论文研读:A new approach to compute deficiency number of Mahjong configurations

摘要:麻将是一种中国传统的以牌为基础的游戏,有着悠久的历史,现在世界上许多国家都在玩麻将。关于麻将话题的一个重要问题是,玩家最少需要改变多少张牌才能获胜,即所谓的缺牌数,这在麻将游戏的AI开发中起到了非常重要的作用。然而,由于大量可能的牌组组合,缺牌数无法轻易计算出来。在这项工作中,我们提出了一种高效的算法方法,在编程语言Python的帮助下,计算玩家手中的牌的不足数。为了评估该方法的性能,我们针对各种缺陷数建立了超过120万个测试用例。最后,实验结果表明了我们方法的有效性。

麻将牌是根据如图1所示的汉字和符号进行设计的,牌信息构成了这款游戏最常见、最基本的版本。麻将涉及的牌共有144张,分别是竹节牌36张、字型牌36张、点型牌36张,以及荣誉牌(如风箭牌)、奖金牌(如季节、花卉牌)等36个特定符号。对于每一个条,万和饼类型,有九个类型,也就是说,从1到9,每个牌有四个副本。由于一些地域差异,麻将中规则的变化不同。但最基本、最常见的麻将规则,即“Mahjong-0”,已经为其所有变体铺平了道路。对于麻将0的版本,我们只考虑了类型竹、字、点的牌。
李和严将14张牌分成5个子序列,进行4次meld外加一对,并结合各种为这些meld和对使用
四叉树。很容易看出,可能有太多的分支可能的meld和对的组合。注意,实验论文[4]中没有数据。
这里我们只考虑基本版本麻将0,总共有108块,包括36块竹型,36块字符类型,36块点类型。因此,麻将-0中瓷砖的内容可以表示如下:

定理3.1
eye(将/对)是一对相同牌,也就是说,eye是X∈{B,C,D}的XiXi和1⩽i⩽9;pong(碰)是三个相同的牌序列,也就是说,pong的形式是XiXiXi,X∈,B,C,D}和1⩽i⩽9;kong(杠)是四个相同类型的牌的序列,chi(吃)是三个相同类型牌的连续序列(搭子),是XiXi+1Xi+2为X∈{B,C,D}和1⩽i⩽7;统称为meld (鸣牌)。
定理3.2
对于类型X∈{B,C,D},一对XiXj如果1⩽|j−i|≤2,则一对XiXj称为pseudochow(伪搭子),也就是说,差一张成为吃或者碰;pseudomeld 是pseudochow或eye;如果牌不属于任何meld and pseudomeld,则称为孤张;如果它们属于某一meld or pseudomeld,牌Xi与牌Xj相关,否则则是不相关的。
例如,B1B2B3是吃,B4B4B4是碰,C2C2C2C2是杠,C5C5是将,D7D8是伪搭子,其中B1B2B3和B4B4B4是meld,C5C5和D7D8是伪搭子。
定理3.3
一组14张牌被称为配置(手牌?),如果它是Bi1Bi2…BimCj1Cj2…CjnDk1Dk2…其中0⩽i1⩽i2⩽...⩽≤9,0⩽j1⩽j2⩽...⩽≤9,≤9,0⩽k1⩽k2⩽...⩽≤9,0⩽i1⩽i2⩽...⩽++=14,X0=∊,∈{B,D,C;一个将和四个搭子组成,眼睛和融合被称为和牌手牌T。例如,14张牌T1=B1B1B2B3B4C1C2C3D5D5D5D7D8D9是一个和牌牌型,其中B1B1是T1的将,B2B3B4,C1C2C3,D5D5D5和D7D8D9是T1的搭子。
定理3.4
如果所有的牌都是相同类型,则配置称为纯策略;否则,称为混合策略。如果在此配置中有两种不同类型的牌,则配置称为2-混合。类似地,也有3-混合。
定理3.5
对于配置T,使T获胜所需的平铺更改的最小数目称为T的缺牌数,它用dfncy(T)表示。显然,对于一个获胜的配置T,它持有dfncy(T)=0。例如,14层的T3=B1B1B2B3B5C1C1C1D5D5D5D7D8D9不是一个获胜的配置,其缺牌数为1,即dfncy(T3)=1。很容易看出,从T3中,通过替换B5,可以获得一个获胜的配置。同样,配置T4=B1B1B2B3B9C1C1C3D5D5D5D6D8D9的缺牌数是3,即dfncy(T4)=3,其中B9是孤张。在[4]中,纯构型的缺牌数不大于3,而混合构型的缺牌数小于或等于6。我们继续对配置中孤张和相关牌的一些数学结果。
