苦学3个月,我终于用python赚钱啦
当初学习python的原因,除了多掌握一个技能,提升自己的竞争力外,就是想利用python开启副业,拿它来帮我赚钱!!

酱酱在体验期就说得学了python可以做兼职,我是半信半疑的,带着兴趣和和好奇,开始了学习之旅
在后来的深入过程中,自己 在工作上受益颇多,提高效率,节省了很多时间,这个已经很值得
比如一键给文件夹重命名
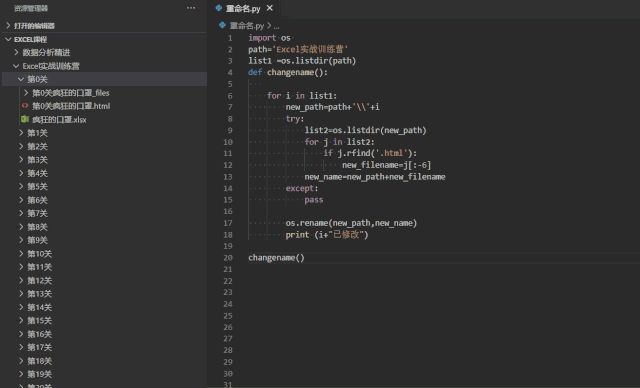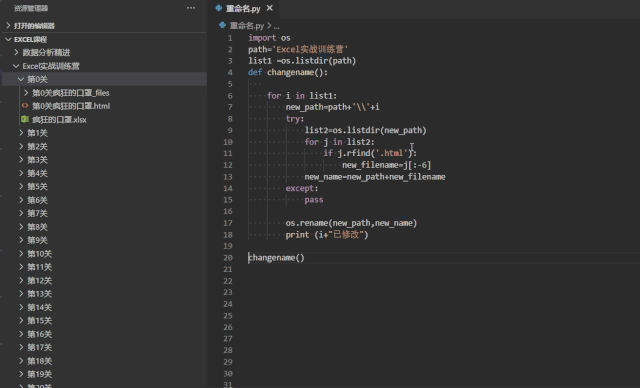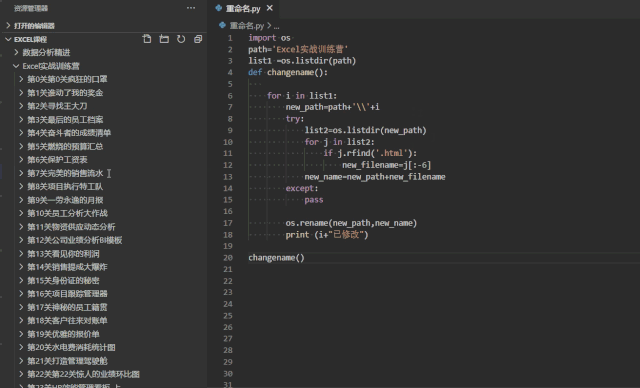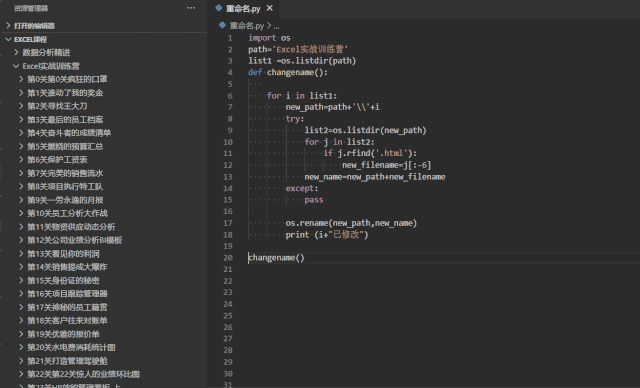
又比如下载好的文件自动解压
