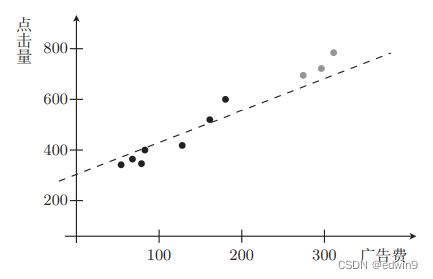
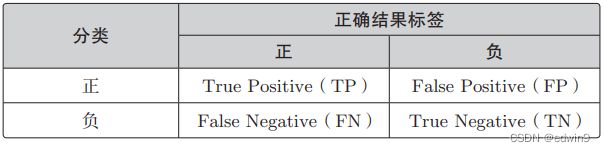
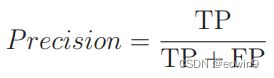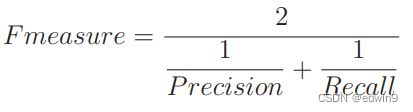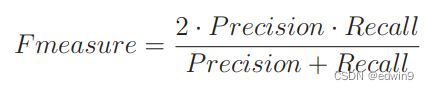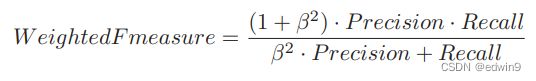给定一个数组nums,编写一个函数将所有0移动到数组的末尾,同时保持非零元素的相对顺序。请注意,必须在不复制数组的情况下原地对数组进行操作。classSolution{public:voidmoveZeroes(vector&nums){intn=nums.size();intleft=0;intright=0;while(right
设备通信技术选型:MQTT和AMQP
呆呆智
网络协议javaspring开发语言mqttamqp
1.MQTT有没有消息队列和持久化?MQTT协议本身不定义消息队列,它只是:客户端发送消息到"主题"(topic)Broker(服务器)收到后转发给订阅者持久化支持有限:QoS1/2消息在服务器端可以短期持久化,防止中断丢失(比如写到磁盘或者内存)。但不是像AMQP那种强事务的长时间存储、排队消费。总结:MQTT是"消息中转",不是"消息存储和排队"。存一下下,只是为了保障重发确认流程,而不是持久
用IDEA内置的AI通义灵码,开发效率直接起飞!
作为老Java开发,在用上IDEA内置的通义灵码插件,真的有种"回不去了"的感觉。这玩意儿不是简单的代码补全工具,简直就是个24小时待命的编程助手,让我来唠唠它到底有多香。但是仅供参考,对于一些初学者或者对代码还不是很熟悉的伙伴,不建议使用ai,尽量自己手敲,还能提高代码熟悉度,出了bug还能自己找出来问题所在,ai只能作为辅助我们进行学习和开发1.写代码像聊天一样自然以前写代码最烦的就是那些模板
随机近似算法:步长序列选择的理论与金融实践
随机近似算法:步长序列选择的理论与金融实践摘要随机近似算法作为统计学习与优化的核心工具,其收敛性与稳定性高度依赖步长序列的设计。本文系统阐述步长序列的理论约束与工程选择策略,并结合金融波动率估计场景,展示算法在动态系统参数估计中的实践价值。1.随机近似算法的数学框架随机近似算法通过随机样本的迭代更新逼近目标参数,其核心迭代式为:θn+1=θn+an(Yn−g(θn))\theta_{n+1}=\t
MQTT 和 HTTP 有什么本质区别?
