【西瓜书】3-线性模型
文章目录
-
- 3.1-基本形式
-
- 3.1.1-基本形式
- 3.1.1-向量形式
- 3.2-线性回归
-
- 3.2.1-性能度量
- 3.2.2-多元线性回归
- 3.2.3-广义线性模型
- 3.3-对数几率回归
- 3.4-线性判别分析
- 3.5-多分类学习
-
- 3.5.1-ECOC
- 3.6-类别不平衡问题
- 碎碎念
- 参考
3.1-基本形式
3.1.1-基本形式
f ( x ) = w 1 x 1 + w 2 x 2 + ⋯ + w d x d + b (3.1) f(x) = w_1 x_1 + w_2 x_2 + \dots + w_d x_d + b \tag{3.1} f(x)=w1x1+w2x2+⋯+wdxd+b(3.1)
其中 x x x 为一共 d d d 个属性的示例, x i x_i xi 为 x x x 的第 i i i 个属性。 f ( x ) f(x) f(x) 为预测函数。 w w w可以代表各属性在预测中的重要性
3.1.1-向量形式
f ( x ) = w T x + b (3.2) f(x) = w^Tx+b\tag{3.2} f(x)=wTx+b(3.2)
3.2-线性回归
给定数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … ( x d , y d ) } D = \{(x_1,y_1), (x_2, y_2), \dots (x_d, y_d)\} D={(x1,y1),(x2,y2),…(xd,yd)},其中 x i = ( x i 1 ; x i 2 ; … ; x i d ) x_i = (x_{i1}; x_{i2};\dots;x_{id}) xi=(xi1;xi2;…;xid), y ∈ R y\in \mathbb{R} y∈R
线性回归试图习得一个预测函数 f ( x i ) = w x i + b f(x_i) = w x_i + b f(xi)=wxi+b
使得
f ( x i ) ≃ y i (3.3) f(x_i) \simeq y_i\tag{3.3} f(xi)≃yi(3.3)
3.2.1-性能度量
至于如何确定 w w w 和 b b b,
2.3 节介绍过,均方误差(2.2) 是回归任务中最常用的性能度量,因此我们可试图让均方误差最小化
( w ∗ , b ∗ ) = arg min ( w , b ) ∑ i = 1 m ( f ( x i ) − y i ) 2 = arg min ( w , b ) ∑ i = 1 m ( y i − w x i − b ) 2 . (3.4) \begin{aligned} \left(w^{*}, b^{*}\right) &=\underset{(w, b)}{\arg \min } \sum_{i=1}^{m}\left(f\left(x_{i}\right)-y_{i}\right)^{2} \\ &=\underset{(w, b)}{\arg \min } \sum_{i=1}^{m}\left(y_{i}-w x_{i}-b\right)^{2} . \end{aligned}\tag{3.4} (w∗,b∗)=(w,b)argmini=1∑m(f(xi)−yi)2=(w,b)argmini=1∑m(yi−wxi−b)2.(3.4)
最后用最小二乘法解得
w = ∑ i = 1 m y i ( x i − x ˉ ) ∑ i = 1 m x i 2 − 1 m ( ∑ i = 1 m x i ) 2 (3.7) w=\frac{\sum_{i=1}^{m} y_{i}\left(x_{i}-\bar{x}\right)}{\sum_{i=1}^{m} x_{i}^{2}-\frac{1}{m}\left(\sum_{i=1}^{m} x_{i}\right)^{2}} \tag{3.7} w=∑i=1mxi2−m1(∑i=1mxi)2∑i=1myi(xi−xˉ)(3.7)
b = 1 m ∑ i = 1 m ( y i − w x i ) (3.8) b=\frac{1}{m} \sum_{i=1}^{m}\left(y_{i}-w x_{i}\right) \tag{3.8} b=m1i=1∑m(yi−wxi)(3.8)
3.2.2-多元线性回归
更一般的情形是如本节开头的数据集 D D D , 样本由 d d d 个属性描述.此时我们
试图学得