定理3.6
在纯配置中,最多有两个孤张。证据设T为纯配置,由14个X型瓷砖组成∈ {B,C,D}。
证明:假设配置T包含三个孤张。这意味着在配置T中,Xi、Xj和Xk不属于任何meld or pseudomeld。此外,这些孤张也必须彼此无关。因此,j−i≥ 3和k−j≥ 3,必须同时保持。因此,我们得到1⩽i≤ 3, 4⩽j≤ 6和7⩽k≤ 9.回想一下,每个配置由14张牌组成,因此在配置T中有11张牌不是孤立的。假设Xr是配置T中的非孤张。对于图块Xr的索引r,我们必须区分某些情况。如果1⩽r≤ 3.那么,Xr与Xi有关;如果4⩽r≤ 6,则与Xj有关;如果7⩽r≤ 9,那么它与Xk有关。我们已经看到,Xr始终与至少一个孤张相关,这与我们的假设相矛盾。
实际上,很明显,对于每种类型X∈ {B,C,D},只有三种纯配置包含两个独立的分片:
(1)x1x4x7x7x7x7x9x9x9;
(2) X1X4X4X4X4X5X5X5X6X6X9;
(3) X1X1X1X1X2X2X2X3X3X6X9。
因此,总共有九种纯配置包含两个独立的瓦片。
定理3.7
在2类混合配置中,最多有5张孤张。
证明。设T是一个2-混合的配置。我们假设配置T包含6个孤张,因此这些牌彼此不相关。根据定理3.6的论证,对于相同的类型,最多有三张牌Xi,Xj和Xk相互无关,其中1⩽i≤3,4⩽i≤6和7⩽k≤9,因此两个类型最多6个瓷砖。由此可见,在配置T中至少有8个非孤张。与定理3.6的证明类似,我们可以很容易地证明每个非孤张将至少与一个孤张相关,这与我们的假设相矛盾。
它仍然需要找到一个包含5个孤张的2-混合配置。对于某些类型的X、Y∈{B、C、D}和X∕=Y,在配置X1X4X7X8X8X8X8X9X9X9X9Y1Y4Y7,中有五个孤张,分别是X1、X4、Y1、Y4和Y7。事实上,通过简单的蛮力搜索,很容易得到540种2混合配置,包含5个孤张。以类似的方式,可以建立以下结果。
定理3.8
在一个3类混合配置中,最多有8张孤张。
定理3.9
在麻将-0中,一张牌最多可以与19张牌有关。
证明。上述陈述可以通过蛮力搜索来证明。对于X∈{B,C,D}和1⩽i,j≤9,如果|j−i|>2,Xi与Xj无关。因此,Xi与Xi−2、Xi−1、Xi+1、Xi+2以及自身的其他副本相关。此外,Xi−2、Xi−1、Xi+1和Xi+1共有16份,Xi本身仍有3份,这完成了我们的证明。通过上面的声明,我们得到,在一个配置中,一张牌可以与任何其他牌相关联。例如,在配置X3X3X3X3X4X4X4X4X5X5X5X5X6X6,中任何一张X4或X5都与所有其他牌相关。
为了将配置T转换成获胜的配置T’,我们需要构建T’的其余组件。很容易看出,meld可以由一个伪meld和一个孤张或三个孤张构成的,而将可以由一个伪meld或两张孤张拼凑而成。因此,可以基于伪meld和孤立的数量来计算不足。为此,我们需要以下概念
定义4.1
对于麻将配置T,T的(完全)分组由三元组(M,P,I)定义,其中M是一组麻将牌,P是一组伪meld 麻将牌,I是孤张集合,I中的所有麻将牌彼此不相关,并且集合M、P和I中的所有麻将牌可以构成配置T。
配置T的分组(M,P,I)意味着T中的牌被分成集合M,P和I,并且T的每张牌可以恰好被放入一个集合中。很容易看出,对于一个配置,可能有一个以上的分组,对于一个配置T,我们使用G(T)来表示T的所有可能的分组的集合。此外,对于每个分组g = (M,P,I) ∈ G(T),我们可以通过使用P中的伪meld和I中的孤张来构造获胜手牌, 并且令MTC(g)是P和I中改变的瓦片的最小数量。这意味着g ∈ G(T)的所有MTC(g)中的最小值实际上是配置T的缺牌数,即,
