asymmetric loss for multi-label classification
[论文笔记] Asymmetric Loss For Multi-Label Classification - 知乎在多标签图像识别问题中,由于标签空间往往很大,再加上正类样本的稀疏性,这使得多标签图像中存在严重的正负样本不均衡。ASL 便是从损失函数的角度出发,尝试解决该问题。在多标签图像识别问题中,我们常用的损失… https://zhuanlan.zhihu.com/p/425770937GitHub - Alibaba-MIIL/ASL: Official Pytorch Implementation of: "Asymmetric Loss For Multi-Label Classification"(ICCV, 2021) paperOfficial Pytorch Implementation of: "Asymmetric Loss For Multi-Label Classification"(ICCV, 2021) paper - GitHub - Alibaba-MIIL/ASL: Official Pytorch Implementation of: "Asymmetric Loss For Multi-Label Classification"(ICCV, 2021) paper
https://zhuanlan.zhihu.com/p/425770937GitHub - Alibaba-MIIL/ASL: Official Pytorch Implementation of: "Asymmetric Loss For Multi-Label Classification"(ICCV, 2021) paperOfficial Pytorch Implementation of: "Asymmetric Loss For Multi-Label Classification"(ICCV, 2021) paper - GitHub - Alibaba-MIIL/ASL: Official Pytorch Implementation of: "Asymmetric Loss For Multi-Label Classification"(ICCV, 2021) paper https://github.com/Alibaba-MIIL/ASLMS-COCO Benchmark (Multi-Label Classification) | Papers With CodeThe current state-of-the-art on MS-COCO is ML-Decoder(TResNet-XL, resolution 640). See a full comparison of 19 papers with code.
https://github.com/Alibaba-MIIL/ASLMS-COCO Benchmark (Multi-Label Classification) | Papers With CodeThe current state-of-the-art on MS-COCO is ML-Decoder(TResNet-XL, resolution 640). See a full comparison of 19 papers with code. https://paperswithcode.com/sota/multi-label-classification-on-ms-coco
https://paperswithcode.com/sota/multi-label-classification-on-ms-coco
