李宏毅DLHLP.18.BERT and its family.2/2.ELMo,BERT,GPT,XLNet,MASS,BART,UniLM,ELECTRA
文章目录
- 介绍
- How to pre-train
-
- Context Vector (CoVe)
- Self-supervised Learning
-
- Predict Next Token
- Predict Next Token - Bidirectional
- Masking Input
-
- 几种MASK的方法
- XLNet
- MASS/BART
-
- Input Corruption
- UniLM
- ELECTRA
- Sentence Level
- T5 – Comparison
- 挖坑
-
- 另外一个ERNIE
- Audio BERT
- 引文
介绍
本门课程是2020年李宏毅老师新课:Deep Learning for Human Language Processing(深度学习与人类语言处理)
课程网站
B站视频
公式输入请参考:在线Latex公式
接上节,这节主要将如何进行预训练(如何得到预训练好的模型),并介绍各种预训练模型。

How to pre-train
Context Vector (CoVe)
按预训练的思路,就是要考虑上下文,获得token的embedding表示,最早干这个事情就是CoVe模型(中文是海湾的意思。),这个模型是用Translation的方法来训练模型,一个是这个模型考虑了上下文,二是这个模型训练数据是标注数据(原文与译文)。
模型架构如下图所示,其中的encoder就是预训练模型。
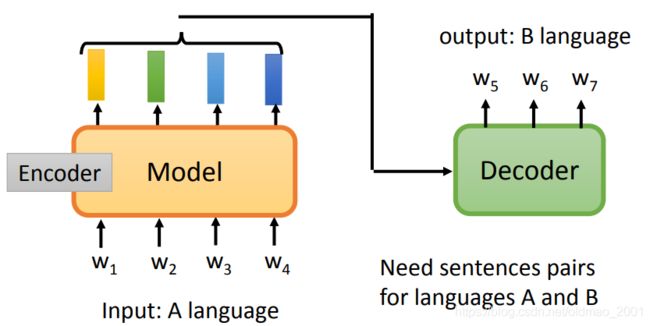
这个模型的缺点是需要大量的语料对进行训练。因此出现了自监督的学习模型Self-supervised Learning。
Self-supervised Learning
原来叫无监督学习Unsupervised Learning,杨力坤曾po文解释要用Self-supervised Learning,因为更加的贴切,是用自己本身的数据来进行预测。注意时间。
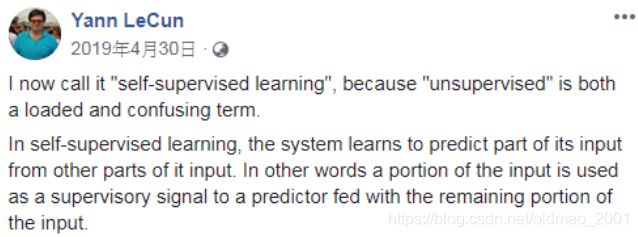
下面是两个概念的图解:

Self-supervised Learning的输入和输出都是由x进行构造的。

Predict Next Token
下面以Predict Next Token为例进行讲解。
有一个预训练模型,吃一个token,这里是 w 1 w_1 w1得到embedding: h 1 h_1 h1,然后根据 h 1 h_1 h1预测下一个token: w 2 w_2 w2

从 h t h_t ht预测下一个token的结构如下图所示,当然,可以把Linear Transform切换为NN模型,经过softmax后得到一个概率分布,我们希望这个概率分布与下一个token的概率分布(这个分布就是 w t + 1 是 1 , 其 他 都 是 0 w_{t+1}是1,其他都是0 wt+1是1,其他都是0)的交叉熵越小越好。
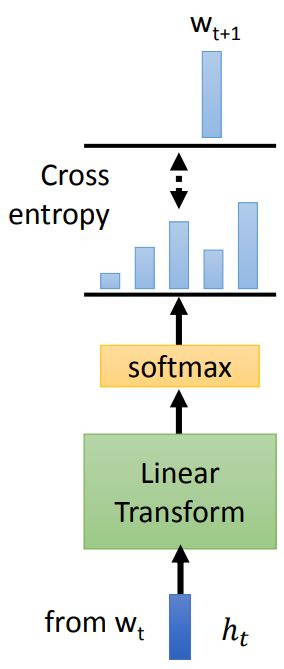
得到 w 2 w_2 w2之后,可以用同样的套路继续往下生成 w 3 w_3 w3,以此类推。