冰糖心书房
MQTThttp网络协议网络
MQTT和HTTP的本质区别在于它们设计的初衷和核心工作模式完全不同。它们是为解决不同问题而创造的两种工具。简单来说:HTTP就像是去图书馆问问题:你(客户端)主动去找图书管理员(服务器),问一个具体的问题(请求),然后站在原地等待他给你找来答案(响应)。问完一个问题,这次交流就结束了。MQTT就像是订阅了一份杂志:你(订阅者)去邮局(Broker)说“我对《科技先锋》这个主题感兴趣”,然后回家。
FastAPI vs Flask vs Django:Python Web框架全面对比
天天进步2015
pythonpythonfastapiflask
Python作为最受欢迎的编程语言之一,其Web开发生态极为丰富。FastAPI、Flask和Django是当前主流的三大PythonWeb框架,各有千秋。本文将从架构设计、开发效率、性能表现、生态支持、适用场景等方面,全面对比这三大框架,帮助开发者选择最适合自己的技术栈。目录框架简介架构设计与理念开发效率与易用性性能对比生态与扩展性典型应用场景总结与选型建议参考资料框架简介FastAPI定位:新
【AI成长会】ubuntu 安装运行rust
行云流水AI笔记
ubunturustlinux
在Ubuntu上用Rust编写第一个程序从你的输出可以看出,Rust已经成功安装在你的Ubuntu系统上了。现在我们来编写并运行第一个Rust程序,整个过程需要几个简单的步骤:一、配置Shell环境(如果需要)虽然安装提示可能需要重启Shell,但你也可以直接在当前会话中配置环境:#对于bash/zsh等shell."$HOME/.cargo/env"#如果你使用fishshellsource"$
LeetCode Hot100(回溯)
asom22
LeetCodeHot100题解leetcode算法职场和发展
46.全排列题意给定一个不含重复数字的数组nums,返回其所有可能的全排列。你可以按任意顺序返回答案。题解因为是所有的排列组合,我们每一个位置都取一遍数组的所有元素看看有没有重复的即可代码importjava.util.*;publicclassSolution{publicstaticvoidmain(String[]args){int[]nums={1,2,3};permute(nums);}
HTTP 请求基础知识
污领巾
http网络协议网络
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言HTTP请求方法GETPOSTPUTDELETE其他方法HTTP请求结构常用请求头实际应用示例响应状态码前言HTTP(HypertextTransferProtocol)是互联网上应用最广泛的协议之一,用于客户端和服务器之间的通信。HTTP请求方法GET用途:请求获取指定资源特点:参数通过URL传递可以被缓存有长度限制不应
登录操作系统报错:-bash: fork: Cannot allocate memory
Lz__Heng
故障处理运维Linux运维服务器linux
问题描述服务器无法正常访问,检查操作系统监控,CPU使用率过高SSH远程登录服务器报错:-bash:fork:Cannotallocatememory排查思路该报错一般为pid进程数量超出,可以排查当前操作系统pid数量和相关设置如下:#查看当前操作系统的内核PID_max参数设置sysctl-a|greppid#默认为32768#查看当前操作系统systctl中是否有对pid的大小进行额外设置c
Reqable:跨平台HTTP开发与调试工具
在现代软件开发中,HTTP请求的调试和测试是开发者日常工作的重要组成部分。Reqable是一款功能强大且易于使用的跨平台HTTP开发与调试工具,它简化了HTTP请求的构建、发送和响应分析过程,为开发者提供了极大的便利。一、Reqable的主要功能Reqable提供了丰富的功能,帮助开发者高效地进行HTTP开发和调试:多平台支持:Reqable支持Windows、macOS和Linux操作系统,确保
DAY 43 复习日
yizhimie37
python训练营打卡笔记深度学习
@浙大疏锦行https://blog.csdn.net/weixin_45655710第一步:寻找并准备图像数据集在Kaggle等平台上,你可以找到大量用于图像分类任务的数据集,例如英特尔图像分类数据集(IntelImageClassification)或手写数字识别数据集(DigitRecognizer)。对于初学者,一个更便捷的选择是使用像TensorFlow或PyTorch这样深度学习框架内