TResNet学习笔记 --- TResNet: High Performance GPU-Dedicated Architecture_梦坠凡尘-CSDN博客代码:https://github.com/mrT23/TResNet论文:https://arxiv.org/abs/2003.13630阿里达摩院上个月推出的推出的高性能GPU专用模型,比以前的ConvNets具有更高的准确性和效率,性能优于EfficientNet、MixNet等网络。...https://blog.csdn.net/c2250645962/article/details/105565535/多分类的交叉熵和二分类的交叉熵有什么联系? - 知乎卧槽,突然发现之前回答的是多标签分类和多类分类的区别,今天忽然晃过神来,我们常说的logistic regress…https://www.zhihu.com/question/341500352/answer/795497527 多标签中把每一个类别都当成二分类来看sigmoid ce,其实正负样本不均衡现象是非常严重的而且是天然的,在多分类中用softmax ce就还好,取决于数据分布,本文写的非常好,目前在多标签分类任务上在paperwithcode上也是第一,在coco上map刷到了86.6%,论文主要是两点,第一,改进了focal loss的gamma,第二应用probability margin,是标准的focal loss改进文章在多标签分类中的应用,理论实验都和很完整,非常值得细读。正负样本不均衡,难易样本学习在多标签中也是突出的问题,很建议大家关注多标签任务,其实和目标检测的核心点正负(难易)样本分配是很有契合度的。
1.Introduction
A key characteristic ofmulti-label classification is the inherent positive-negative imbalance created when the overall number of labels is large. 多标签分类的一个关键特征是当标签总数很大时会产生固有的正负不平衡。 大多数图像只包含一小部分可能的标签,这意味着每个类别的正样本数量平均将远低于负样本数量。resampling方法也不适用于多标签分类,每个图像包含许多标签,重采样不能仅改变特定标签的分布,因为对图层级的重采样肯定会影响多个标签,每个图也不止一个标签。
在多标签分类中,focal loss应用也不多,focal loss能够降低简单负样本的权重,但它也有一个副作用,它也会降低部分loss较大的正样本的权重,文中称,it results in the accumulation of more loss gradients from negative samples, and down-weighting of important contributions from the rare positive samples.它导致负样本更多的损失梯度累计,降低了来自稀有正样本重要贡献的权重。换句话说,网络可能专注于学习负样本的特征,而忽视正样本特征的学习。这和多标签的特性有关,天然的正负不均衡,负样本中也有难例也有简单样本,会造成对loss大的样本的过滤更大程度上波及了所有的正样本。我们知道focal loss中重要的是alpha和gamma两个超参,alpha控制样本不均衡,gamma控制难易样本的学习,一般alpha=0.25,gamma为2,focal loss中调参一般调alpha。alpha是给数量少的类别增大权重,给数量多的类别减少权重。focal loss应用的时候有个巧合,负样本往往是easy的,所以他是希望对easy negatives做限制,让其loss更小,梯度更小。
