经典论文学习笔记——13篇对比学习(Contrastive Learning)
emsp; 跟着李沐老师的对比学习课程看了一遍,又照着知乎 / CSDN等各位大佬的总结,重新理解了一遍,下面根据自己的学习来总结一下。着重讲一下MoCo,及附带其他12种对比学习的论文的改进之处。
以下是一些可以参考的博客:
对比学习串烧(李沐大神视频学习笔记)
CVPR2020-MoCo-无监督对比学习论文解读
无监督对比学习之MOCO
如何评价Deepmind自监督新作BYOL
自监督学习
要说到对比学习,首先要从自监督学习开始讲起。自监督学习属于无监督学习范式的一种,特点是不需要人工标注的类别标签信息,直接利用数据本身作为监督信息,来学习样本数据的特征表达,并用于下游任务。
目前机器学习主流的方法大多是监督学习方法,这类方法依赖人工标注的标签,这会带来一些缺陷:
- 数据本身提供的信息远比稀疏的标签更加丰富,因此使用有监督学习方法训练的模型有时候是“脆弱”的;
- 标注成本太高
- 有监督学习通过标签训练得到的模型往往只能学到一些任务特定的知识,而不能学习到一种通用的知识,因此有监督学习学到的特征表示难以迁移到其他任务。
自监督学习分类
当前自监督学习可以被大致分为两类:
Generative Methods (生成方法)
Contrastive Methods (对比方法)
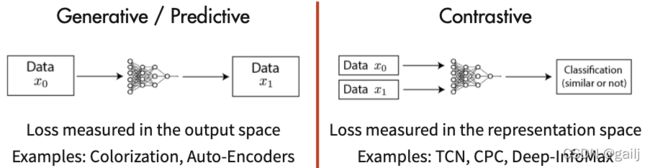
- Generative Methods(生成式方法) 这类方法以自编码器为代表,主要关注pixel label的loss。举例来说,在自编码器中对数据样本编码成特征再解码重构,这里认为重构的效果比较好则说明模型学到了比较好的特征表达,而重构的效果通过pixel label的loss来衡量。
- Contrastive Methods(对比式方法) 这类方法则是通过将数据分别与正例样本和负例样本在特征空间进行对比,来学习样本的特征表示。Contrastive Methods主要的难点在于如何构造正负样本。
对比方法相比于生成方法的主要优点:Generative Methods需要对像素细节进行重构来学习到样本特征,Contrastive Methods只需要在特征空间上学习到区分性 (其核心是通过计算样本特征间的距离,拉近正样本,拉远负样本)。因此Contrastive Methods不会过分关注像素细节,而能够关注抽象的语义信息,并且相比于像素级别的重构,优化也变得更加简单。
MoCo——何凯明带着它来拯救世界:
先讲一下MoCo,因为MoCo可以认为是最经典的对比学习算法了,随后再讲一下其他12种对比学习论文。
一.end-to-end模式:

红色框对应的正样本对特征q1和k1,蓝色框对应的是负样本特征;两个特征提取器是使用的相同的参数。输入一个batch之后,batch中的每一个样本都要当作一次正样本。
该模式存在的一个问题,就是负样本的数量受到batch size大小的限制,在没有庞大GPU集群的支持下,负样本的数量是不会特别多的。
因此,接下来有了 Memory bank 来解决这个问题。
二.memory bank模式:
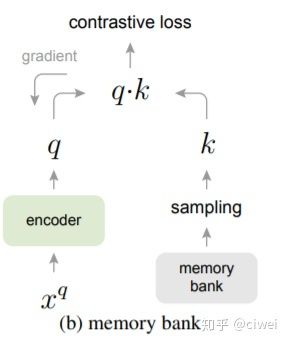