vscode插件和源码通过命令进行通信
zhouhangzooo
【VisualStudioCode】vscode通信vscode命令
本文讲述一下vscode插件和源码通过命令进行通信原文链接:https://zhouhangzooo.github.io/2019/04/10/vscode插件与源码通信/在之前"vscode插件与webview相互通信"文章中,讲述webview和插件进行通信,里面有个注册命令,之前文章没有详细代码,其实代码vscoode官网都有,##接下来要说命令,那么先贴一下注册命令的代码123456789
如何在CentOS7上搭建自己的GitLab仓库详解
ytttr873
gitlab
在CentOS7上搭建自己的GitLab仓库的详细步骤如下:更新系统:在开始之前,确保您的系统已经更新到最新版本。打开终端,并执行以下命令:sudoyumupdate-y安装依赖:在安装GitLab之前,需要安装一些依赖项。执行以下命令来安装所需的软件包:sudoyuminstall-ycurlpolicycoreutils-pythonopenssh-server添加GitLab仓库:执行以下命
浏览器的垃圾回收机制
甘露寺
js浏览器javascript前端
深入解析现代浏览器的垃圾回收机制:分代回收与标记清除算法本文详细探讨了Chrome、Firefox等现代浏览器中JavaScript引擎的垃圾回收(GC)原理,重点讲解分代回收策略和标记清除/整理算法的工作流程,并通过示例帮助理解内存自动管理背后的机制。为什么需要垃圾回收?JavaScript是一种自动内存管理的语言。开发者通常不需要手动分配或释放内存(如C/C++中的malloc/free)。这
新手友好!从HTTP到HTTPS再到HTTP/2:网站通信的进化之路
甘露寺
浏览器httphttps网络协议
从HTTP到HTTPS再到HTTP/2:网站通信的进化之路作为一名刚接触Web开发的新手,你可能经常听说HTTPS和HTTP/2,但不太清楚它们具体解决了什么问题,又是如何一步步优化我们上网体验的。这篇博客就用大白话,带你了解网站通信技术的进化史!第一章:HTTP的烦恼-裸奔的网络想象一下,你在网上冲浪,就像在公共场所大声聊天。问题一:信息裸奔,谁都能偷听!HTTP协议:早期的网站大多使用HTTP
for...in 与 for...of的区别是啥?用错后果很严重
for…in与for…of循环详解在JavaScript中,for...in和for...of是两种常用的循环语句,但它们在使用场景和行为上有显著区别。下面我将详细解释它们的差异,并通过示例代码进行说明。核心区别对比表特性for...infor...of遍历目标对象的可枚举属性可迭代对象的值返回值类型键名(key)值(value)适用对象普通对象、数组(不推荐)数组、字符串、Map、Set、Nod
v-if、display、visibility、opacity隐藏元素的区别
甘露寺
前端vuereact
前端元素隐藏与条件渲染完全指南(Vuevs.Reactvs.CSS)本文对比v-if、v-show、display:none、opacity:0、visibility:hidden以及React条件渲染的差异,帮你彻底掌握它们的适用场景!核心概念1.DOM树vs.渲染树DOM树:完整的HTML节点结构(无论是否隐藏)。渲染树:浏览器实际绘制到屏幕上的内容(隐藏元素可能被跳过)。2.关键差异特性是否
JavaScript 原型链继承中的引用类型陷阱
JavaScript原型链继承中的引用类型陷阱本文通过一个生动的案例,解析JavaScript原型链继承中引用类型属性的共享问题,帮助开发者理解原型链机制并避免常见陷阱。问题代码展示//父类构造函数functionAnimal(){this.skills=['eat','sleep'];//引用类型属性this.mouse=1;//基本类型属性this.name='Animal';this.sho
gsap动画库
请叫我斌哥哥
工具动画