f ( x i ) = w T x i + b , 使得 f ( x i ) ≃ y i f\left(\boldsymbol{x}_{i}\right)=\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b \text {, 使得 } f\left(\boldsymbol{x}_{i}\right) \simeq y_{i} f(xi)=wTxi+b, 使得 f(xi)≃yi
这称为“多元线性回归”
把数据集 D D D 表示为一个 m × ( d + 1 ) m \times (d + 1) m×(d+1) 大小的矩阵 X X X
X = ( x 11 x 12 … x 1 d 1 x 21 x 22 … x 2 d 1 ⋮ ⋮ ⋱ ⋮ ⋮ x m 1 x m 2 … x m d 1 ) = ( x 1 T 1 x 2 T 1 ⋮ ⋮ x m T 1 ) \mathbf{X}=\left(\begin{array}{ccccc} x_{11} & x_{12} & \ldots & x_{1 d} & 1 \\ x_{21} & x_{22} & \ldots & x_{2 d} & 1 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ x_{m 1} & x_{m 2} & \ldots & x_{m d} & 1 \end{array}\right)=\left(\begin{array}{cc} \boldsymbol{x}_{1}^{\mathrm{T}} & 1 \\ \boldsymbol{x}_{2}^{\mathrm{T}} & 1 \\ \vdots & \vdots \\ \boldsymbol{x}_{m}^{\mathrm{T}} & 1 \end{array}\right) X=⎝⎜⎜⎜⎛x11x21⋮xm1x12x22⋮xm2……⋱…x1dx2d⋮xmd11⋮1⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛x1Tx2T⋮xmT11⋮1⎠⎟⎟⎟⎞
Y Y Y 写成: y = ( y 1 ; y 2 ; … ; y m ) y = (y_1;y_2;\dots;y_m) y=(y1;y2;…;ym)
那么:
w ^ ∗ = arg min ( y − X w ^ ) T ( y − X w ^ ) (3.9) \hat{\boldsymbol{w}}^{*}=\arg \min (\boldsymbol{y}-\mathbf{X} \hat{\boldsymbol{w}})^{\mathrm{T}}(\boldsymbol{y}-\mathbf{X} \hat{\boldsymbol{w}}) \tag{3.9} w^∗=argmin(y−Xw^)T(y−Xw^)(3.9)
求导得:
∂ E w ^ ∂ w ^ = 2 X T ( X w ^ − y ) (3.10) \frac{\partial E_{\hat{\boldsymbol{w}}}}{\partial \hat{\boldsymbol{w}}}=2 \mathbf{X}^{\mathrm{T}}(\mathbf{X} \hat{\boldsymbol{w}}-\boldsymbol{y}) \tag{3.10} ∂w^∂Ew^=2XT(Xw^−y)(3.10)
若 X X X为正定矩阵或者满秩矩阵,可以直接解得
w ^ ∗ = ( X T X ) − 1 X T Y \hat{w}^* = (X^TX)^{-1} X^T Y w^∗=(XTX)−1XTY
反之能够解出很多个 w ^ \hat{w} w^
这个时候需要正则化处理
3.2.3-广义线性模型
在这里,我们不会逼近 y y y,反而逼近 y y y的某个函数,如 ln y \ln{y} lny 或者 y 2 y^2 y2
一般表示成:
y = g − 1 ( w T x + b ) y = g^{-1}(w^Tx+b) y=g−1(wTx+b)
3.3-对数几率回归
假设现有一模型(其实叫单位阶跃函数)
y = { 0 , z < 0 0.5 , z = 0 1 , z > 0 (3.16) y=\left\{\begin{array}{cc} 0, & z<0 \\ 0.5, & z=0 \\ 1, & z>0 \end{array}\right. \tag{3.16} y=⎩⎨⎧0,0.5,1,z<0z=0z>0(3.16)
这个函数既不连续也不可微1,那么有没有一个连续可微的替代呢?