一开始,生成一个大小为k的随机队列,队列里面的feature都是随机初始化的, 这个就是Memory bank,然后开始训练,每迭代一次,将新生成的feature k1加入队列,并让队列中最初加入队列的feature出队。
其实就是将每次编码好的feature存储起来,然后每个负样本都是从memory bank中随机抽取,这样一下子就可以取很多负样本了,不会对GPU造成很大负担(因为feature相比于每张图片的大小来说,是很小的)。
但这样有个问题是存储好的编码都是之前的编码器计算的,而左侧编码器一直在更新,会有两侧不一致的情况,影响目标优化。(怎么去理解这句话呢?比如说一下子传入128张图片,然后这128张图片计算了128个feature,把这128个feature放进Memory bank中,然后从Memory bank中取出N个负样本特征。用着N个负样本特征去更新一次编码器,然后编码器更新了,下次进入Memory bank中的特征就是更新编码器后的特征了,那么假设更新了一百次,一千次,那么第一次更新的特征和最后一次更新的特征是有很大区别的,但是我们随机采样时采集的特征,有第一次,也有最后一次的,这样会引起很大的问题,我的个人理解。)
三.动量编码器(MoCo)
所以何凯明带着MoCo来拯救世界了


MoCo与Memory Bank的区别就是新feature k1的获取不是通过encoder q,而是通过encoder q参数的历史组合得到(动量编码器),Momentum encoder和encoder q的网络结构完全相同,仅是参数不一样.。Momentum 参数的具体更新公式为 :
![]()
这样Memory Bank中的feature区别就会变小,解决了Memory Bank存在的问题。
总结一下MoCo的两个主要创新点:
- 其一: dictionary队列化,把dictionary整成长度为K的队列,每次计算loss时就用K个负样本,然后将当前batch得到的特征 k kk(瞅好了,是k,不是q,k配合着创新二可以让key保持一致性) 入队,队头的batch出队,维持长度为K。
- 其二: Momentum update,因为dictionary的key来自于不同的mini-batch,通过这种方式缓慢更新(slowly progressing)key的encoder,使得key的特征保持一致性(解决了传统 Memory bank 的痛点)。实验发现,适当增加m会带来更好地效果,因此本文 m=0.999,也印证了缓慢更新key的encoder是使用队列dictionary的核心(如果更新太快的话,你想想,第一代encoder和第1000代的encoder的差距就会很大)。
附上更新流程图:

接下来讲一下对比学习的发展历程(12种对比学习论文)
第一阶段,百花齐放:方法,模型都没有统一,目标函数,代理任务也没有统一,所以说是一个百花齐放的年代。
第一篇工作:InstDise
其实就是Memory bank这篇论文,与前文讲的Memory bank一样,具体的:
该文章使用一个memroy bank存储这些负样本,imagenet中有128w的数据,意味着memory bank有128w行,因为负样本太多了,如果使用较高的维度表示图片的话,对于负样本的存储代价过高,因此作者让向量维度为128维。
假设模型的batchsize是256,有256张图片进入CNN网络,将256张图片编码为128维的向量。因为batchsize是256,因此有256个正样本。负样本来自memory bank,每次从memory bank中随机采样出4096个负数样本,利用infoNCE loss去更新CNN的参数。本次更新结束后,会将CNN编码得到的向量替换掉memory bank中原有的存储。就这样循环往复的更新CNN和memory bank,最后让模型收敛,就训练好一个CNN encoder了。
InstDise提出了个体判别这个代理任务,而且用这个代理任务和nce loss去做对比学习取得了不错的无监督表征学习的结果,同时提出了用别的结构存储这些大量的负样本,以及如何进行动量的更新,为后续的对比学习的工作产生了推进的作用。

第二篇工作是InvaSpread
可以理解为是SimeCLR的前身。InvaSpread并没有用额外的数据结构存储大量的负样本,他就是用mini batch中的数据作为负样本,而且使用一个编码器进行端到端的学习 (就是前文提到的End-to-end方法)。
该文章设置的batchsize是256。首先利用数据增广,将每个图片增广一次,也就是将256张图片变为512个图片了。之后将512张图片通过CNN编码为向量,并使用一个全连接层将数据的维度降低。之后将图片xi和其经过增广后的图片xj作为正样本,其余的 512-2 张图片都认为是负样本。所以总计有256个正例,有 2×(256-1)张负例。之后让正例之间的距离拉近,让正例与负例之间的距离拉远。
该文章的思路和SimCLR的思路差不多,都设计用batch中的数据作为正例和负例,但是该文章取得的效果没有SimCLR的效果那般炸裂。 主要是因为本文所选取的字典长度不够大,batchsize仅为256,本文也没有设计SimCLR那种投影函数和多样的数据增广方法,因此本文取得的效果不如SimCLR那么好。