gsap动画库GSAP文档首先导入gsap动画库npmigsap-S安装好了在项目中引用importgsapfrom"gsap"普通的页面使用gsap.to('类名',{动画属性})//我们也可以使用时间线来写动画//创建一个时间线,然后再使用链式语法,做过视频剪辑的同学可能理解的更深vartl=gsap.timeline();tl.to(".box1",{rotation:27,x:100,du
基于python快速部署属于你自己的页面智能助手
小张Tt
python人工智能腾讯云AI代码助手
文章目录前言一、实现目标二、代码解析2.1目录结构2.2后端:Flask服务器的搭建2.2.1安装Flask2.2.2创建Flask应用2.3实现聊天界面与消息交互2.3.1创建聊天界面三、跨域问题的解决3.1安装flask-cors3.2在Flask中启用CORS五效果展示前言 AI聊天机器人已经成为了许多应用场景中的重要组成部分。通过与用户的对话,聊天机器人不仅能够提升用户体验,还能通过不断
✨【CosyVoice2-0.5B 实战】Segmentation fault (core dumped) 终极解决方案 (保姆级教程)
杨靳言先
语音识别语音生成python人工智能
【CosyVoice2-0.5B实战】Segmentationfault(coredumped)终极解决方案|torchaudio.save崩溃全流程排查与替代方案(保姆级教程)“运行没报错就是胜利,结果没崩溃就是奇迹。”——每一位搞TTS的开发者内心独白本文聚焦使用CosyVoice2-0.5B进行TTS推理过程中,常见的torchaudio.save()崩溃问题——Segmentationfa
23种设计模式——单例模式:独一无二的王者设计模式
山海上的风
设计模式单例模式java
单例模式:独一无二的王者设计模式“在我的代码王国里,只能有一个国王!”——单例模式宣言单例模式是什么?想象一下:太阳系只能有一个太阳☀️一个国家只能有一个国王一台电脑只能有一个任务管理器这就是单例模式!它确保一个类只有一个实例,并提供全局访问点。就像你永远不需要第二个任务管理器一样!它是一种创建型的模式!为什么要用单例模式?场景没有单例使用单例数据库连接每次操作都新建连接,资源爆炸!全局共享一个连
c# 利用 GZipStream 压缩解压缩文件(所有类型的文档)
山海上的风
c#
c#利用GZipStream压缩解压缩文件(所有类型的文档)usingSystem;usingSystem.Collections.Generic;usingSystem.IO;usingSystem.IO.Compression;usingSystem.Linq;usingSystem.Text;usingSystem.Threading.Tasks;namespaceGZipStream_压缩
树莓派(Raspberry Pi)常见的各种引脚介绍
qq_39717490
单片机嵌入式硬件
树莓派(RaspberryPi)常见的各种引脚介绍_树莓派引脚-CSDN博客以下为全部文章内容的复制本文将为您详细讲解树莓派(RaspberryPi)常见的各种引脚,以及它们的特点、区别和优势。树莓派是一款非常受欢迎的单板计算机,它拥有多个GPIO(通用输入输出)引脚,这些引脚可以用于各种电子项目和交互式应用。1.树莓派引脚概述树莓派有多种型号,包括RaspberryPi1、2、3和4。每种型号都
ubuntu系统的树莓派人脸识别视频(转载哔哩哔哩)
qq_39717490
ubuntu音视频linux
树莓派进阶玩法|人脸识别项目教程_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1uv4y1g7aB?spm_id_from=333.337.search-card.all.click&vd_source=f9b5cbd9734c647ef133bdde5c02cfd4,视频播放量34013、弹幕量29、点赞数690、投硬币枚数247、收藏人数1968
Bagel: 开源协作式AI数据管理平台的使用指南
llzwxh888
人工智能python
Bagel:开源协作式AI数据管理平台的使用指南引言在人工智能和机器学习领域,高质量的数据集对于模型训练和推理至关重要。Bagel作为一个开源的协作式AI数据管理平台,为开发者和研究人员提供了一个强大的工具,用于创建、共享和管理推理数据集。本文将深入探讨Bagel的特性、安装方法以及如何使用它来处理和管理向量数据。Bagel简介Bagel(OpenInferenceplatformforAI)可以
