图像中的目标检测学习笔记(二)
9.目标检测API
Tensorflow目标检测API提供了一个简单的接口在Tensorflow中开发和训练目标检测模型。它使用一个配置文件来描述整个训练流程,包括模型架构、不同的数据集和超参数。

配置文件的描述参见:models/faster_rcnn_resnet101_v1_640x640_coco17_tpu-8.config at master · tensorflow/models · GitHub
模型:包含模型架构的描述(例如:模型名称,主干)
Train_config:包含训练参数(例如:批大小)
Train_input_reader:包含训练文件的位置
Eval_config:包含eval参数(例如:metrics)
Eval_input_reader:包含eval文件的位置
Tensorboard
Tensorboard是TensorFlow的自定义仪表板,用于监控模型的训练。运行Tensorboard--logdir
10.Training Tips #1
训练深度学习模型需要将数据从CPU迁移到GPU。这样的数据迁移会造成瓶颈,减慢训练速度,并花费大量的金钱。因为CPUs和GPUs有不同的限制,所以了解数据从一个设备迁移到另一个设备的位置,以及如何识别训练管道的任何潜在问题是至关重要的。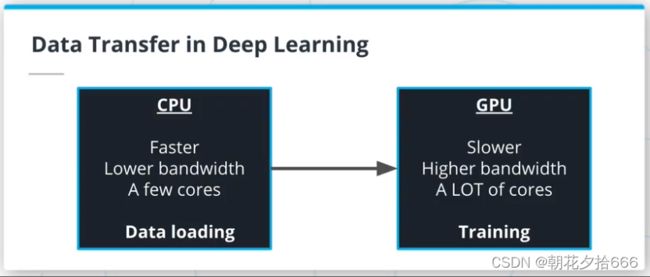
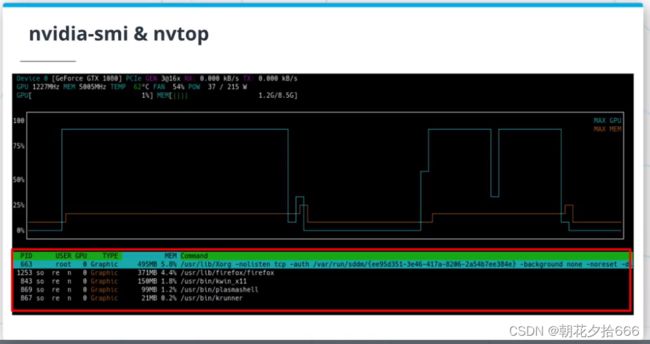
nvtop是一个很棒的开源工具(GitHub - Syllo/nvtop: AMD and NVIDIA GPUs htop like monitoring tool),用于跟踪GPU的性能。它是htop(htop - an interactive process viewer)的GPU版本,对于识别训练管道的任何潜在问题非常有用。
在训练深度神经网络时,一个很常见的问题是GPU因为接收数据不够快而空闲。换句话说,GPU处理数据的速度比CPU加载数据的速度要快。

11.Training Tips #2
当训练神经网络模型处理新问题时,遵循以下步骤可能会让你避免头疼:
与数据融为一体。尽可能深入地研究和分析您的数据集
建立基线(baselines)
检查训练管道(pipelines)
从一个简单的模型开始,不要使用任何训练技巧,比如学习率退火(learning rate annealing)
基于结果进行迭代
在训练新架构时,可以在这里找到一个详尽的检查列表(A Recipe for Training Neural Networks)。