越学习,越觉得python有用,以缔凡的python小课作为起点,后面自己也深入去学习了SQL,MONGODB数据库,反爬虫,分布式爬虫等更加深入的知识
到今天也算学有小成,想爬的大部分网站都可以高效爬取,下一步也打算把这个技能利用起来,去变成自己的财富。
想学python的同学关注小编,申请QQ群:705933274进裙了解学习
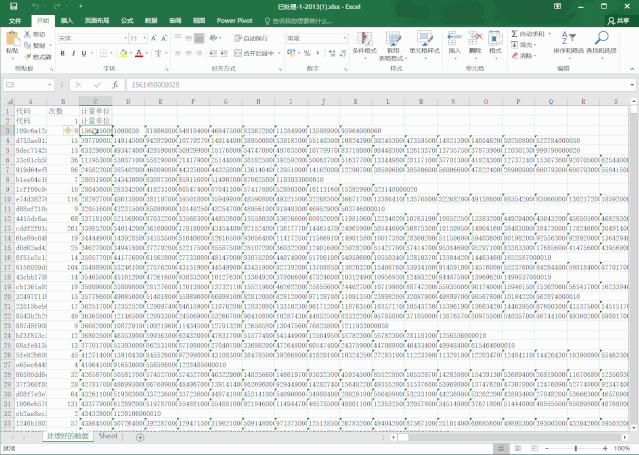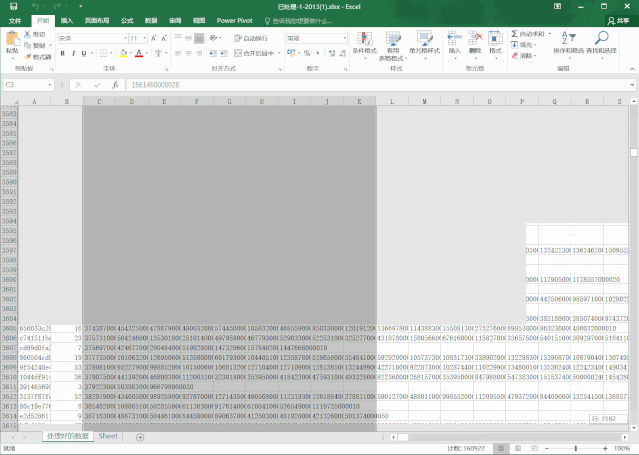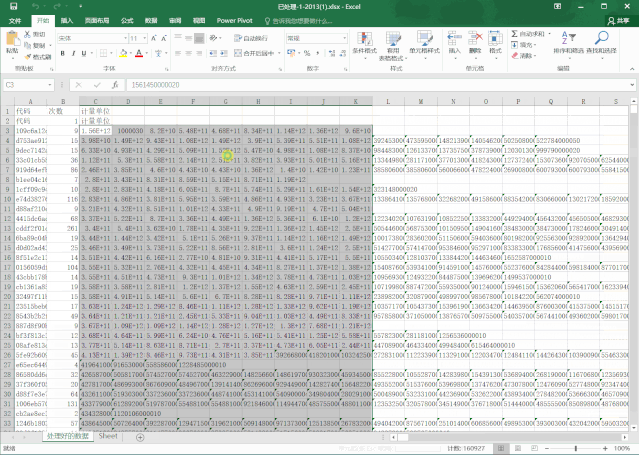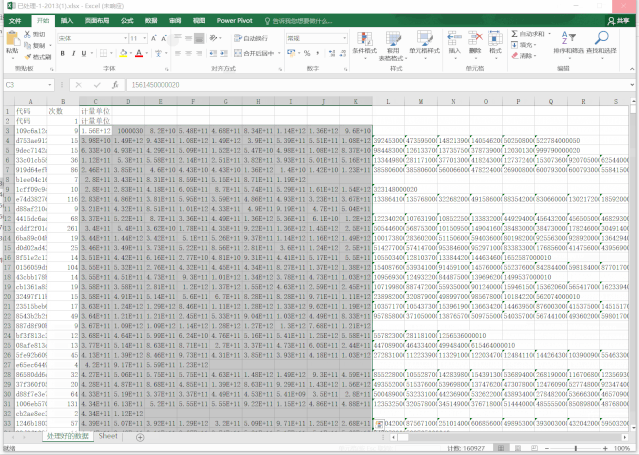
令我惊喜的是,今天,我开始了这一步。接到了我的第一个单子:处理一个一百五十多万行的excel数据!