引入了asymmetric loss,1.保持positive samples贡献的同时关注hard negatives,we decouple themodulations of the positive and negative samples and assign them different exponential decay factors.将positive和negative样本的调制解耦,并为它们分配不同的指数衰减因子,即正负样本使用不同的gamma。2.we propose to shift the probabilities of negative samples to completely discard very easy negatives (hard thresholding). 通过改变负样本的概率下限(margin)来丢弃掉very easy negatives.

作者给了上面的示意图,a,2个正样本,78个负样本,还有一个错误样本(多标签中样本误标是很正常,创意类的项目存在大量的样本误标),b,作者提议的asl loss的p-gradient曲线,明确一点,简单样本的p越大,loss就越小(loss是简单样本的pred和gt之间差值),不过loss和梯度之间并没有明确的关系(梯度只和损失变化的趋势有关),但梯度越大,说明反传信息越大。这个曲线后面会解释。
2.Asymmetric loss
2.1 binary cross-entropy and focal loss
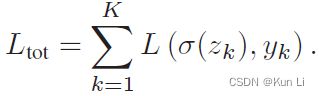
L是total classification loss,L中第一个是经过sigmoid激活的网络输出的logits的值,第二个是gt。
![]()
每个标签的binary loss形式如上,
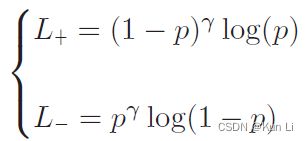
p是网络输出的概率值,gamma是focusing parameter,gamma=0就是binary cross-entropy(二元交叉熵)。通过设置gamma>0,easy negitives的(低概率,p远小于0.5,p是正样本的概率,正样本的p很小,负样本p很大)贡献可以在损失函数降低权重,保证在训练阶段更多关注harder samples。

这里要简单说明一下sigmoid和softmax区别,在多标签分类,负样本也会计算loss的,softmax整体考虑标签时,如果是负样本就是0了,但是多标签中,负样本是会单独计算loss的。
2.2 Asymmetric focusing
在多标签中用focal loss时有一个内在的权重:设置一个高的gamma,以充分降低来自easy negatives的贡献,但可能会消除rare positive samples中的梯度。因此将正负样本的focusing level进行解耦,设置gamma+,gamma-分别关注positive,negative参数。我们用asymmetric focusing 重新定义loss:
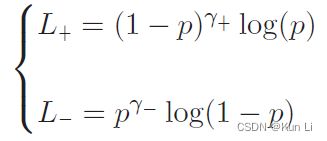
由于我们对强调positive samples的贡献更感兴趣,通常设置gamma->gamma+。
It should be noted that methods which address class imbalance via static weighting factors were proposed in previous works.说的是focal loss设置alpha=0.25来筛选正负样本不均衡问题,作者后续会解释简单线性加权不足以解决正负样本不均衡问题,通常在多标签分类中也不加alpha,因为每个类别都需要设置一个alpha是很麻烦的。
2.3 Asymmetric probability shifting
