Jina 实例秀 | Finetuner 包教包会,一行代码完成模型微调
文章导读
Finetuner 是什么?它能解决什么问题、有哪些优势?本文将结合代码实例,带大家全面地认识 Finetuner。
Finetuner:一行代码解决模型调优
利用 Jina 从零搭建一套神经搜索系统,往往需要 1~2 天即可实现,但是对模型进行调优,则需要 1-2 周甚至更长时间。
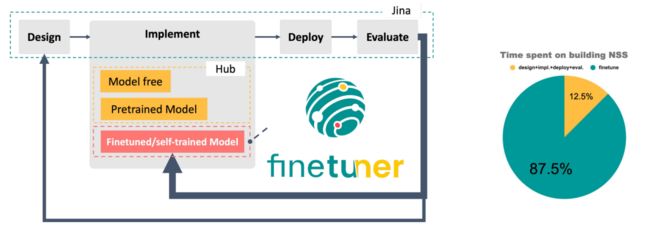
用 Jina 搭建一套神经搜索系统
约有 87.5% 的时间用于调优
为了帮助开发者更快、更简洁地调试神经搜索系统,Finetuner 应运而生。
Finetuner 是由 Jina AI 发布的神经系统结果调优工具,于 2021 年 10 月上线,可用于调整深度神经网络的权重,从而在搜索任务中获得更好的 embedding。
利用 Finetuner,只需一行代码,即可解决模型调优问题,提升预训练模型的性能。
用 Finetuner 对模型进行调优,共包括三个步骤:
1、载入数据
2、载入模型(下图示例中使用的是 PyTorch 内置的 ResNet50 模型)
3、将模型和数据传给 Finetuner fit() 函数,Finetuner 就可以自动对模型进行微调
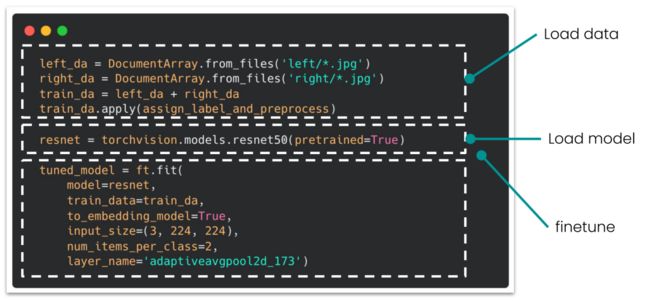
Finetuner:一行代码搞定调优过程
Finetuner 主要包含三个模块,分别与炼丹师们训练模型的三个步骤一一对应:
Labeler--数据准备
Tailer--模型搭建
Tuner--模型训练