这里注意,不能同时吃所有的token,来进行预测:

这样做,模型会耍赖,直接把右边的token作为预测值,例如在用 w 1 w_1 w1预测 w 2 w_2 w2的时候,模型直接把右边一位token拿过来即可,根本不做优化,模型就没有学习到任何信息。
Predict Next Token是最早的无监督的训练方式,这个也就是语言模型language models。
通常预训练模型会采用LSTM,比较有名的就是ELMo,还有一个方法叫Universal Language Model Fine-tuning (ULMFiT)

后来有人把LSTM换成Self-attention,有名的方法是:GPT[Alec, et al., 2018]、GPT-2[Alec, et al., 2019]、Megatron[Shoeybi, et al., arXiv’19]、Turing NLG
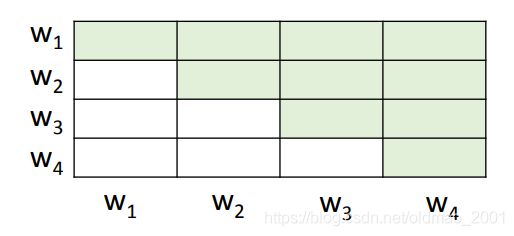
但是直接把普通的attention用到这里是不行的,因为普通的attention会对所有的token进行attention计算。因为对下一个token做attention,又预测下一个token就是让模型作弊。因此这里要对attention加上限制,不让它看某些位置。

下面的表格有颜色的部分,就是每个token做attention的限制, w 1 w_1 w1只能看 w 1 w_1 w1, w 2 w_2 w2能看 w 1 w_1 w1和 w 2 w_2 w2, w 3 w_3 w3能看 w 1 w_1 w1和 w 2 w_2 w2和 w 3 w_3 w3, w 4 w_4 w4能看 w 1 w_1 w1和 w 2 w_2 w2和 w 3 w_3 w3和 w 4 w_4 w4。就是避免预测的过程中看到下一个token。
上面的Predict Next Token模型在预测下一个token的时候,会用当前词的embedding来进行预测,当前词的embedding实际上是包含了之前所有上文的信息的。
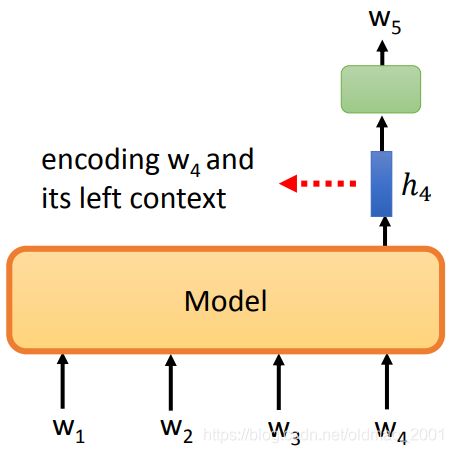
那下文信息呢?就是要双向LSTM来解决这个问题了
Predict Next Token - Bidirectional
ELMo中就用了Bidirectional LSTM,如下图所示,在生成1号embedding的时候,考虑了 w 4 w_4 w4左边的上文,生成2号embedding的时候,考虑了 w 4 w_4 w4右边的下文(这里的图示有点怪,2号明明是对应 w 5 w_5 w5),然后把1号和2号concat起来就是 w 4 w_4 w4结合了上下文的表示。

但是这个方法还是有缺陷,因为在生成1号或者2号的embedding过程中,都只看了上文或者下文,并没有通盘考虑上下文,因此BERT对此进行了改进。
Masking Input
原来的token序列如下图所示:
然后BERT将要计算的输入token盖住,盖住有两种方式,一种是使用【mask】token,一种是用随机sample的token

然后要用其他token预测盖住的token,BERT用的是Transformer,在这里attention是没有限制的,可以和任何其他token做attention计算,因为要预测的token已经盖起来了。
回顾之前学过的Word2Vec,这个方法和CBoW的思想很像,都是通过周围词预测中心词。