C语言---深入理解指针(3)
星竹晨L
C语言c语言
目录1字符指针变量2数组指针变量2.1什么是数组指针变量2.2数组指针变量的初始化3二维数组传参的本质4函数指针变量4.1两个有趣的代码4.2typedef关键字5函数指针数组6函数指针数组的应用---计算器的实现6.1计算器的一般实现6.2利用函数指针数组实现6.3一般实现的改进1字符指针变量在指针的类型中有一种指针类型为字符指针char*,一般使用:#includeintmain(){char
windows下源码安装golang
616050468
golang安装golang环境windows
系统: 64位win7, 开发环境:sublime text 2, go版本: 1.4.1
1. 安装前准备(gcc, gdb, git)
golang在64位系
redis批量删除带空格的key
bylijinnan
redis
redis批量删除的通常做法:
redis-cli keys "blacklist*" | xargs redis-cli del
上面的命令在key的前后没有空格时是可以的,但有空格就不行了:
$redis-cli keys "blacklist*"
1) "blacklist:12:
[email protected] 方括号表达示
方括号表达式
描述
[[:alnum:]]
字母和数字混合的字符
[[:alpha:]]
字母字符
[[:cntrl:]]
控制字符
[[:digit:]]
数字字符
[[:graph:]]
图像字符
[[:lower:]]
小写字母字符
[[:print:]]
打印字符
[[:punct:]]
标点符号字符
[[:space:]]
2048源码(核心算法有,缺少几个anctionbar,以后补上)
不懂事的小屁孩
2048
2048游戏基本上有四部分组成,
1:主activity,包含游戏块的16个方格,上面统计分数的模块
2:底下的gridview,监听上下左右的滑动,进行事件处理,
3:每一个卡片,里面的内容很简单,只有一个text,记录显示的数字
4:Actionbar,是游戏用重新开始,设置等功能(这个在底下可以下载的代码里面还没有实现)
写代码的流程
1:设计游戏的布局,基本是两块,上面是分
jquery内部链式调用机理
换个号韩国红果果
JavaScriptjquery
只需要在调用该对象合适(比如下列的setStyles)的方法后让该方法返回该对象(通过this 因为一旦一个函数称为一个对象方法的话那么在这个方法内部this(结合下面的setStyles)指向这个对象)
function create(type){
var element=document.createElement(type);
//this=element;
你订酒店时的每一次点击 背后都是NoSQL和云计算
蓝儿唯美
NoSQL
全球最大的在线旅游公司Expedia旗下的酒店预订公司,它运营着89个网站,跨越68个国家,三年前开始实验公有云,以求让客户在预订网站上查询假期酒店时得到更快的信息获取体验。
云端本身是用于驱动网站的部分小功能的,如搜索框的自动推荐功能,还能保证处理Hotels.com服务的季节性需求高峰整体储能。
Hotels.com的首席技术官Thierry Bedos上个月在伦敦参加“2015 Clou
java笔记1
a-john
java
1,面向对象程序设计(Object-oriented Propramming,OOP):java就是一种面向对象程序设计。
2,对象:我们将问题空间中的元素及其在解空间中的表示称为“对象”。简单来说,对象是某个类型的实例。比如狗是一个类型,哈士奇可以是狗的一个实例,也就是对象。
3,面向对象程序设计方式的特性:
3.1 万物皆为对象。
C语言 sizeof和strlen之间的那些事 C/C++软件开发求职面试题 必备考点(一)
aijuans
C/C++求职面试必备考点
找工作在即,以后决定每天至少写一个知识点,主要是记录,逼迫自己动手、总结加深印象。当然如果能有一言半语让他人收益,后学幸运之至也。如有错误,还希望大家帮忙指出来。感激不尽。
后学保证每个写出来的结果都是自己在电脑上亲自跑过的,咱人笨,以前学的也半吊子。很多时候只能靠运行出来的结果再反过来
程序员写代码时就不要管需求了吗?