第三篇工作:CPC
该模型是一个普适任务的模型,可以将音频,视频,文本等序列作为输入,利用生成的方式进行对比学习。以语音序列为例,说白了就是给你一段语音,然后前面半段输入进去,预测后面半段,将预测的结果与实际后半段的编码信息作为正例,这就是CPC的思想,是一种生成式的对比学习方法(将得到的嵌入表示作为正例,将其他的随便一段语音序列作为负例,进行对比学习的训练)。

第四篇工作CMC
CMC定义正负样本的方式:CMC使用的数据集是NYU RGBD数据集,该数据集包含一张图片的四种view数据增强结果。该文章将多view作为正例,将其他图片以及其他图片的views作为负例子,进行训练。
CMC的成功,让我们认识到对比学习可以如此的灵活(主要贡献 / 启发), Open AI团队的工作CLIP将图片-文本对作为输入,将互相匹配的图像-文本对作为正例,将不匹配的作为负例。同时CMC的原班人马利用对比学习做知识蒸馏,他们认为相同的样本在不同的编码器下得到的结果应该尽可能的相似,因此设计的teacher和student编码得到的相同图片的向量互为正例,不同图片得到的输出作为负例,利用对比学习的思路进行知识蒸馏。
但是问题在于multi view的工作可能需要多个编码器进行编码,训练代价可能有点高。比如CLIP,就是用大型的语言编码器BERT对语言模型进行编码,用视觉模型VIT对视觉信息进行编码。
总结: 第一阶段介绍以上四篇工作,可以看到以上的工作代理任务不尽相同,其中有个体判别,有预测未来,还有多视角多模态。使用的目标函数也不尽相同,有NCE,infoNCE以及其变体。使用的模型也可以是不同的,百花齐放。
第二阶段:MoCo和simCLR双雄
第一篇工作:MoCo v1
主要贡献就是把之前对比学习的一些方法归纳为一个字典查询问题。提出了一个队列,一个动量编码器,从而形成一个又大又一致的字典,帮助更好的进行对比学习。MOCO和InstDise有很多类似的地方,但是MOCO对InstDise的改进可以说是简单又有效,其提出用队列替换memory bank以及提出了动量更新的方式,对效果有显著的提升,同时对后续工作也产生了深远的影响。
具体见上面关于MoCo的介绍。
第二篇工作:simCLR v1

假如有一个minibatch的图片,对整个minibatch的所有图片做数据增强,对图片 x 做不同的数据增强就会得到 xi 和 xj 。同一个图片延申得到的两个图片就是正样本,比如batchsize是n的话,那么正样本就是n,这个batchsize剩下的所有的样本以及其经过数据增强后得到的都是负样本,也就是2(n-1)。有了正负样本之后,对其进行编码,通过一个编码器 f() 得到正负样本的编码结果 hi 。simCLR的创新点就是在得到数据的编码之后在后面加了一个编码层 g() 投影函数,就是一个MLP层,得到较低维度的特征 zi 和 zj ,用其进行对比学习,拉近正例之间的距离,拉远负例之间的距离。但是需要注意的一点就是投影函数(g())仅仅在训练的时候才使用,在测试的时候是不使用的,测试的时候仅仅使用编码器 f() 。加上投影函数的目的也仅仅是想让模型训练的更好(这里解释一下,为什么测试的时候不用投影函数。训练时用投影函数的目的是使得训练更好,因为加上了一个投影层,必然将投影到更好地结果,训练时会取得更好地效果。在实际使用时,我们需要微调这一步,微调往往是MLP,因此不需要最后一个投影层了,微调的MLP其实本来就可以当做投影层)
SimCLR和InvaSpread非常接近,不同之处在于:第一,SimCLR使用了更多的数据增强(数据增强,见下图);第二,加入了投影的 g() 函数;第三,就是SimCLR用了更大的batchsize,且训练的时间更久。

