment=True)
# 多个参数一起使用
# results = yolov5.predict(image, size=1280, augment=True)
# 如果需要检测多张图片的话,可以使用列表
# results = yolov5.predict([image1, image2], size=1280, augment=True)
# 检测结果数据解析,所属类别、置信度、目标位置信息
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, x2, y1, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# 显示检测结果
results.show()
# 保存检测结果
results.save(save_dir='results/')
使用google colab训练YOLOv5模型
colab是什么
colab是google提供的一个jupyter notebook工具,支持google drive、tensorflow在内的google全家桶,主要用于机器学习的开发和研究。colab最大的好处是给广大的AI开发者提供免费的gpu资源,可以在上面非常轻松地运行如tensorflow、pytorch、keras等深度学习框架。
YOLOv5模型训练
来到google drive,点击左上方的New

创建一个新的文件夹colab

接下来,将准备好的口罩数据集上传到colab文件夹中,这个数据集,前面我们在YOLOv5模型训练的时候用过,可以到下面的地址下载
原始链接 https://public.roboflow.ai/object-detection/mask-wearing
接下来创建colab,点击New --> More --> Google Colaboratory

创建好notebook后,需要来到 修改 --> 笔记本设置 设置gpu加速

硬件加速器,选择GPU,保存

点击右上角的 连接,选择 连接到托管代码执行程序。

GPU环境设置好后,我们就可以在notebook中查看colab提供的gpu资源了,使用!nvidia-smi命令

可以看到google提供的硬件是是tesla P100,显存是16G。貌似每次colab分配的gpu是不一样的,有时候是P100,有时候是T4
下面看看pytorch的安装情况,执行
import torch
torch.__version__
可以看到平台已经默认安装,且版本是1.6,CUDA的版本是10.1

如果需要安装第三方库,可以在单元格中直接安装,如!pip3 install torchvision

接下来就把google drive挂载过来,这样就可以在colab中使用google drive中的资源了
import os
from google.colab import drive
drive.mount('/content/drive')
path = "/content/drive/My Drive"
os.chdir(path)
os.listdir(path)
执行上述单元格中的代码,会要求进行输入验证码


google drive就会被挂载到目录/content/drive,后续就可以对google drive里的文件进行操作了

准备工作搞定好,我们就可以下载YOLOv5的源码了,在单元格中执行
git clone https://github.com/ultralytics/yolov5.git
然后切换到google drive,修改yolov5/models/yolov5s.yaml,将原来的nc: 80改为nc: 2
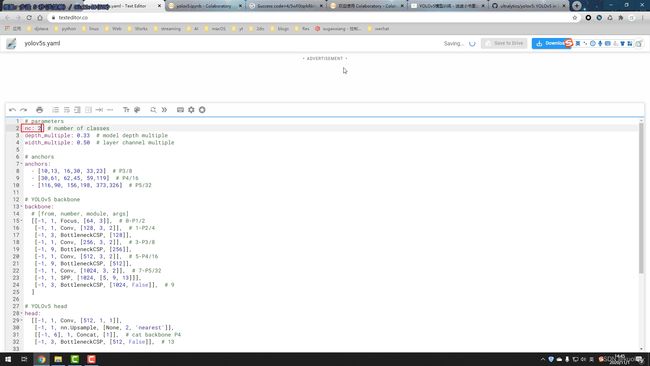
然后就可以来到colab,进入到yolov5目录,在单元格中执行训练命令
python train.py --data ../mask/data.yaml --cfg models/yolov5s.yaml --weights '' --batch-size 64
训练时,出现了pyyaml模块的一个错误,这是由于pyyaml版本过低的原因,我们升级下就可以解决
pip install -U pyyaml

继续训练