dfncy(T) = min{MTC(g)|g ∈ G(T)}。
由于计算成本受集合G(T)中分组数量的影响,因此将避免重复和相似等不必要的分组,并且通过这种简化获得的分组集合由Gs(T)表示。因此,给定一个麻将配置测试,我们的方法包括如下两个阶段。
(1)对T进行分组,得到分组集合Gs(T);
(2)计算min{MTC(g)|g ∈ Gs(T)}的值。
显然,对于任何分组,原始配置中的每个孤张必须在集合I中。例如,在配置T5 = B1 B2 B3 B4 B9 C5 C5 C5 C5 D1 D1 D6 D6 D7中,只有一个孤张B9,而在T5的分组({B1B2B3,C5 C5 C5 C5 }、{D1D1,D6}、{B4,B9,C5,D7})中,B4、B9、C5和D7被纳入集合 并且在另一个分组({B2B3B4}、{ C5C5 C5、C5 C5、D1D1、D6D7}、{B1、B9、D6})中,集合I包含瓦片B1、B9和D6。 我们已经看到,在两个分组中,孤张B9总是在集合I中。对于集合M、P和I的最大尺寸,我们具有以下结果。
定理4.2
对于一个分组(M,P,I),它认为|M| ≤ 4,|P| ≤ 7,|I| ≤ 9。
证明。由于在一个配置中有14张牌,很容易看出每个配置包含最多四个meld和七个伪meld。还有待证明|I| ≤ 9。我们假设存在一个分组(M,P,I ),使得|I| = 10,也就是说,在分组(M,P,I)中有十个孤张。根据相对孤张的定义,集合I中的所有牌彼此不相关。进一步,根据定理3.6证明中的论点,对于每一个类型X ∈ {B,C,D},至多有三张牌是互不相关的。因此,集合I包含所有三种类型的牌,每种类型至少三张,即Bi1、Bi2、Bi3、Cj1、Cj2、Cj3、Dk1、Dk2和Dk3,其中1⩽i1,j1,k1 ≤ 3,4⩽i2,j2,k2 ≤ 6,7⩽i3,j3,k3 ≤ 9。由此可见,集合I中的第十张牌t与上述相对孤张中的至少一个相关,并且设x ∈ I是与t相关的。根据定义4.1,在将与t相关的所有牌取入包括x的集合M和P之后,牌t变为孤张,这与我们的假设相矛盾。很容易看出,只有在|M| = 1和|P| = 1的情况下,才会发生|I| = 9,例如,配置B1 B5 B5 B5 B5 B5 B6 B6 C4 C7 D2 D5 D8的分组({B6B6B6}、{B5B5}、{B1、B5、B9、C1、C4、C7、D2、D5、D8}),其中牌B5在原始配置中没有被隔离,并且在将假块B5B5和融合B6B6B6分别进入集合P和M后变得相对隔离。
为了构建一个获胜的配置,剩下的组件可以通过消耗P中的一对和i中的一张牌来构建。考虑到伪meld和孤张的数量,我们需要区分两种情况。对于一个分组g=(M,P,I),如果|P|>|I|,意味着伪meld比孤张更多,那么我们必须将多余的伪meld拆解;否则,我们必须使用集合I中的其余块来构建剩余的必要组件。现在我们介绍我们的方法,通过使用值|P|和|I|来计算分组g=(M,P,I)的值MTC(g)。要做到这一点,我们需要以下引理。对于一组S,设|S|表示S中的元素数。
引理4.3
设g = (M,P,I)是一个配置t的分组,如果|P| > |I|,则|P| - |I| - 1可被3整除。
证明。由于一个配置最多包含四个meld,我们考虑meld数量从0到4的情况。如果|M| = 0,这意味着在配置T中没有meld,那么所有14张牌将被分组到集合P和I中。如果|P| = 7且|I| = 0,则| P | - | I | - 1 = 6,可被3整除。现在,我们考虑|P| = 6和|I| = 2的情况,这意味着从集合P中取出一对到I中,导致|P|减少1,I增加2,因此| P | - | I | - 1的值减少3。以类似的方式,所有其他情况也可以处理。
定理4.4
设g = (M,P,I)是一个构形t的分组,如果|P| > |I|,且集合P包含一对,则
MTC(g)= | I |+(| P | - 1 - | I |)×2/3。