这里结合自己的理解,解释一下数据增强。如上图做了10种数据增强,但是训练时只是拿着其中一种增强来做,假设原数据个数是N,首先拿其中一种方式做增强,增强后是2N个数据,但是可以将这10种增强依次去做。并不是一下子做10N个数据(我猜测这样的原因是batch size太大,GPU容纳不下)。比如2N个数据可以做10次呀。
第三篇工作:MoCo V2
MOCO v2相当于是把SimCLR中值得借鉴的地方拿来借鉴。
比如其中MLP的投影层,更多的数据增强方式,cosine learning rate schedule,以及更多的迭代epoch。在加入了SimCLR的一些改进点后,确实取得了模型性能的进步。
作者对比了MOCO v2和SimCLR在相同的epoch和batch下的效果对比,在较小的batch和epoch下,MOCO v2取得了较好的效果,在较大的batch和epoch下,也取得了较好的效果。此外,作者将MOCO v2和SimCLR的算力作对比,发现SimCLR在batch较少的情况下无法发挥效果,在batch多的情况下才可以出效果,但是算力要求太高了。所以MOCO是一个对于计算资源要求不是很高,但是却很有效的模型。

第四篇工作 SimCLR v2:
利用少量有标注样本及大量无标注样本进行学习的一个范式是无监督预训练然后进行有监督的微调。尽管与半监督学习的方法相比我们的方法是一种任务无关(task-agnostic)的方式,但是实际的实验已经证明这是一种非常高效的方案。
论文在一开始就放出了一个非常重要的结论,那就是在自监督训练(包括fine-tune)过程中,网络结构的复杂性对效果影响很大,具体来说网络结构越宽越深,则效果越好,尤其是当有标签的数据越少时,这种影响越明显。
SimCLR V2引入了蒸馏,也就是将fine tune后的复杂模型当做teacher model,蒸馏到简单的student model上,这部分做法的主要初衷应该是在引入复杂网络后出于对模型效率的考虑。
SimCLR v2文章提出了一套用自监督网络作半监督训练的流程,该流程是用大网络(SimCLR v2)作自监督的预训练,预训练部分是没有特定下游任务的,因此不具备下游任务知识;之后使用少部分有标注的数据对模型进行微调,从而让模型学习下游任务的特定知识;让微调的模型作为teacher模型,为更多的数据打伪标签,从而实现自学习。(1. 利用更大的resnet进行无监督的预训练, 2. 在少量有标注数据集上有监督的微调, 3. 利用无标注样本集蒸馏提炼并转换特定任务的知识。)

在第三步中,无标注的样本集先经过teacher模型得到伪标签,再输入到student模型中进行自学习,所有有些博客写的是无标注样本集,有的博客写的是伪标签自学习,完整的应该是无标注的样本集先经过teacher模型得到伪标签,是这样得来的。
SimCLR v1是如何升级到SimCLR v2的呢? 1,如果使用更大的模型,则无监督训练就会训练的更好,所以SimCLR v2使用了ResNet-152并且使用了selective kernels,从而让骨干网络更加强悍;2,原来的非线性投影层是十分有效的,那么更深的非线性层会不会更加有效呢?于是作者尝试使用2层,3层,最后发现2层的效果是最好的;3,作者尝试了MOCO的动量编码器,发现效果是有提升的,但是提升的不是非常显著,大概是一个百分点,原因是SimCLR v2已经有很大的batchsize了,所以不需要太多的动量以及队列的负样本了。
第五篇工作 SwAV:
以往的基于对比学习的方法都是将一个实例 x 通过两次数据增强变为 x1 和 x2 ,之后利用编码器对其进行编码,从而得到嵌入向量 z1 和 z2 ,之后使用对比学习的loss更新这个encoder。
即使以往的工作是非常有效并且简洁的,但是负样本太多了,造成资源的浪费,即使是MOCO这样用近似的方式用6w个负样本,但是总共还是有128w个负样本的(以ImageNet为例)。所以SwAV的作者去想,可不可以使用先验信息,不去和大量的负样本对比,而是和一些更加简洁的东西去比呢? 所以SwAV的作者想,可以和聚类的中心进行对比,这个聚类中心就是 C ,维度是3000×向量维度,3000表示聚类中心的数量(这就是先验知识,可以通过一些方法使用K-means来求)。