但是二者有几个地方不一样:
1.CBoW看上下文是有窗口大小限制的,BERT想看多长就多长(输入有多长就看多长)。
2.BERT很复杂,有24层的self-attention;CBoW就两层,中间都是linear transform。
几种MASK的方法
第一种:
在原始的BERT论文中,要MASK掉的token是随机决定的。这样是不够好的,尤其对于中文而言,盖住某个字,模型可以随意猜出盖住的字是什么,例如:张【MASK】友、人【MASK】智能。不用看很远的上下文,只用看左右几个字就可以猜出盖住了什么东西,因此模型不会学到比较long-term的关系。
Whole Word Masking (WWM)[Cui, et al., arXiv’19],就是改进BERT中的MASK,盖住整个词,例如:
[Original Sentence]
使用语言模型来预测下一个词的probability。
[Original Sentence with CWS]
使用语言模型来预测下一个词的probability。
[Original BERT Input]
使用语言[MASK]型来[MASK]测下一个词的pro[MASK]##lity。
[Whold Word Masking Input]
使用语言[MASK ][MASK]来[MASK][MASK]下一个词的[MASK][MASK][MASK]。
第二种:
还有另外一个文章:Enhanced Representation through Knowledge Integration (ERNIE)[Sun, et al., ACL’19]
Phrase-level & Entity-level
从短语的做MASK,或者从实体(就是命名实体识别任务中定义的那种实体)的角度做MASK
第三种:
SpanBert[Joshi, et al., TACL’20]
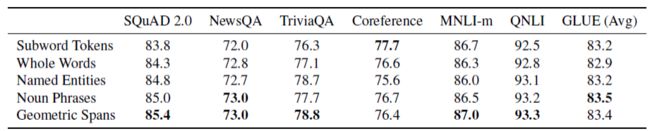
一次盖一排token,一排有多长?根据下图的几率来定:

下面是SpanBert给出的结果:
在SpanBert中还提出了一种训练方法:Span Boundary Objective (SBO)
本来BERT中是将要预测的内容盖起来,然后通过上下文对盖住的token进行预测。

SpanBert多加了一个SBO模块,如下图所示,将盖住的左右两个token作为SBO的输入,然后给定一个数字,例如3,代表预测盖住的第三个token,于是SBO输出 w 6 w_6 w6

下面是预测盖住的第二个token

这个SBO方法在coreference任务中表现较好。
XLNet
就是Transformer-XL,可以从两个观点来看,先从LM的角度看:
在预测token的时候,只能看到上文。

XLNet思想是将token随机打算再进行预测:
下面是【习度】预测【学】
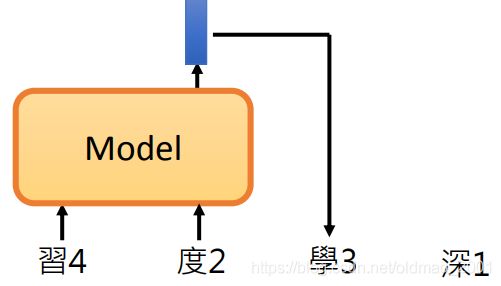
下面是【深】预测【学】

这样用不同的序列来进行学习,模型可以学到更多的dependency。(这里让我想起了GNN的随机游走)
再从BERT角度来看,BERT是盖住某个token,再用其他token来预测盖住的token:
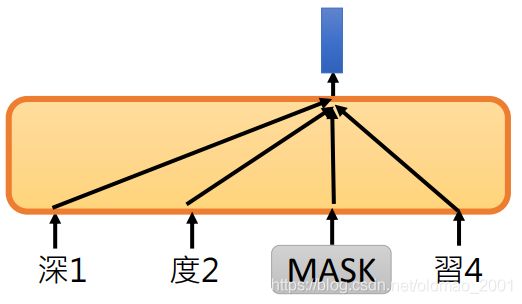
而XLNet在盖住某个token之后,并不是用所有的token来预测盖住的token,而是随机用某几个token来预测盖住的token。
下面是用【度习】预测MASK

下面是用【深】预测MASK

此外,在XLNet中,是不给模型看MASK这个token的,只给模型知道MASK的位置。
MASS/BART
对于LM模型而言,就是为了做生成任务的,Given partial sequence, predict the next token