证明。我们需要更改牌数量由以下两部分组成。
(1)摸到一张有用的牌,集合P的伪meld数量减一,集合I的孤张减一,meld数量+1。因此,在消耗集合I中的牌的过程中,至少需要改变|I|张牌。
(2)由于|P| > |I|,我们需要使用集合P中的剩余对来构建获胜配置的剩余组件。首先要求从P中取一对作为将。此时,集合P中仍有| P | -1- | I |个伪meld,通过使用它们,我们构建了剩余的meld子分量。很容易看出,从| P | - 1 - | I | 中,可以构建(| P | - 1 - | I |)×2/3 个melds,在此过程中,至少需要更换(| P | -1 - | I |)×2/3张牌。
因此,将上述两部分相加,我们可以得到总数| I |+(| P | - 1 - | I |)×23。此外,根据引理4.3,在|P| > |I|的情况下,| P | - 1 - | I |总是能被3整除,这就完成了我们的证明。以类似的方式,也可以建立下面的结果。
定理4.5
设g = (M,p,I)是一个构形t的分组,如果|I|⩾|P|,且集合p包含一对,则MTC(g)= | p | - 1+(| I | - (| p | -1))×2/3。
最后,一个配置T的缺牌数可以通过确定min{MTC(g)|g ∈ Gs(g)}的值得到。
5. Algorithms
本节的目的是提出我们的算法来计算麻将构型的缺牌数。该算法由两个子算法组成。第一个用于获得给定配置T的集合∈(T),第二个用于计算所有集合∈(T)的值MTC(g),然后选择最小值作为T的缺牌数,这将在以下两个小节中介绍。
5.1 牌分组
一个不完整的分组配置T定义为四(T,M、P),其中T是T的子字符串表示剩余部分T分组,M是一组融合,P是一组伪,我是一组相对孤立的瓷砖描述定义4.1,和字符串T‘连同所有瓷砖的M,P和我可以构成配置T。
给定一个不完整的分组(T‘、M、P、I),如果T’为空,即(∊、M、P、I),则分组实际上是完成的,即配置T中的所有块都在集合M、P和I中移动,因此也可以写为(M、P、I),如定义4.1所示。显然,麻将配置T的初始不完全分组是(T,∅,∅,∅)。
算法1中列出的伪代码用于从给定的不完整分组中获得可能的(完整的)分组。对于平铺t,设Φ(t)表示t的索引。此外,对于瓷砖字符串T,|T|表示T中贴图的数量。最后,对于T的子串T‘,我们使用T⊖T’表示从T中删除T‘得到的T的剩余部分。
算法1:手牌分组


对于meld t1t2t3,它认为φ(T3)φ(t1)≤2。因此,在GROUP()函数中,我们首先考虑最左边的子串s = s1s2…sn,它包含满足φ(si)φ(S1)≤2的所有图块。对于1⩽i⩽n.的长度s,我们区分以下情况。
(1)如果|s| = 0,那么可以得出T是一个空字符串,即分组已经完成,因此算法返回三元组(M,P,I)的集合,这是一个完整的分组。
(2)如果|s| = 1,意味着s是一个孤立的瓦片,那么我们从瓦片串t中去掉s,把s加到集合I中,进一步,我们通过递归调用带有自变量(T ⊖ s,m,p,I ∨{ s })的GROUP()函数,继续对t的剩余部分进行分组。
(3)如果|s| = 2,即s = s1s2,意味着s是伪meld,那么我们调用参数为(T ⊖ s,m,p ∨{ s },I)的GROUP()函数,将s从瓦片串t中移除,并将s添加到伪meld的集合中。此外,如果φ(s2)-φ(s1)= 2,并且如果图块s2可以参与到具有后续图块的meld的构造中,则我们分解伪meld s1s2并将图块S1放入集合I中。请注意,图块s2仍在t的剩余部分中。然后,通过使用具有自变量(T ⊖ s1,m,p,I ∨{ S1 })的GROUP()函数,该算法尝试将图块S2与后续图块组合成meld。
(4)如果|s| = 3,即s = s1s2s3,那么我们要区分以下两种情况。