注意:K个聚类中心其实就是全连接层FC的输出维度是K维,prototype其实就是全连接层。图中的C和Q都是K维度的,意思就是输出的结果与聚类中心数量是一一对应的。
SwAV的优势在于:
- 如果是和负例进行对比的话,需要和成千上万个负例进行对比,即使是MOCO中6w个负例,也只是一个近似的值,但是聚类的话,就仅仅需要和三千个聚类核心即可。 此外,这些聚类中心是有含义的,而如果像之前一样用负样本进行对比学习的话,有的负样本不均衡,有的还可能是正样本被错判为负样本,因此不如聚类中心有效。
- 第二个贡献就是multi-crop的思想, 以往的对比学习方法都是在一张256×256的图片上用两个224×224的crop求两个正样本,但是因为crop过大了,所选取的crop都是基于全局特征的。但是可能很多局部特征才是非常有价值的,SwAV使用了一种multi-crop的思路进行操作,即选择了两个160×160的crop去搞定全局特征,选择四个96×96的crop去搞定局部特征。这样在计算量变化不大的情况下,可以获取更多的正样本。
总结: 到了第二阶段,其实很多细节都趋于统一了,比如目标函数都是使用infoNCE,模型都归一为用一个encoder+projection head了,大家都采用了一个更强的数据增强,都想用一个动量编码器,也都尝试训练更久。
第三阶段:不用负样本的对比学习
其实SwAV已经是不用负样本了,但是他还是和一个聚类的中心这样明确的对比对象进行比较,一下介绍的BYOL和SimSiam就是正样本自己在和自己玩,已经没有正样本,或者聚类中心这样明确的对比对象了。
第一篇工作 BYOL:
之前使用负样本的学习方法相当于给模型提供一个约束。如果模型的输入只有正样本,那么模型需要让正样本之间的距离尽量的缩小,那么模型可能会想到一个捷径从而很好的解决这个问题,就是模型直接对所有样本的数据都是一致的,这样所有正样本之间的距离无限接近,但是模型这样躺平是学习不到实例的特征的,是无效的。 因此添加了负样本对模型造成一个约束,就是让正样本之间的距离接近,让负样本之间的距离拉远,这样可以对模型进行约束,不让模型躺平,所以负样本在模型中是一个必须的东西,可以防止模型躺平,防止模型学到捷径解。但是BYOL的神奇之处在于模型没有使用负样本,仅仅是模型自己和自己去学,但是也实现了很不错的效果。