当negative samples的概率很低时(easy),asymmetric focusing 会减少负样本对损失的权重。Since the level of imbalancing in multi-label classification can be very high, this attenuation is not always sufficient. Hence, we propose an additional asymmetric mechanism, probability shifting, that performs hard thresholding of very easy negative samples, it fully discards negative samples when their probability is very low.由于多标签分类中的不平衡程度可能非常高,因此这种衰减并不总是足够的。 因此,我们提出了一种额外的非对称机制,probability shifting,它对非常容易的负样本进行hard thresholding处理,即,当负样本的概率非常低时,它会完全丢弃负样本。
![]()
m是probability margin,是一个可调的超参,把它应用到L-上,即,
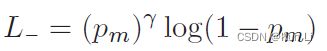
下图绘制了probability-shift focal loss(负样本)
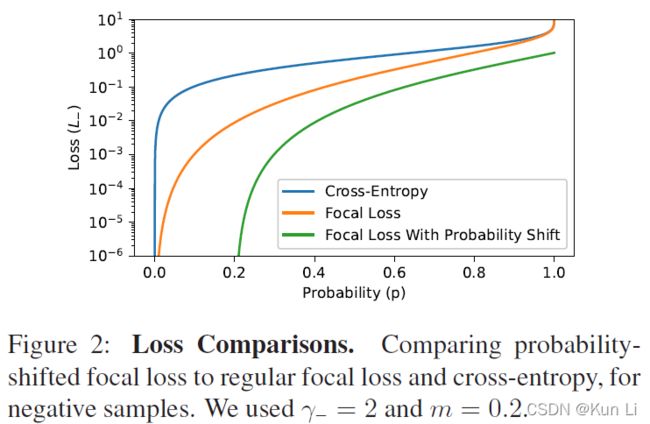
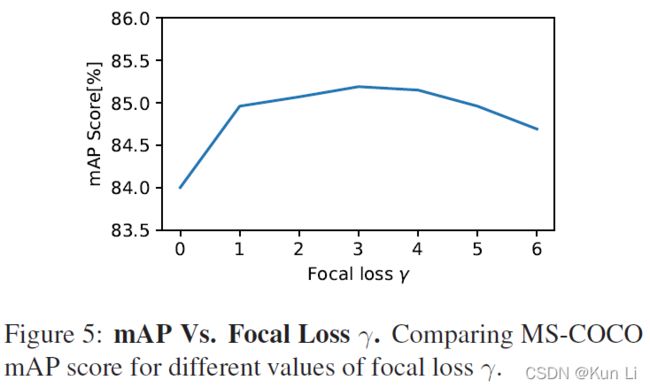
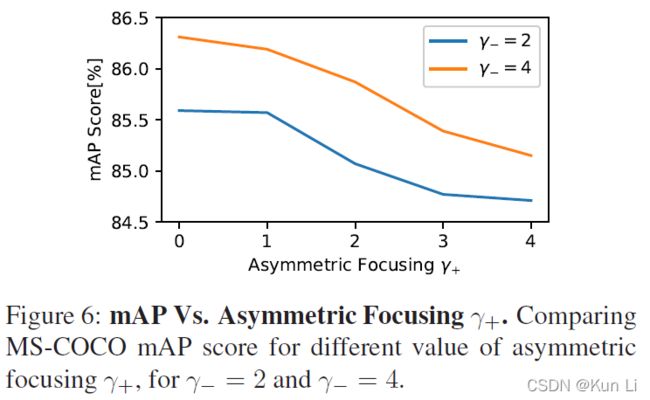
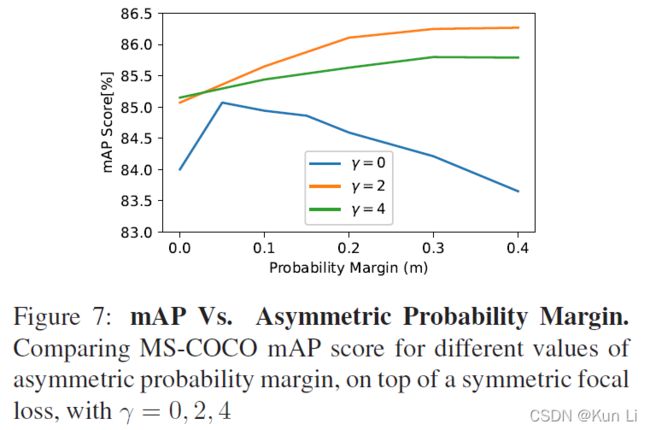
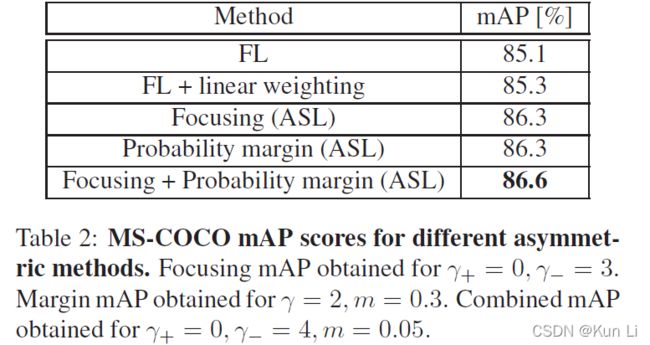
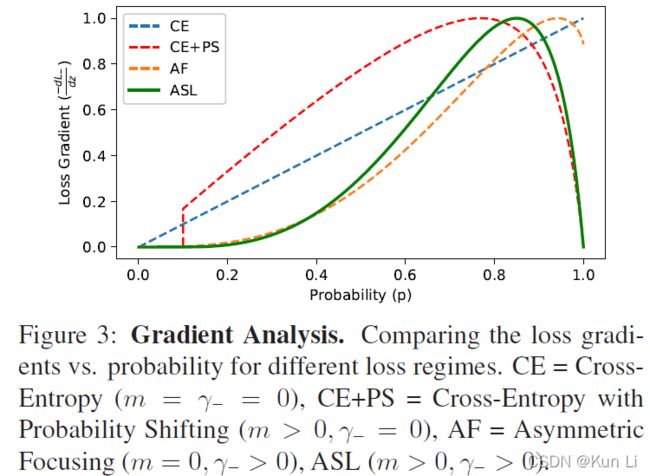
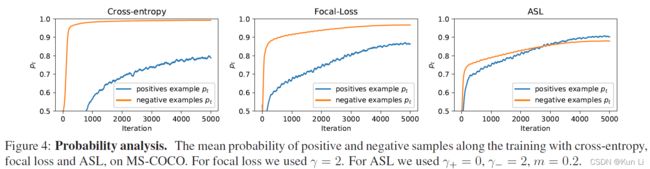
在几何角度看,有了probability-shift的就是损失函数向右移动了一个margin从而在p 2.4 ASL definition 至此有了正负样本不同的gamma以及probability shift的ASL就成立了。 2.5 Gradient analysis the network weights are updated according to the gradient of the loss,with respect to the input logit z.网络权重根据loss的梯度进行更新,相当于输入logit, p是sigmoid的结果,z包括在sigmoid中。上面这个式子是负样本的损失对p求导公式,即梯度,p这里是正样本的概率值,p越大,负样本概率越小。下图要注意纵坐标是梯度,横坐标是正样本的p,和focal loss那张图有区别,focal loss那张图纵坐标是loss。 1.hard threshold.看上图,very easy negatives的样本在p一开始的时候p 2.soft threshold.negative samples,p>m,在他们概率很低时应该衰减,负样本的概率较高时,要让gamma起作用,不要让这些高p占据过多的梯度。 3.mislabeled.very hard negative samples,p>p*,p*是上图中曲线顶点,p很高时,负样本有可能是被误标的,它本身可能就是个正样本,It has been shown by that multi-label datasets are prone to mislabeling of negative samples, probably because the manual labeling task is difficult. 手动表多标签是很容易出错的。 