CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification感想(速读)
是谁?除夕还在看论文呀?
哦~~是我自己
刚刚洗完菜贴完对联切好肉blabla。。。
实在没时间细看它了,所以也是速读啦!顺便也是需要练一下自己的迅速get内容的能力呀!
我七点半就打开打算写了呢!然后现在全家都回荡着我的名字~诶呀呀,当东道主就是比较辛苦嘛,但是累并快乐着!
正好自己确实也会照顾人,哈哈哈哈,其实还是挺喜欢照顾别人的~~~
顺便!最近心情有些波动,致谢最近被我唠唠的小伙伴们!能有你们真是太幸福了!!
距离上一段过了好几个小时了,补充一下
今天的团圆饭真不错哈!今年的主题竟非常应景,可能正是因为是最好的安排,感觉一切事情发生都非常的巧合呀!
首先告诉自己每一天都会有每一天的收获,知足常乐呀!
其次,要多结识优秀的人,主动去认识去发现去了解。当然最近也成长了很多,学到了很多东西,虽然也挺痛苦的hhh,但是真的有些体会需要自己一个人去体会才能知道。接触的时间长了才知道一些人值不值得(说过了,一些事情安排得非常巧,也非常感谢wa自动机的各位!)。你听别人说的时候的判断跟你真正遇见到了之后的判断可能差别很大,可一定要理性一点~
再次哈,最近各位亲朋好友也帮了自己很多,包括一些老师都在给我开导,真的非常非常感谢!我也基本上好很多啦!新的一年,哪怕为了这些朋友家人,也要加油呀!
好了,我们来速读一下这个论文!终于废话完了
abstract
The recently developed vision transformer (ViT) has
achieved promising results on image classification compared to convolutional neural networks. Inspired by this,
in this paper, we study how to learn multi-scale feature representations in transformer models for image classification.
To this end, we propose a dual-branch transformer to combine image patches (i.e., tokens in a transformer) of different sizes to produce stronger image features. Our approach processes small-patch and large-patch tokens with
two separate branches of different computational complexity and these tokens are then fused purely by attention multiple times to complement each other. Furthermore, to reduce
computation, we develop a simple yet effective token fusion
module based on cross attention, which uses a single token
for each branch as a query to exchange information with
other branches. Our proposed cross-attention only requires
linear time for both computational and memory complexity
instead of quadratic time otherwise. Extensive experiments
demonstrate that our approach performs better than or on
par with several concurrent works on vision transformer,
in addition to efficient CNN models. For example, on the
ImageNet1K dataset, with some architectural changes, our
approach outperforms the recent DeiT by a large margin of
2% with a small to moderate increase in FLOPs and model
parameters. Our source codes and models are available at
https://github.com/IBM/CrossViT.
这里是应该好好看看的,你起码知道它要做什么东西(虽然可能看不懂)
研究了如何在用于图像分类的转换器模型中学习多尺度特征表示
双分支transformer来组合不同大小的图像patch
开发了一个简单而有效的基于交叉注意的token融合模块,该模块为每个分支使用单个token作为查询,与其他分支交换信息
introduction
速读introduction可以只看最后一部分
不过感觉在abstract里都提到了
method
可以看看这里是怎么实现的(这个其实应该花最大的一部分时间去看)

在说使用细粒度会更好,然后作者提出了一个一个双分支ViT,其中每个分支以不同的规模运行,然后提出了一个简单而有效的模块来融合分支之间的信息。
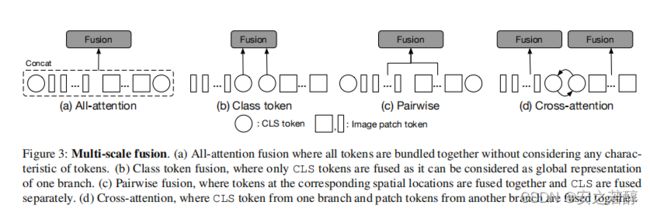
有效的特征融合是学习多尺度特征表示的关键。作者提出了四种特征融合。(在图上)后面应该验证了最后的CA比较不错。
交叉注意融合
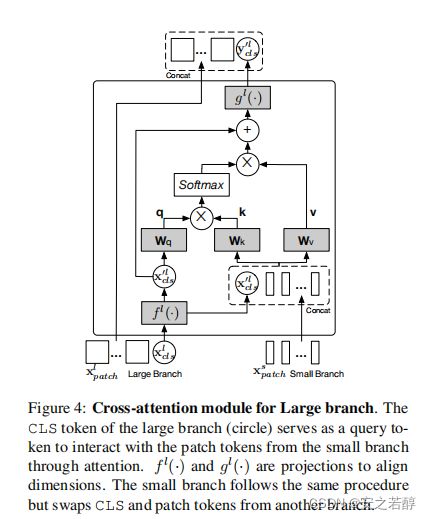
一个分支的CLS token和另一个分支的patch token
差不多就是一个的CLS token做代理,跟另一个交换,它之前已经学习了一些信息。
conclusion
这个基本就是加上数据集之后的总结。一定得看!数据集部分的实验可以只看结论(如果没有时间也就不看了,毕竟它肯定说自己的结果好。但是它有时候也会说一下自己的模型的确定与优势之类的)

最后,要注意在论文里可以学到很多专业术语(这就留给细读版吧)
最后,愿你奔走在热爱里呀~~~