(4.1)如果s是meld,那么我们把s从字符串t中去掉,放入集合m中,进一步,我们通过调用带有自变量(T ⊖ s,m ∨{ s },p,I)的GROUP()函数继续对t的剩余部分进行分组。此外,如果s是一个pong,那么我们需要将其分解为一只眼睛s1s2和一个单幅图块s3,将s1s2添加到集合p中。
(4.2)如果|s| = 3,并且如果s不是一个meld,这意味着s包含一只眼睛s’,那么我们将眼睛s’添加到集合p中,并且通过调用带有参数(t⊖s’,m,p ∨{ s’},I)的GROUP()函数继续对t的剩余部分进行分组。此外,如果φ(s2)>φ(s1),意味着s2s3是眼睛,并且s1s2(和s1s3)是伪融合,则我们将S1和s2组合成伪融合,并且将瓦片s3保持在T的剩余部分中,因为瓦片S2(和s3)与后面的瓦片一起可以构成融合或伪融合。此外,我们还必须考虑φ(S2)φ(S1)= 2的情况,即s的形式为XiXi+2Xi+2。在这种情况下,我们需要尝试将Xi+2Xi+2对与后面的图块组合,并将图块s1放入集合I中。重要的是要注意,如果s1s2是一只眼睛,那么我们不分解s1s2以避免不必要的分组,因为图块t1(和t2)变得相对孤立。
(5)如果|s| ≥ 4,则该算法需要通过去除s中的melds和eyes来递归地减少s的长度,其执行类似于上述情况。如果|s| = 4,即s = s1s2s3s4,如果s2s3s4是pong,如果φ(S2)φ(S1)= 2,那么我们把伪meld s1s2取入集合p,把眼睛s3s4保持在t的剩余部分.但是,我们要考虑一种特殊情况,即|s| = 7 (s = s1s2…s7),φ(S1)∕=φ(S2)和s 4 S5 S6 7是kong,主要针对以下纯配置:
(a) X1X1X1X1X5X6X6X7X7X7X7X8X8X9,
(b) X2X2X2X2X5X6X6X7X7X7X7X8X8X9
上述配置的不足之处是1,对于它们来说,最佳例程是分别用X4替换图块X1和X2的副本。两种配置都有一个公共子串X5 x 6 x 7 x 7 x 7 x 7,为了获得最佳例程,必须将图块X5和X6组合成一个伪meld。相应地,我们使用参数(T ⊖ s1s2,m,p ∨{ S1 S2 },I)调用GROUP()函数。
现在我们通过实验中的一个测试用例来展示算法的过程。
5.2 设配置T = B2 B3 B4 B5 B5 B6 B7 B7 C8 D1 D2 D3 D9 D9。该算法从自变量(t,m,p,I)开始,其中M = P = I = ∅.首先,我们观察最左边的子串B2B3B4,它是一个meld,因此我们将其从T中移除并将其放入集合m中。然后,我们考虑T的剩余部分的最左边的子串B5 B5 B6 B7 B7。由于|B5 B5 B6 B7 B7| ≥ 4,我们需要区分两种情况:
(1)由于子串B5B5B6B7B7包含meld B5B6B7,我们将其放入集合m。然后,剩余部分B5B7是伪meld,因此我们将其放入集合p。
(2)子串B5B5B6B7B7中有两只眼睛,我们首先将眼睛B5B5放入集合p。对于剩余部分B6B7B7,我们再次区分两种情况。
(2.1) B7B7是一对,因此我们将其放入集合p中。显然,在这种情况下,B6为孤张,因此我们将其放入集合I中。
(2.2) B6B7是一个伪融合体,因此我们也可以将其放入集合p中。与情况(2.1)类似,当瓷砖B7变得相对孤立时,我们将其放入集合I中
剩余部分C8 D1 D2 D3 D9 D9可以类似地处理,我们将子串C8 D1 D2 D3和D9 D9分别放入集合I、M和P。因此,该算法为给定的配置T产生三个分组,并返回集合
G = {({B2B3B4, B5B6B7, D1D2D3}, {B5B7, D9D9}, {C8}),
({B2B3B4, D1D2D3}, {B5B5, B7B7, D9D9}, {B6, C8}),
({B2B3B4, D1D2D3}, {B5B5, B6B7, D9D9}, {B7, C8})}.