有,sigmod函数
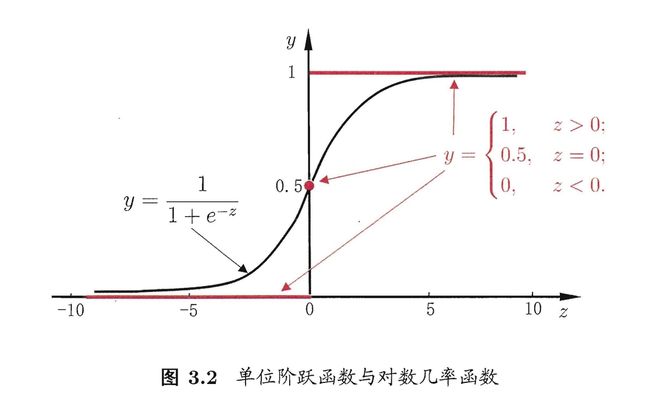
其含义是越靠近中心点的概率越高,越远离中心点的概率越低,但是函数预测的确定性越高。
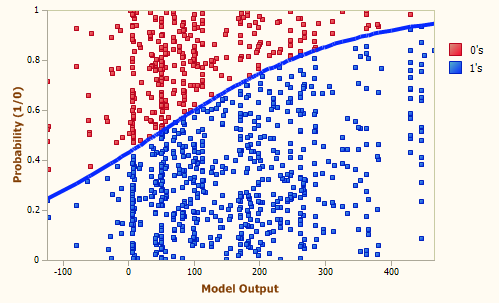
因此, “对数几率回归”(Logistic Regression)做的事情是对分类的可能性建模, 而不是去预测样本的y值2
以下面这张图为例, x x x 越大,那么预测为蓝色的概率越高,反之越低
3.4-线性判别分析
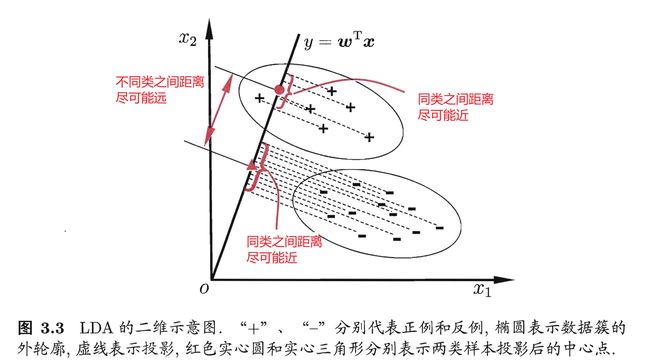
线性判别分析:Linear Discriminant nalys ,简称 LDA
其思想是:最大化类间均值,最小化类内方差。意思就是将数据投影在低维度上,并且投影后同种类别数据的投影点尽可能的接近,不同类别数据的投影点的中心点尽可能的远3。
3.5-多分类学习
对于多个分类的问题,可以将多分类问题转化为多个二分类问题
- 一对一:OvO
- 一对多:OvR
- 多对多:MvM
MvM的正反类构造有特殊要求
3.5.1-ECOC
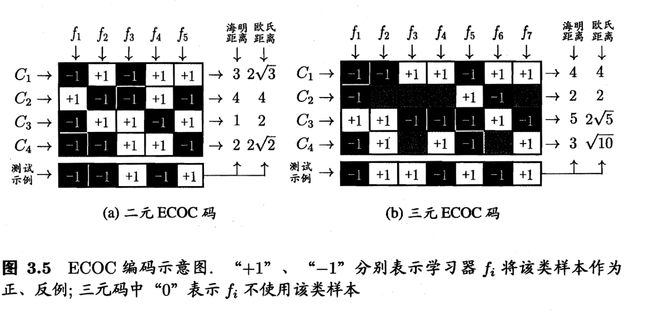
纠错输出码:Error Correcting Output Codes
- 编码:对 N 个类别做 M 次划分, 每次划分将一部分类别划为正类,一部分划为反类,从而形成一个二分类训练集;这样一共产生 M 个训练集,可训练出 M 个分类器.
- 解码:M 个分类器分别对测试样本进行预测,这些预测标记组成一个编码.将这个预测编码与每个类别各自的编码进行比较,返回其中距离最小的类别作为最终预测结果.
3.6-类别不平衡问题
假设正例有999个,但是反例只有一个,那么只需要将所有的例子都输出为正例行。但是我们其实更加看重那一个反例,而非另外的999个正例。
可以给回归的函数设置权重,原先不是 y 1 − y > 1 \frac{y}{1-y}>1 1−yy>1 就输出为正例吗?
现在时代变了,需要 y 1 − y > m + m − \frac{y}{1-y}>\frac{m^+}{m^-} 1−yy>m−m+ 才能输出为正例,这里的 m + − m^{+-} m+− 代表正例个和反例个数。这称为阔值移动
碎碎念
- github文档:https://github.com/hyperv0id/cs-notes/blob/main/ai/watermelon/3-%E7%BA%BF%E6%80%A7%E6%A8%A1%E5%9E%8B.md
- 最近在忙:https://github.com/hyperv0id/bloom-filter-ex
参考
对数几率回归 —— Logistic Regression - 知乎 (zhihu.com) ↩︎
#8 究竟什么是"逻辑回归", “对数几率回归” ↩︎
线性判别分析LDA原理及推导过程(非常详细) - 知乎 (zhihu.com) ↩︎