2.6 probability analysis 在多标签分类任务中,用ce和fl去学positive样本的特征是次优的。我们通过监控网络在训练时输出的平均概率来说明。这使我们能够评估网络对正样本和负样本的置信水平,低置信度表明未正确学习到特征(置信度即为sigmoid输出的p值),定义pt: p平均是指在一个iteration(一次iteration就是一次batch)中所有样本的平均概率。pt+,pt-分别表示正负样本的的平均概率。则概率差可表示为: A balanced training should demonstrate similar level of mean confidence for positive and negative samples.均衡训练应该对正负样本表现出相似的平均置信度水平,即在训练结束时,概率差很小。 如上图,在ce和fl中概率差为-0.23和-0.1,This implies that the optimization process gave too much weight to negative samples. 这说明优化过程中对负样本赋予了过多的权重,asl则说明网络有能力强调正样本。说明一下,平均置信度的水平表示了网络在所有预测中sigmoid的输出对正负样本的均值,可能对正样本的均值在0.85,对负样本的均值在0.90,p是logit经过sigmoid的值,进入损失的输入,它也是网络输出的特征的表示,是BP不断优化的结果,如果负样本的平均p一直高于正样本的平均p,则说明网络依然没能很好的关注正样本,因为在多标签中正负样本不均衡是天性。 2.7 Adaptive asymmetric 这块也是一个自然而然的优化,focal loss中其实也讨论了关于alpha和gamma的动态调整,通常alpha表征的是正样样本的比例关系,类似resample的方法,只不过是加在了loss上。作者在上图中证明了asl能够平衡网络,但是为了防止概率差小于0的情况出现,希望动态调整gamma-,在每个batch中去调整gamma-。 lambda是步长,通过增加ptarget,上市使我们能够在整个训练过程中动态增加不对称水平,迫使优化过程更多地关注正样本的梯度。不过动态的gamma-其实在数据上并没有静态的gamma-效果好,低了0.2%,不过好在可以放心收敛,不必调整超参。 3.experiment result gamma=0,即为ce,map为84%,gamma在2,4之间,focal loss的最高map=85.1. asl中,gamma+=0是效果最好,gamma-=4时效果好。此处需要考虑,因为gamma>0其实对存在大量简单正样本的情况是有用的。 本文整体上看还是很好的文章有分析有实验,对fl进行改造,主要就是分别对正负样本的gamma,控制样本难易程度的,其次是增加了probability margin值,作者后续通过梯度分析和概率分析来解释了这么做的优异性。在梯度分析上分了三段,对简单样本的丢弃,负样本的梯度指数衰减以及可能对误标样本有挖掘。在概率分析中,通过对平均正样本的p和平均负样本的p的概率差计算,说明网络有能力强调正样本,这比fl中使用alpha来的快的多。 建议大家对于每个领域问题时,一定先去paperwithcode上关注一下指标,我几天前去image classification看了一下inagenet的top1精度指标居然都有90.88%了,还是深受震撼的,其实imagenet数据集还是挺难的。asl在paperwithcode上coco上的map为86.6%。
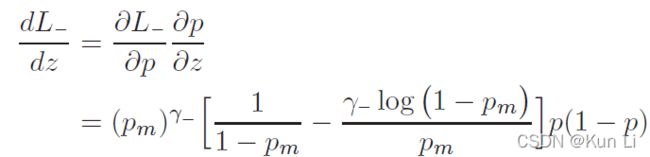
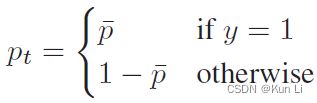
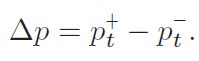
![]()