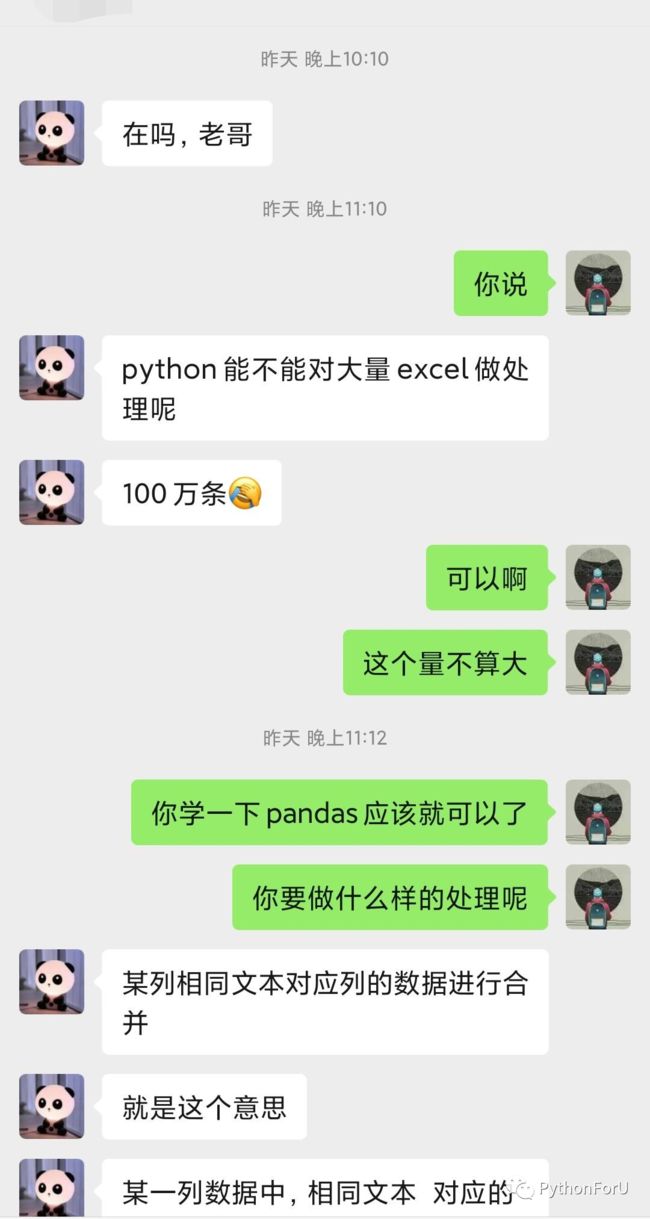
看着挺简单的,然而
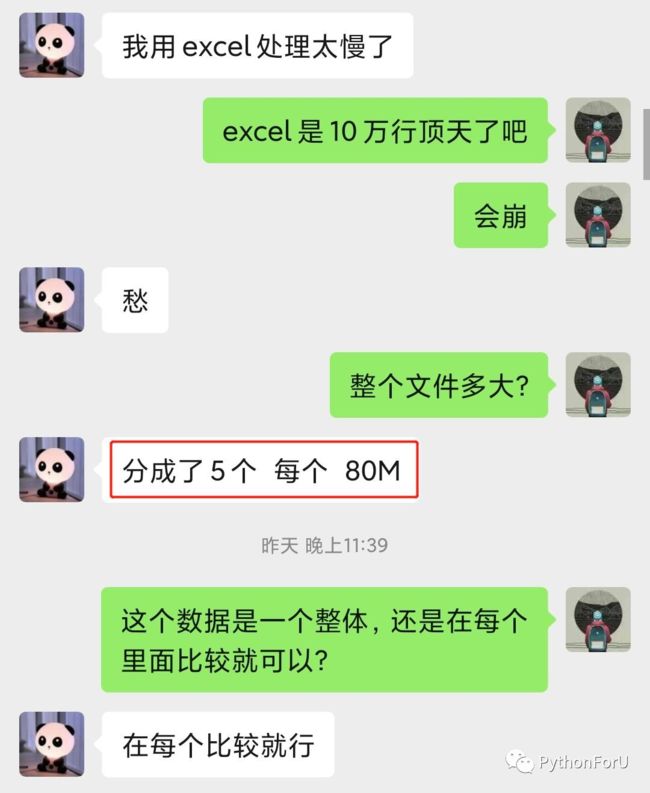
当时犹豫 了一下,因为没有试过处理这么多数据,心里没底。但是靓仔我是学过多任务的人,不能怂。
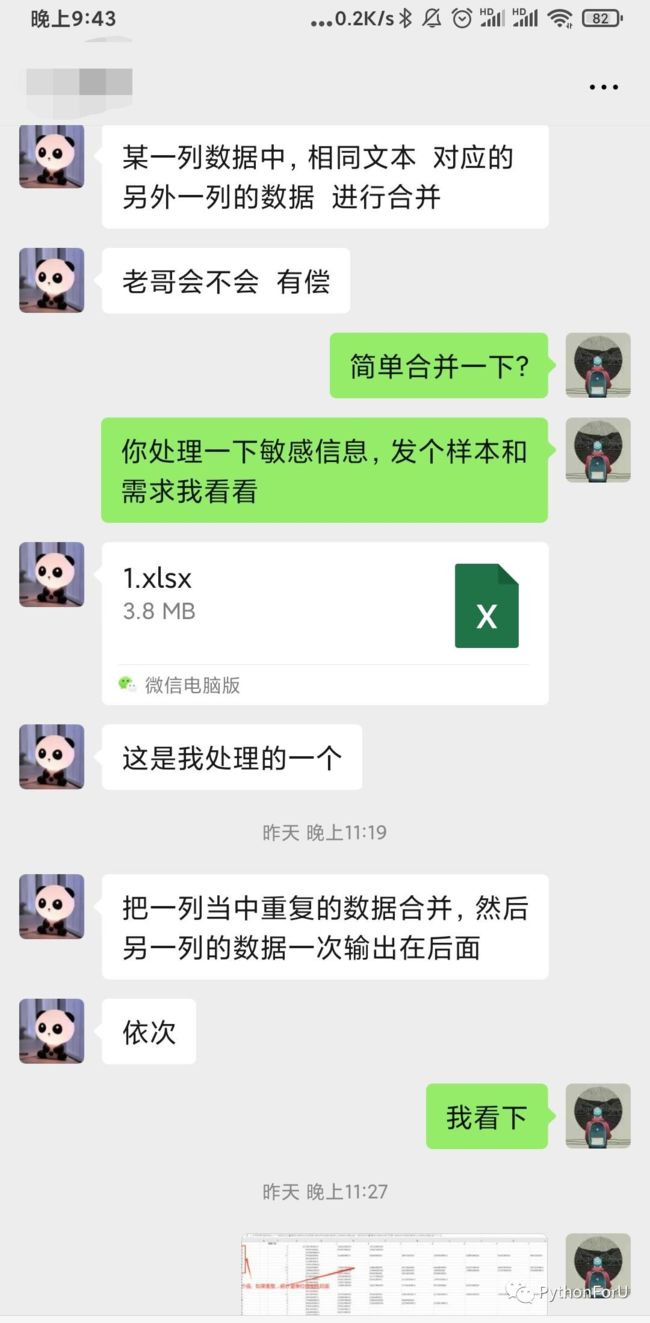
拿了一个样本,简单理解了一下需求
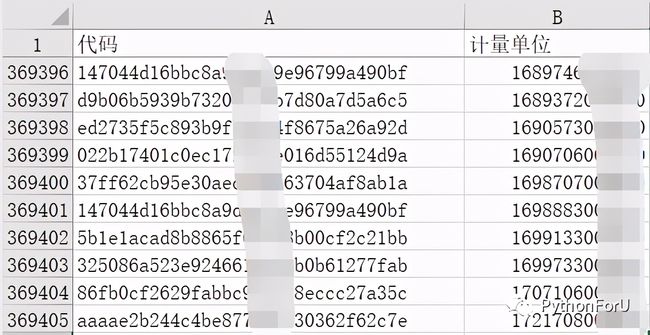
逻辑很简单:统计第1列数据的重复次数,并且把对应的第2列的值返回。
整理一下思路,最简单的方法就是,把excel前2列的值读取,然后构建字典,把第1列的值当作字典的键,第2列的值转换成列表当作键的值

然后遍历第1列,判断键是否存在,不存在则新建,存在则把第2列的值追加到值列表中,遍历完成后再写入一个新的文件
理论上是可行的