Finetuner 支持 PaddlePaddle
PyTorch 及 Keras 三个框架
Labeler

Labeler 在实际中使用较少
Labeler 主要包含两部分:前端页面 (UI) 和存储 (Data Storage)。
Tailer
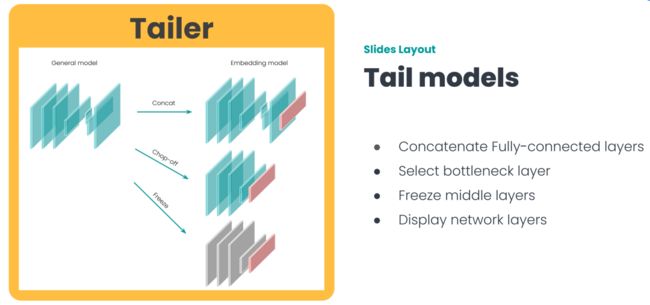
Tailer 的主要任务是准备模型
因为我们接触到的大部分模型,并不是为搜索场景设计的,无法把非结构化数据,直接转换成向量表示,所以我们需要使用 Tailer。
Tailer 的输入是一个任意模型,输出是一个新模型,这个新的模型可以计算非结构化数据的向量表示。
除此之外,Tailer 模块中还提供一些实用功能,如开发者可以指定冻结模型中的某些层。此外 Tailer 还提供可视化网络结构的 display 函数。
Tuner
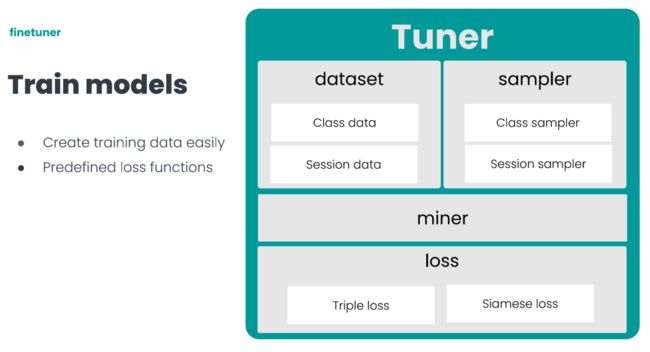
Tuner 对应模型训练的步骤
Tuner 的核心包括四个部分:dataset、sampler、miner、loss。
loss实现了搜索场景下,常用的两个损失函数 Triple loss 和 Siamese loss。
dateset 和 sampler 则主要是针对搜索场景,生成模型训练需要的数据样本。
dataset 对数据进行统一封装,sampler 会在统一数据结构的基础上,对数据进行各种操作,生产出训练模型时需要的三元组或二元组。
链接更多 Finetuner 相关信息,请访问:
https://github.com/jina-ai/finetuner
代码实例:用 Finetuner 微调 MLP
本示例中,我们将在 Fashion MNIST 数据集上对一个简单的 MLP (Multilayer Perceptron, 多层感知器) 模型进行微调,并借助 Weights & Biases 实验对训练过程进行追踪和监测。
备注:Weights & Biases 是一个兼容多种深度学习框架的可视化工具,可帮助机器学习工程师进行数据科学实验管理。
更多详情参见:https://wandb.ai/site
通过运行本 Demo,你将对 Finetuner 的特点及用法,有更深入的了解和认识。
1、安装和导入依赖项
!pip install torchvision
!pip install finetuner==0.4.0
!pip install docarray==0.5.0import torch
from torch.optim import Adam
from torch.optim.lr_scheduler import MultiStepLR
from docarray import Document
import numpy as np
from finetuner.toydata import generate_fashion
from finetuner.tuner.callback import WandBLogger
from finetuner.tuner.pytorch import PytorchTuner
from finetuner.tuner.pytorch.losses import TripletLoss
from finetuner.tuner.pytorch.miner import TripletEasyHardMiner2、验证 W&B 仪表板
进行下一步之前,需要先安装 W&B 库,并通过登录验证账户。
更多细节参见:
https://docs.wandb.ai/quickstart
!pip install wandb!wandb login3、数据预处理(此处将用到 DocArray)
更多关于 DocArray 的相关介绍,参见:
https://docarray.jina.ai/
这一步将使用 generate_fashion() 辅助函数,加载训练和测试数据。生成的 Class Dataset 参见:
https://finetuner.jina.ai/basics/datasets/class-dataset/#class-dataset
train_data = generate_fashion()
eval_data = generate_fashion(is_testset=True)接下来对数据进行预处理,向其添加一些噪声。
def preprocess_fn(doc: Document) -> np.ndarray:
"""Add some noise to the image"""
new_image = doc.tensor + np.random.normal(scale=0.01, size=doc.tensor.shape)
return new_image.astype(np.float32)4、创建模型
用 Pytorch 框架创建一个简单的 MLP 嵌入模型。
# create a MLP model
embed_model = torch.nn.Sequential(
torch.nn.Flatten(),
torch.nn.Linear(in_features=28 * 28, out_features=128),
torch.nn.ReLU(),
torch.nn.Linear(in_features=128, out_features=32),
)为了获得更好的学习率和模型训练结果,创建一个函数调用 Adam optimizer 和 dynamic scheduler。
# Function to configure learning rate optimizer and scheduler
def configure_optimizer(model):
optimizer = Adam(model.parameters(), lr=5e-4)
scheduler = MultiStepLR(optimizer, milestones=[10, 20], gamma=0.5)
return optimizer, scheduler# Creating the object for loss function and W&B callback
loss = TripletLoss(
miner=TripletEasyHardMiner(pos_strategy='easy', neg_strategy='semihard')
)
logger_callback = WandBLogger()5、微调模型
创建 PytorchTuner 对象,并设定以下训练配置:
* Triplet loss 损失函数:使用难分样本挖掘 (hard miner),并采用 easy positive 和 semi-hard negative 策略;
* Adam 优化器,初始学习率为 0.0005,每 30 次迭代减一半
* 在 Weights & Biases 通过 WandBLogger 回调,监控权重和偏差变化
# Creating a tuner object for Pytorch model
tuner = PytorchTuner(
embed_model,
loss=loss,
configure_optimizer=configure_optimizer,
scheduler_step='epoch',
callbacks=[logger_callback],
device='cpu',
)# Fitting the tuner
tuner.fit(
train_data, eval_data, preprocess_fn=preprocess_fn, epochs=40, num_items_per_class=32
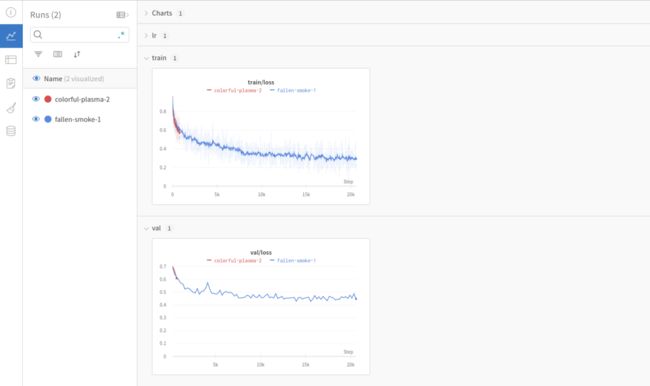
)登录 Weights & Biases 可实时查看训练过程,示例如下:
6、了解更多
Finetuner 文档:
https://finetuner.jina.ai/
在 Colab 运行本示例:
https://reurl.cc/Rj815D
GitHub:
https://github.com/jina-ai/finetuner

下一代开源神经搜索引擎
在 GitHub 找到我们
更多精彩内容(点击图片阅读)