让我们看看BYOL的前向过程,一个实例 X 经过两次数据增强得到 V 和 V hat,之后经过两个编码器 F1 和 F2 ,得到啷个嵌入向量 y0 和 y1 ,其中两个编码器的模型架构一样,但是参数并不相同, y0 通过动量更新,而不是反向传播更新。得到的两个向量再经过两个投影层 g0 和 g1 ,同样的两个投影层也是架构一样,但是参数不一致,前者是通过梯度下降进行更新,后者是通过动量更新,得到两个嵌入向量 z0 和 z1 。之后将 z0 输入到一个预测层 q0 中,得到 q0(z0) ,让 q0(z0) 和 z0 无限接近,使用mean squared error进行参数更新,利用正样本对正样本的预测,实现模型的学习。其中表达层是用ResNet,projection和prediction层都是用MLP。
OK,接下来说点好玩的,就是上述这个算法没有负样本是怎么做到没有模型坍塌的呢?
- 第一,有人说是因为batch norm 的存在。 因为在projection和prediction中加入了batchnorm,就相当于做了隐式负样本。因为batch norm能看到全局的信息,所有样本的信息都能看到,就造成了信息泄露。这时候正样本还是自己,但是负样本就变成了所有图形的均值和方差了(因为batch norm本来就是取均值和方差)。因此加入了batch norm是问题的根源。
但是这篇文章的作者不乐意了,如果真的这样,那BYOL就没有意义了。于是作者们通过大量的实验,发现即使有时候加入了batch norm也训练不好,也会发生模型坍塌。因此就不能证明batch norm是决定性因素,只能说明batch norm有助于训练而已。如果在初始化时参数就设置的非常好,那么不需要batch norm也可以。但是batch norm 造成信息泄露这个思想,确实很有启发性的(尽管这个观点不一定对)。 - 第二,在知乎的评论区看到一种观点,我比较认识,分享一下。如上图网络的第一行中加入了predictor 的路径,(潜在的)复杂度相对更高,拟合能力更强,然后要求这个更 flexible 的网络去拟合一个目标网络,那么拟合后的网络与目标网络有大致相当的复杂度,如果predictor只负责对编码后特征进行一个变换,从这个角度说,这个网络(第一行网络)的编码部分的复杂度就比目标网络(第二行)更低,等价的,就是其泛化能力更好,解耦性能更好。(换种说法:predictor的存在,显式的将一条路径分成两段,其实是在强迫两个编码器必须有差异,从而导致二者编码的结果不同。在这个前提下,由于过参数化,两个编码器不同,达成退化解(退化解:所有样本之间的差异都为0)的可能性大大降低了。所以,本质上这个方案利用的还是过参数化网络巨大的配置空间。)
第二篇工作 Siamese:
有许多工作像是将参数、Memory bank、动量、预测层、projection层累加,然后一点点提升性能,但是不具有通用性,到底哪一种最好呢,如果我不用这些tricks能不能训练成功呢?于是何凯明团队又来拯救世界了。
Siamese不需要用负样本,不需要大的batchsize,不需要动量编码器,即使在这种条件下,Siamese不仅没有模型谈谈,反而取得了很好的模型效果。
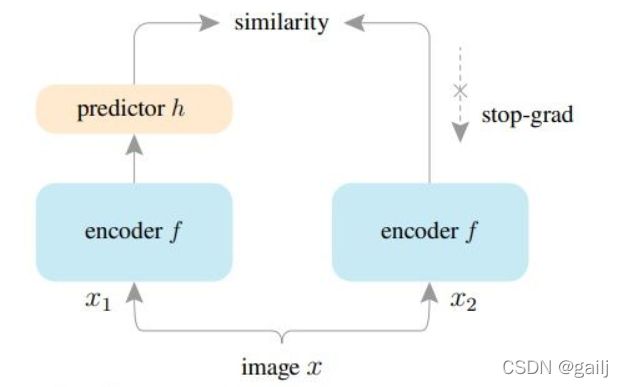
对比了不同的基于孪生网络的学习例子。SimCLR使用的是端到端的训练,两个encoder,SwAV是和聚类中心进行对比的,BYOL是一个预测任务,其使用的是动量编码器,SimSiam也是预测任务,但是使用的是stop gradiant的方式进行预测的(SmSiam与BYOL相比,主要是将动量编码器换成了普通编码器,也是不需要负样本学习)。
第四阶段:Transformer
在vision transformer之后,因为其大大提升了encoder的效果,所以很多对比学习任务打算使用vision transformer作为backbone进行对比学习,涌现出了两篇工作,分别是MOCO v3和DINO。
第一篇工作:MoCo V3
作者发现当把backbone从ResNet换为VIT后,虽然较小的batch效果还可以,但是一旦batch变大,模型就出现了不稳定的情况(因为ViT太大了,不好训练)。
作者观察了一下模型梯度回传时候的梯度情况。当每次loss有大幅的震动,导致准确度大幅下降的时候,梯度也会有一个波峰,波峰发生在第一层,在作patch projection的时候,因为这一层经常出现问题,所以作者尝试将这一层fix住,之后再进行训练,得到了很平滑的loss曲线。
第二篇工作:DINO

这个和BOYL是有点像的,也是一个预测问题。为了避免模型坍塌,其在teacher中使用了一个centering操作,即对batch求均值,之后让batch中的所有实例减去这个均值,对batch中的样本求归一化的操作。