12.练习3 -学习率退火(Learning rate annealing)
目的
在这个练习中,实现两种不同的学习率退火(衰减)策略:逐步退火和指数退火。
细节
利用Keras回调,回调在不同的训练阶段执行不同的动作。例如,Keras在每个训练周期结束时使用回调来保存模型的权重。
可以使用预实现的调度器(见提示),也可以使用自己的自定义衰减函数来实现调度器,如下所示:
def decay(model, callbacks, lr=0.001):
""" create custom decay that does not do anything """
def scheduler(epoch, lr):
return lr
callbacks.append(tf.keras.callbacks.LearningRateScheduler(scheduler))
# compile model
model.compile()
return model, callbacks 请随意使用任何衰减率以及选择的分步调度器的步长。
运行python training.py来查看不同退火策略对训练和模型性能的影响。将GTSRB数据集作为图像目录,查看最终训练指标的可视化。
提示
可以在这里(https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/schedules)找到预实现的调度器(Keras学习速率退火策略)。
参考代码:
import argparse
import logging
import tensorflow as tf
from tensorflow.keras.optimizers import schedules
from utils import get_datasets, get_module_logger, display_metrics, \
create_network, LrLogger
def exponential_decay(model, callbacks, lr=0.001):
""" use exponential decay """
# add decay
scheduler = schedules.ExponentialDecay(lr, decay_steps=100, decay_rate=0.95)
optimizer = tf.keras.optimizers.Adam(learning_rate=scheduler)
# compile model
model.compile(optimizer=optimizer,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
return model, callbacks
def step_decay(model, callbacks, lr=0.001):
""" create custom decay using learning rate scheduler """
def scheduler(epoch, lr):
if epoch % 10 == 0 and epoch > 0:
lr /= 2
return lr
callbacks.append(tf.keras.callbacks.LearningRateScheduler(scheduler))
# create optimizer
optimizer = tf.keras.optimizers.Adam(learning_rate=lr)
# compile model
model.compile(optimizer=optimizer,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
return model, callbacks
if __name__ == '__main__':
logger = get_module_logger(__name__)
parser = argparse.ArgumentParser(description='Download and process tf files')
parser.add_argument('-d', '--imdir', required=True, type=str,
help='data directory')
parser.add_argument('-e', '--epochs', default=10, type=int,
help='Number of epochs')
args = parser.parse_args()
logger.info(f'Training for {args.epochs} epochs using {args.imdir} data')
# get the datasets
train_dataset, val_dataset = get_datasets(args.imdir)
logger = LrLogger()
callbacks = [logger]
model = create_network()
# model, callbacks = exponential_decay(model, callbacks)
model, callbacks = step_decay(model, callbacks)
history = model.fit(x=train_dataset,
epochs=args.epochs,
validation_data=val_dataset,
callbacks=callbacks)
display_metrics(history)13.Waymo: AutoML
Waymo广泛使用AutoML来帮助更快、更有效地找到更好的机器学习方法。看看Waymo关于这个话题的博客吧!(https://blog.waymo.com/2019/07/automl-automating-design-of-machine.html)
14.总结
目标检测算法概述:一段式和两段式目标检测算法(RCNN家族和YOLO)
检测的后处理方法:NMS和soft NMS
新的度量标准:平均精度以及如何计算它
TensorFlow目标检测API:用TensorFlow训练目标检测算法的框架
训练和监控NN的技巧:如何利用不同的工具和训练新架构时要遵循的配方
15.术语
平均精度(mAP):一个目标检测指标。
Non-Max Suppression (NMS)和Soft-NMS:后处理技术,用于清理目标检测算法的预测。
nvtop:监控GPU使用情况的工具。
目标检测任务:对图像中的目标进行检测和分类的任务。
基于区域的CNN (RCNN):两段事(或者在最近的版本中是一段式)的目标检测算法家族。
感兴趣区域(ROI):可能包含目标的区域。
空间金字塔池化 (SPP)层:自定义(用户)层,给定一个可变大小的输入,输出一个固定长度的向量。
Tensorboard: TensorFlow训练监控仪表板。
Tensorflow目标检测API:用于开发和训练目标检测算法的Tensorflow API。
You Only Look Once (YOLO):一段式目标检测器。比FasterRCNN更快,但稍逊精确。