5.2.计算缺牌数
对于麻将配置T,我们可以通过执行上一小节中给出的GROUP()函数来获得T的分组集合G。然后,我们可以使用算法2中的CALCULATE_DEFICIENCY()函数计算T的亏量。现在我们为下面的算法引入一些概念。
定义5.3 设完备的分组(M,P,I),设一个伪meld t1t2 ∈ P .如果所有能用来与t1t2构造一个meld的瓦片都包含在集合M和P中,那么t1t2称为不完备的,即伪meld不能通过再加一个瓦片而与一个meld完备。
算法2:计算麻将手牌缺牌数


基于定理4.4和4.5设计计算不足(G)函数,并且通过考虑伪融合数和相对孤立的牌之间的关系来计算麻将配置的不足。因此,给定一个完整的分组(M,P,I),算法首先确定|P|和|I|的值。如果集合P中的一个伪meld是不完备的,那么它将被转移到集合I中,从而导致|P|和|I|的值发生相应的变化。此外,还需要为获胜配置制作一个眼睛组件。在CALCULATE DEFICIENCY()函数中,有四个布尔变量来确定获胜配置的眼图组件的选择。
(1)变量exist_incompletable_eye用于指示是否存在不可完成的眼睛。很明显,通过使用不完整的眼睛来构建一个meld,两个瓦片都需要被改变。因此,如果集合P中存在不可完成的眼睛,即exist_incompletable_eye = true,则眼睛组件的最优选择是不可完成的眼睛之一。注意,不可完成眼中的两个瓦片将作为两个相对孤立的瓦片放入集合I中。
(2)变量exist_eye的值暗示集合p中是否存在一只眼睛,如果exist_incompletable_eye = false,如果exist_eye = true,那么我们可以选择一只已存在的眼睛而不改变任何瓷砖。如果exist_eye = false,那么我们考虑以下两种情况。
(2.1)如果|P| > |I|,则该算法试图通过改变一个假像的一部分来将其转换成一只眼睛。因此,我们建立了变量pchow_to_eye,以便指示是否存在可以在一个瓦片改变内转换成眼睛的伪显示。如果pchow_to_eye = true,则平铺变化次数增加1;否则,减2。
(2.2)如果是|P|⩽|I|,那么我们用变量iso_to_eye来表示是否存在两个相对孤立的瓦片,可以通过改变其中一个来构造眼睛。如果iso_to_eye = true,则图块更改次数增加1;否则,减2。
现在我们根据例5.2中给出的配置T给出一个例子。
例5.4。对于示例5.2中给出的配置T = B2B3B4B5B5B6B7B7C8D1D2D3D9D9的完整分组(M,P,I),dfncy(T)的值可以计算如下。
(1)对于分组g1 = (M,P,I),其中M = {B2B3B4,B5B6B7,D1D2D3},P = {B5B7,D9D9},I = {C8},则|M| = 3,|P| = 2,|I| = 1。根据上述算法,集合P中至少有一只眼睛,因此exist_eye = true。此外,作为|i|⩽|p| 1,可以得到

(2)对于分组g2 = (M,P,I),其中M = {B2B3B4,D1D2D3},P = {B5B5,B7B7,D9D9},I = {B6,C8},则|M| = 2,|P| = 3,|I| = 2。根据上述算法,可以得出
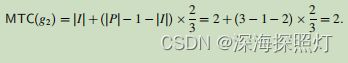
(3)对于分组g3 = (M,P,I),其中M = {B2B3B4,D1D2D3},P = { b5 b5 b5,B6B7,D9D9}并且I = {B7,C8},由此得出|M| = 2,|P| = 3,并且|I| = 2,因此我们可以类似于情况(2)立即获得MTC(g3) = 2。
最后我们可以确定缺牌数dfn cy(T)= min { MTC(g)| g∈Gs } = min { 1,2,2} = 1。
因此,分组({B2 B3 B4,B5 B6 B7,D1 D2 D3},{B5 B7,D9 D9},{C8})是最佳的,并且我们只需要用瓦片B6替换孤立的瓦片C8来获得获胜的配置。
6.实验设计