截取了3000多行的数据写了个demo运行验证了一下,用openpyxl读取文件,简单的逻辑操作,运行,得到结果,非常完美

没想到这么简单,正在为问题解决高兴,我换了其中一个30万+的数据来处理的时候,程序报错:
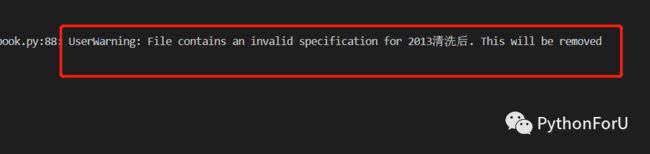
经过一番研(bai)究(du),终于定位到问题,原来openpyxl这个库最大支持读取excel文件的行数是小于16万行,超过了没法读取

正所谓一个库不行,那就换一个!python的优势就是库多,所以又把目标转向了pandas这个神器
同样一番操作,pandas虽然处理功能强大,但是导入文件仍然有行数的限制,问题没有解决
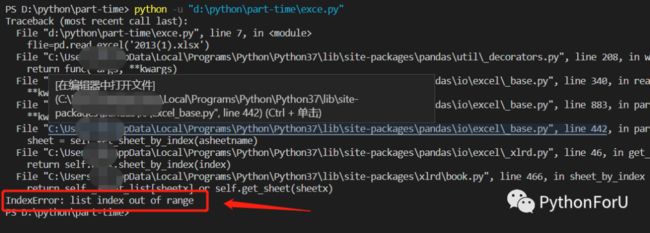
被困住后,我在考虑要不要把文件拆分成几个,这样就可以导入。但是使用代码自动拆分也行不通,因为根本没法读取!