asia007
程序员不能一味跟需求走
编程也有2年了,刚开始不懂的什么都跟需求走,需求是怎样就用代码实现就行,也不管这个需求是否合理,是否为较好的用户体验。当然刚开始编程都会这样,但是如果有了2年以上的工作经验的程序员只知道一味写代码,而不在写的过程中思考一下这个需求是否合理,那么,我想这个程序员就只能一辈写敲敲代码了。
我的技术不是很好,但是就不代
Activity的四种启动模式
百合不是茶
android栈模式启动Activity的标准模式启动栈顶模式启动单例模式启动
android界面的操作就是很多个activity之间的切换,启动模式决定启动的activity的生命周期 ;
启动模式xml中配置
<activity android:name=".MainActivity" android:launchMode="standard&quo
Spring中@Autowired标签与@Resource标签的区别
bijian1013
javaspring@Resource@Autowired@Qualifier
Spring不但支持自己定义的@Autowired注解,还支持由JSR-250规范定义的几个注解,如:@Resource、 @PostConstruct及@PreDestroy。
1. @Autowired @Autowired是Spring 提供的,需导入 Package:org.springframewo
Changes Between SOAP 1.1 and SOAP 1.2
sunjing
ChangesEnableSOAP 1.1SOAP 1.2
JAX-WS
SOAP Version 1.2 Part 0: Primer (Second Edition)
SOAP Version 1.2 Part 1: Messaging Framework (Second Edition)
SOAP Version 1.2 Part 2: Adjuncts (Second Edition)
Which style of WSDL
【Hadoop二】Hadoop常用命令
bit1129
hadoop
以Hadoop运行Hadoop自带的wordcount为例,
hadoop脚本位于/home/hadoop/hadoop-2.5.2/bin/hadoop,需要说明的是,这些命令的使用必须在Hadoop已经运行的情况下才能执行
Hadoop HDFS相关命令
hadoop fs -ls
列出HDFS文件系统的第一级文件和第一级
java异常处理(初级)
白糖_
javaDAOspring虚拟机Ajax
从学习到现在从事java开发一年多了,个人觉得对java只了解皮毛,很多东西都是用到再去慢慢学习,编程真的是一项艺术,要完成一段好的代码,需要懂得很多。
最近项目经理让我负责一个组件开发,框架都由自己搭建,最让我头疼的是异常处理,我看了一些网上的源码,发现他们对异常的处理不是很重视,研究了很久都没有找到很好的解决方案。后来有幸看到一个200W美元的项目部分源码,通过他们对异常处理的解决方案,我终
记录整理-工作问题
braveCS
工作
1)那位同学还是CSV文件默认Excel打开看不到全部结果。以为是没写进去。同学甲说文件应该不分大小。后来log一下原来是有写进去。只是Excel有行数限制。那位同学进步好快啊。
2)今天同学说写文件的时候提示jvm的内存溢出。我马上反应说那就改一下jvm的内存大小。同学说改用分批处理了。果然想问题还是有局限性。改jvm内存大小只能暂时地解决问题,以后要是写更大的文件还是得改内存。想问题要长远啊
org.apache.tools.zip实现文件的压缩和解压,支持中文
bylijinnan
apache
刚开始用java.util.Zip,发现不支持中文(网上有修改的方法,但比较麻烦)
后改用org.apache.tools.zip
org.apache.tools.zip的使用网上有更简单的例子
下面的程序根据实际需求,实现了压缩指定目录下指定文件的方法
import java.io.BufferedReader;
import java.io.BufferedWrit
读书笔记-4
chengxuyuancsdn
读书笔记
1、JSTL 核心标签库标签
2、避免SQL注入
3、字符串逆转方法
4、字符串比较compareTo
5、字符串替换replace
6、分拆字符串
1、JSTL 核心标签库标签共有13个,
学习资料:http://www.cnblogs.com/lihuiyy/archive/2012/02/24/2366806.html
功能上分为4类:
(1)表达式控制标签:out
[物理与电子]半导体教材的一个小问题
comsci
问题
各种模拟电子和数字电子教材中都有这个词汇-空穴
书中对这个词汇的解释是; 当电子脱离共价键的束缚成为自由电子之后,共价键中就留下一个空位,这个空位叫做空穴
我现在回过头翻大学时候的教材,觉得这个
Flashback Database --闪回数据库
daizj
oracle闪回数据库
Flashback 技术是以Undo segment中的内容为基础的, 因此受限于UNDO_RETENTON参数。要使用flashback 的特性,必须启用自动撤销管理表空间。