为了评估我们算法的性能,我们建立了超过120万个具有各种缺陷的测试用例,包括纯配置和混合配置。表1中给出了针对实验中各种缺陷的测试用例的数量。性能评估是在运行八核苹果M1处理器和8 GB内存的苹果MacBook Pro上进行的。该算法由3.8版本的编程语言Python实现,并用Python3编译。在接下来的两个小节中,我们将分别介绍纯配置和混合配置的实验设计。

6.1.纯配置的实验
每种类型总共有118800多种纯构型,通过强力搜索很容易得到。如上所述,纯配置的不足最多为3。事实上,亏量从0到3的纯构型的数目在[4]中给出。因此,在我们的实验中,我们通过强力搜索建立了竹子类型的所有纯构型。算法3中列出的伪代码通常用于生成所有纯配置(例如,参见[17])。
算法3:生成所有纯配置

6.2.混合配置的实验
混合配置的测试用例是使用随机库中的randint()函数生成的。我们为没有重复的混合配置建立了超过110万个测试用例,针对各种缺陷的测试用例数量在表1中给出。在这些测试案例中,每个配置包含至少两种类型的图块。
7.实验结果
在我们的实验中,运行时间是通过使用timeit库中的timeit()函数来测量的。为了减少随机误差,算法在每个测试用例上重复执行10次,我们选择平均值作为运行时间(毫秒)。我们研究性能指标的许多方面,如平均值、最小值、最大值、中间值和标准偏差。表2给出了纯配置和混合配置的运行时结果,总结了包括纯配置和混合配置在内的所有测试案例的运行时结果。我们可以看到,每个测试用例可以在不到五十分之一秒的时间内解决,平均运行时间只有0.299毫秒。

8.性能分析
在实验中,我们实现的算法可以以100%的准确率计算所有纯配置的不足。由于混合配置是两个或三个纯配置的组合,混合配置的不足也可以通过我们的算法正确计算。很明显,运行时间本质上受麻将配置分组数量的影响,这是由算法1中所示的GROUP()函数产生的。因此,我们计算了表3中列出的所有测试用例的分组数量。我们可以看到,除了缺陷1的混合配置的测试用例之外,缺陷的值基本上与运行时间和分组数成反比。相比较而言,计算纯配置的不足导致比混合配置更高的计算成本,因为在纯配置中通常有更少的孤立瓦片和更多的彼此相关的瓦片。

显然,瓦片分组的算法在树结构上进行,并且每个叶节点对应于一个完整的分组。请注意,在分组过程中已经避免了不必要的分支扩展。因此,所有测试用例的平均分支,即分组数,只有7.784。虽然纯配置的分组数平均值达到20.635,但在所有测试用例中只占很小的比例。分组数的分布见表4。我们看到分组数从1到20的纯构型有58.112%,分组数从1到10的混合构型高达83.686%。总体来看,76.605%的测试用例可以在分组数10以内解决。

考虑到我们实验中的纯配置,超过60个分组的测试用例只有123个,仅占0.104%,而对于混合配置,所有测试用例都可以在60个分组内求解。特别是以下三种纯配置的分组数都在70以上:
(1) B1 B3 B4 B4 B5 B5 B5 B6 B6 B6 B7 B7 B8 B8,
(2) B1 B3 B4 B4 B5 B6 B6 B7 B7 B7 B8 B8 B9 B9,
(3) B2 B4 B5 B5 B6 B6 B6 B7 B7 B7 B8 B8 B9 B9.
上述所有配置的不足为1,它们被处理为72个分组。我们看到这些配置中没有孤立的瓦片,所有的瓦片都是直接或间接相互关联的,这就导致了分组数的递增。然而,该算法能够在不到五十分之一秒的时间内解决每个测试用例。因此,这种方法是一种低成本和有效的方法来计算麻将配置的缺牌数。
9.结论
在本文中,我们提出了一个有效的算法来计算麻将配置的缺陷。该算法首先将给定麻将配置的牌分成诸如伪融合牌和相对孤立牌的一些组,然后基于伪融合牌和相对孤立牌的数量来确定不足。为了评估我们的方法的性能,我们针对各种缺陷建立了超过120万个测试用例,包括所有纯配置和大约110万个混合配置。通过实验结果可以看出,亏值基本上与运行时间和分组数成反比,求解纯配置比求解混合配置需要更高的计算代价。在我们的实验中,每个麻将配置的缺陷可以在不到五十分之一秒的时间内计算出来,平均运行时间仅为0.299毫秒,这证明了我们的方法的有效性。然而,麻将话题的研究还有很长的路要走。一方面,关于中国麻将AI玩家开发的著作仍然有限;另一方面,更智能和有趣的麻将游戏包括PC和网络游戏被期待。