如果手动拆分的话,又太麻烦了,失去了python自动化的意义,而且excel有可能会崩。。。。

这时灵光一现,直接读取excel会被限制,能不能转换成其它格式的文件导入呢?
下意识地就想到了CSV格式,它和xlsx格式相近,都是表格结构,而且在excel内就支持转换。
于是,我把其中一个文件转换成了CSV格式,导入,处理,一气呵成
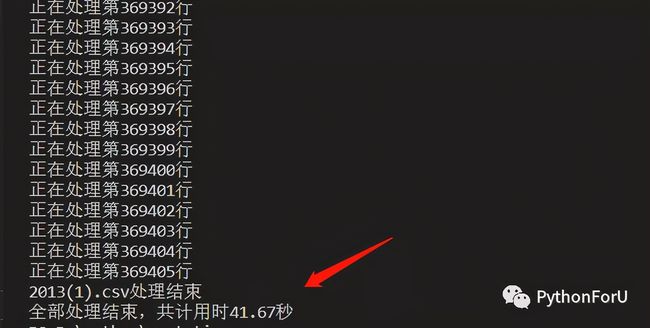
运行一下!成功了,36万行数据竟然不到一分钟就搞定了!!惊喜
本来担忧的性能问题完全没有出现!检查一下内容,也没有问题
顺手把四个文件转换成csv格式处理掉
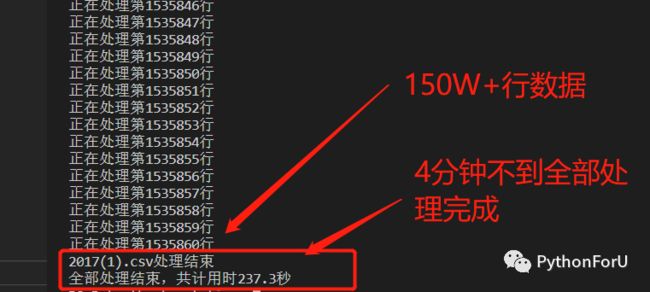
amazing!不到4分钟就处理完成了,这个速度是让我惊讶的!
后来我又试了一下使用excel直接处理这些数据,果不其然,excel停止响应了!
这样的处理无疑会浪费大量的时间,而且excel崩溃后往往还要重新做,太痛苦!!
相比之下python处理起来就简单多了!虽然前面走了一点弯路,踩了几个坑,总体时间也在3小时内搞定!