在Oracle 10g中, Flash back家族分为以下成员: Flashback Database, Flashback Drop,Flashback Query(分Flashback Query,Flashbac
简单排序:插入排序
dieslrae
插入排序
public void insertSort(int[] array){
int temp;
for(int i=1;i<array.length;i++){
temp = array[i];
for(int k=i-1;k>=0;k--)
C语言学习六指针小示例、一维数组名含义,定义一个函数输出数组的内容
dcj3sjt126com
c
# include <stdio.h>
int main(void)
{
int * p; //等价于 int *p 也等价于 int* p;
int i = 5;
char ch = 'A';
//p = 5; //error
//p = &ch; //error
//p = ch; //error
p = &i; //
centos下php redis扩展的安装配置3种方法
dcj3sjt126com
redis
方法一
1.下载php redis扩展包 代码如下 复制代码
#wget http://redis.googlecode.com/files/redis-2.4.4.tar.gz
2 tar -zxvf 解压压缩包,cd /扩展包 (进入扩展包然后 运行phpize 一下是我环境中phpize的目录,/usr/local/php/bin/phpize (一定要
线程池(Executors)
shuizhaosi888
线程池
在java类库中,任务执行的主要抽象不是Thread,而是Executor,将任务的提交过程和执行过程解耦
public interface Executor {
void execute(Runnable command);
}
public class RunMain implements Executor{
@Override
pub
openstack 快速安装笔记
haoningabc
openstack
前提是要配置好yum源
版本icehouse,操作系统redhat6.5
最简化安装,不要cinder和swift
三个节点
172 control节点keystone glance horizon
173 compute节点nova
173 network节点neutron
control
/etc/sysctl.conf
net.ipv4.ip_forward =
从c面向对象的实现理解c++的对象(二)
jimmee
C++面向对象虚函数
1. 类就可以看作一个struct,类的方法,可以理解为通过函数指针的方式实现的,类对象分配内存时,只分配成员变量的,函数指针并不需要分配额外的内存保存地址。
2. c++中类的构造函数,就是进行内存分配(malloc),调用构造函数
3. c++中类的析构函数,就时回收内存(free)
4. c++是基于栈和全局数据分配内存的,如果是一个方法内创建的对象,就直接在栈上分配内存了。
专门在
如何让那个一个div可以拖动
lingfeng520240
html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml
第10章 高级事件(中)
onestopweb
事件
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
计算两个经纬度之间的距离
roadrunners
计算纬度LBS经度距离
要解决这个问题的时候,到网上查了很多方案,最后计算出来的都与百度计算出来的有出入。下面这个公式计算出来的距离和百度计算出来的距离是一致的。
/**
*
* @param longitudeA
* 经度A点
* @param latitudeA
* 纬度A点
* @param longitudeB
*
最具争议的10个Java话题
tomcat_oracle
java
1、Java8已经到来。什么!? Java8 支持lambda。哇哦,RIP Scala! 随着Java8 的发布,出现很多关于新发布的Java8是否有潜力干掉Scala的争论,最终的结论是远远没有那么简单。Java8可能已经在Scala的lambda的包围中突围,但Java并非是函数式编程王位的真正觊觎者。
2、Java 9 即将到来
Oracle早在8月份就发布
zoj 3826 Hierarchical Notation(模拟)
阿尔萨斯
rar
题目链接:zoj 3826 Hierarchical Notation
题目大意:给定一些结构体,结构体有value值和key值,Q次询问,输出每个key值对应的value值。
解题思路:思路很简单,写个类词法的递归函数,每次将key值映射成一个hash值,用map映射每个key的value起始终止位置,预处理完了查询就很简单了。 这题是最后10分钟出的,因为没有考虑value为{}的情