pandas合并操作
pandas合并操作
在实际工作中,我们的数据经常存储在多个文件中,这时候就需要挨个读取出来,然后合并成一个DataFrame对象。在pandas中,可以通过pd.concat和pd.merge来实现合并的功能。
pd.concat:
pd.concat(datas, axis=1),按照行或者列合并多个数据,axis=0为列索引,axis=1为行索引。比如我们以二手车数据为例,合并广州和北京的二手车数据。示例代码如下:
df_gz = pd.read_csv("data/guazi_gz.csv")
df_bj = pd.read_csv("data/guazi_bj.csv")
df = pd.concat([df_gz, df_bj])
其中df_gz和df_bj的列名都是一样的,上述代码是将多行合并在一起。
如果要将不同列的数据合并在一起,那么则根据行索引名称进行拼接。
pd.merge:
pd.merge(left, right, how="inner", on=None, left_on=None, right_one=None)类似于SQL语句中的连接。都是指定按照共同键值对合并或者左右内连接。参数意义如下:
-
left和right:两个需要合并的DataFrame对象。 -
how:指定合并的方式。有以下可选参数。
Merge Method SQL Join Name 描述 left LEFT OUTER JOIN 只使用左边的DataFrame的key作为连接字段 right RIGHT OUTER JOIN 只使用右边的DataFrame的key作为连接字段 outer FULL OUTER JOIN 使用左边和右边的key值的并集连接 inner INNER JOIN 使用左边和右边的key值的交集连接 -
on:按照哪个字段进行合并,指定的键必须在两个DataFrame中都存在。 -
left_on:左连接的字段。 -
right_on:右连接的字段。
pd.merge合并:
- 使用
left_on和right_on参数合并:
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],
'value': [1, 2, 3, 5]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
'value': [5, 6, 7, 8]})
print(df1)
print(df2)
输出结果如下:
lkey value
0 foo 1
1 bar 2
2 baz 3
3 foo 5
rkey value
0 foo 5
1 bar 6
2 baz 7
3 foo 8
执行merge操作代码如下:
pd.merge(df1, df2, left_on="lkey", right_on="rkey")
输出结果为:
lkey value_x rkey value_y
0 foo 1 foo 5
1 foo 1 foo 8
2 foo 5 foo 5
3 foo 5 foo 8
4 bar 2 bar 6
5 baz 3 baz 7
- 使用
on参数合并:
案例对象如下:
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
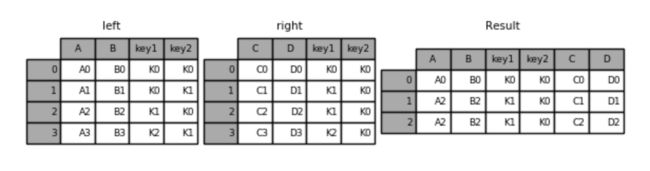
内连接:
result = pd.merge(left, right, on=['key1', 'key2'])
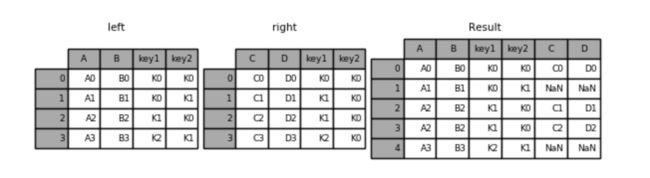
左连接:
result = pd.merge(left, right, how='left', on=['key1', 'key2'])
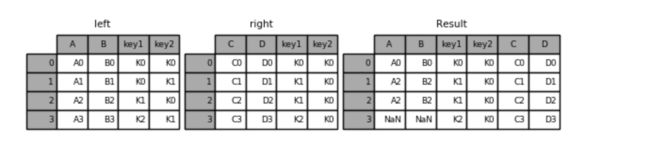
右连接:
result = pd.merge(left, right, how='right', on=['key1', 'key2'])
外连接:
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