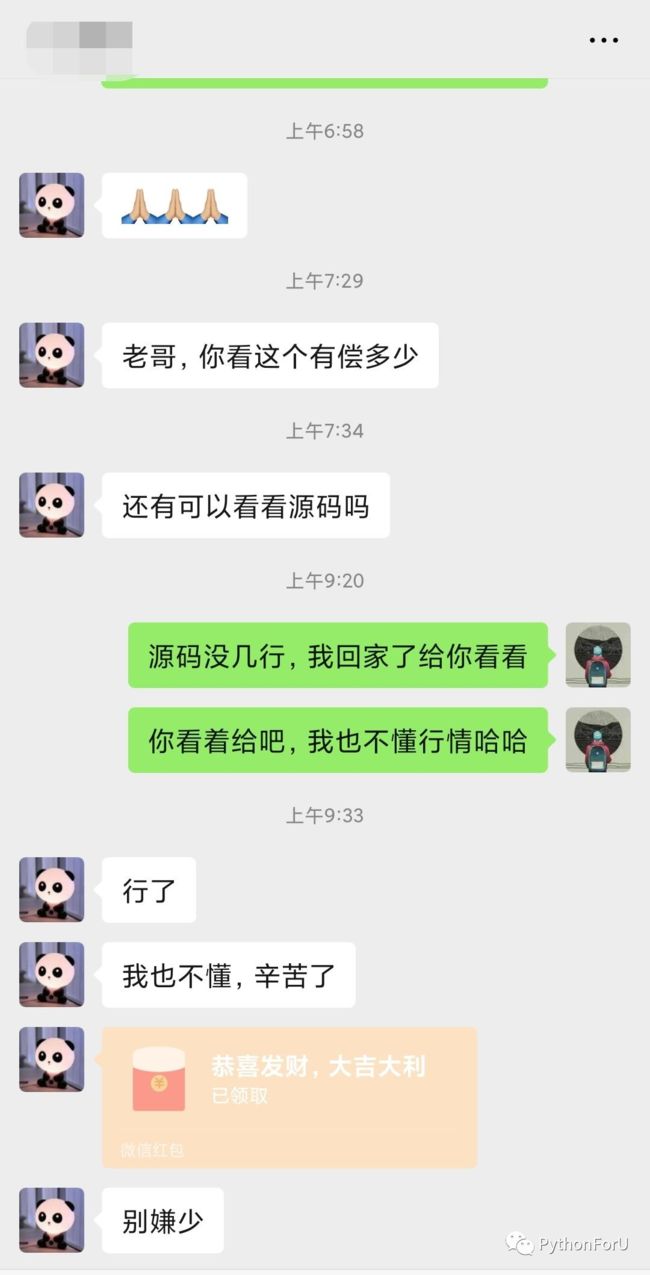
最后收到酬劳还是美滋滋的,毕竟第一次用python的技术赚钱了!
回顾一下整个过程中,不熟悉openpyxl和pandas的导入限制,不断地检索和查找原因浪费了部分时间,真正用于写代码和运行的时间是很少的
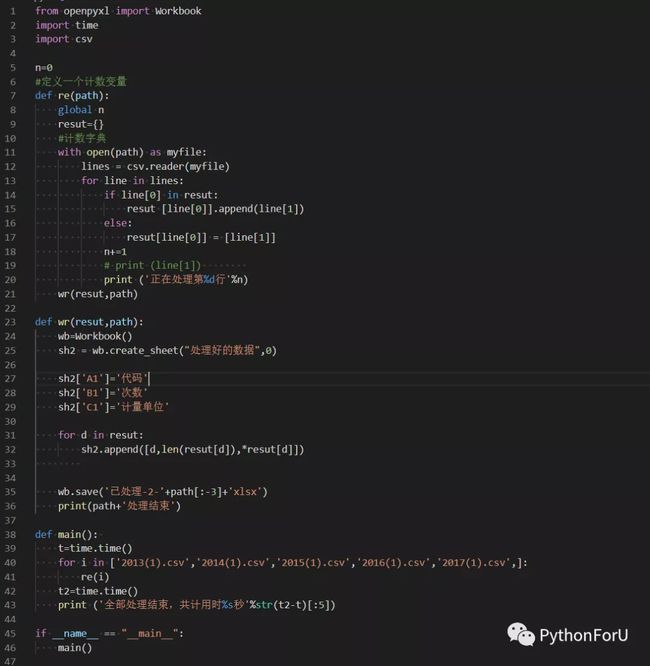
代码如上图,几乎所有的知识点,在学分表的基础语法就涵盖了。
总结一下,python的确是个有用且值钱的技能,不但在工作中提高效率,而且还能赚点小外快,快去get起来吧!
在这里还是要推荐下我自己建的Python学习Q群:705933274,群里都是学Python的,如果你想学或者正在学习Python ,欢迎你加入,大家都是软件开发党,不定期分享干货(只有Python软件开发相关的),包括我自己整理的一份2021最新的Python进阶资料和零基础教学,欢迎进阶中和对Python感兴趣的小伙伴加入!