而BERT相对来说就不怎么擅长生成sequence,当然你可以把最后一个词做成MASK,让BERT不断预测这个MASK的值,就得到一个生成模型:
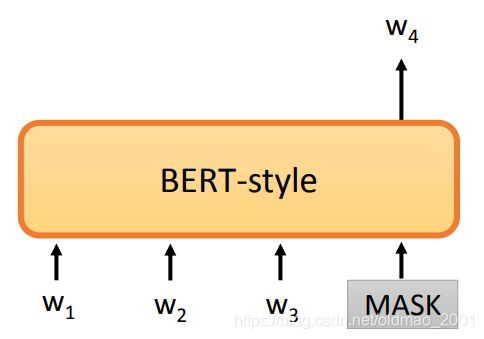
但是这样做效果不好,本来BERT在预测MASK的时候要看上下文的,这样改就看不到未生成的下文,结果当然不行。
这种从左到右的生成句子的方式成为auto-regressive的生成方式,后面还会讲none-regressive的生成方式。
因此,BERT不适合做seq2seq任务,只适合做seq2seq的encoder部分。如何训练pre-train model这样的seq2seq?如下图所示:

要把输入经过encoder,到decoder,然后得到的结果要和输入要越像越好(reconstruction error最小),为了防止模型作弊,直接copy输入,这里要对输入做一些改动,那么这里改动(Corrupted)输入方法有两种:
MAsked Sequence to Sequence pre-training (MASS) [Song, et al., ICML’19]
Bidirectional and Auto-Regressive Transformers (BART) [Lewis, et al., arXiv’19]
Input Corruption
假设我们现在的输入是:
A B [SEP] C D E
-
MASS,随机盖住一个token
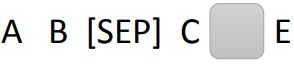
-
Delete “D”

-
permutation:互换输入句子的顺序
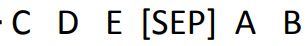
-
rotation:做轮换

-
Text Infilling:可以插入mask,一个mask可以盖住多个token。

以上就是BART采用的方法,最后论文给出的结论是:
• Permutation / Rotation do not perform well.(打乱了原来句子的顺序,打乱后的句子是病句,模型学出来的效果当然不好。)
• Text Infilling is consistently good.
UniLM
[Dong, et al., NeurIPS’19]
这个模型既是Encoder,又是Decoder,还是Encoder+Decoder=Seq2seq

下面就是UniLM原文的示意图,可以看到UniLM就是一个模块,没有分encoder和decoder,但是用不同的attention方法就可以实现不同的模型,例如:
最上面那里允许输入对所有的token进行attention,就是BERT;
中间只允许对左边的token进行attention,就是GPT,实现的是LM的功能;
最下面分为两部分attention,一块attention可以看做是encoder,可以随便和任意的token进行attention(深黄色线),一块做decoder,只能看左边的token(蓝色线)。

ELECTRA
Efficiently Learning an Encoder that Classifies Token Replacements Accurately (ELECTRA)
模型思想是用二分类任务来替换原来复杂的预测任务
例如有如下句子,对应输出embedding:
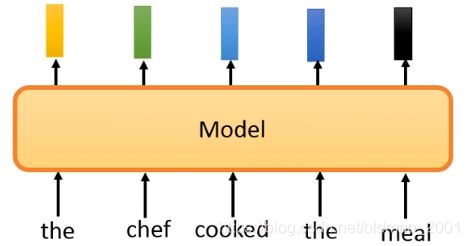
然后将输入中的某个词进行替换:
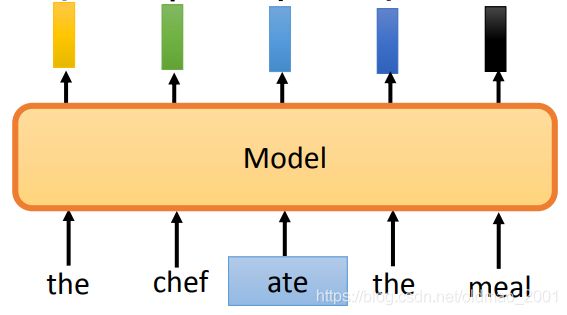
然后模型要根据替换后的结果输出当前token是否被替换:

当然,替换的词不能太突兀,不然模型一眼就看穿你替换的是哪个词,要替换为语法无错误,语义有误的词语,要做到这一点,ELECTRA使用了一个Small BERT来完成替换任务:

注:这里不是GAN,因为两个模型不是联合起来训练,也没有迭代训练。
Sentence Level
在一些任务中不但需要表达单个token的embedding,还需要有整个句子的embedding:
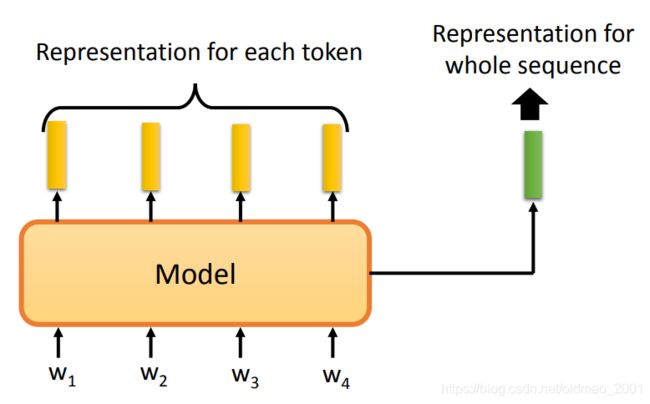
一种方法是:Skip Thought,将一句话经过Encoder,得到一个句子的embedding,然后经过Decoder,预测出下一个句子的token。
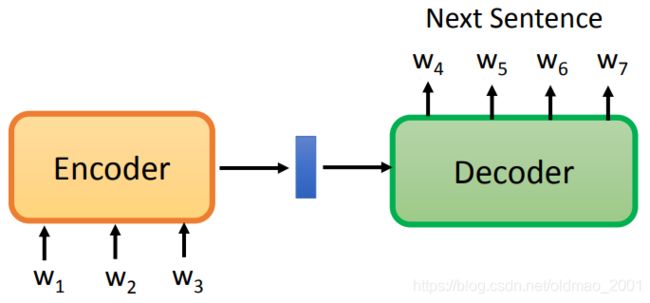
当然,这种预测是很难训练的,因此有第二种思路:Quick Thought(这个方法和ELECTRA一样,避开做预测生成这个事情,只用做判断对错比较简单。)

将两个句子分别丢入Encoder中,将得到的结果进行比较,如果两个句子是相邻的上下文关系,希望输出的embedding越相似越好。
在原始的BERT论文中,也给出了预测下一个句子的方法:NSP: Next sentence prediction
这个方法中BERT遇到【CLS】token就会生成一个embedding,这个embedding代表整个BERT的输入的所有token的信息。这个global的信息如何保证?这里用到了【SEP】token,当【SEP】两边的句子是相邻的,不是随机sample出来的句子,那么蓝色embedding经过判定模块后得到的结果是YES,否则是NO,这样模型就会关注整个输入的global的信息。

由于NSP方法中,句子如果是从不同文章里面sample出来的,句子本身的内容就讲的不同的东西,那么模型就不用很费力气就可以分辨出YES和NO,也就没有学到什么有用的信息,效果也就不怎么样。因此有另外一个方法:Sentence order prediction(Used in ALBERT )
将句子的顺序颠倒,BERT模型要识别出来,由于这个任务中所有句子都是同一个文章里面出来,只是顺序变化而已,模型要进行正确判别就学到一些有用的信息。
还有一个阿里提出来的方法structBERT (aka:Alice,阿里巴巴简称Ali,然后structBERT取c和E) ,结合了NSP和SOP,这里不展开[Want, et al., ICLR’20]。
T5 – Comparison
谷歌做的关于预训练模型的比较的文章,涉及到所有的预训练模型的比较。[Raffel, et al., arXiv’19]
• Transfer Text-to-Text Transformer (T5)
• Colossal Clean Crawled Corpus (C4)这个是实验的数据集
Colossal 巨大的。
两个都是炸药。文章50多页。。。
挖坑
另外一个ERNIE
• Enhanced Language RepresentatioN with Informative Entities
这个是另外一个ERNIE,其思想是为预训练模型中加入额外的知识,例如知识图谱,就得到ERNIE,也就是BERT+KG=ERNIE
Audio BERT
前面讲BERT 都是用在文字上,还有用在语音上的BERT,听大量没有标注的语音,然后用在各种下游任务中。
引文
超多引文,上一个课可以了解到很多模型。
• [Lewis, et al., arXiv’19] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer, BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension, arXiv, 2019
• [Raffel, et al., arXiv’19] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu, Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, arXiv, 2019
• [Joshi, et al., TACL’20] Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S. Weld, Luke Zettlemoyer, Omer Levy, SpanBERT: Improving Pre-training by Representing and Predicting Spans, TACL, 2020
• [Song, et al., ICML’19] Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu, MASS: Masked Sequence to Sequence Pre-training for Language Generation, ICML, 2019
• [Zafrir, et al., NeurIPS workshop 2019] Ofir Zafrir, Guy Boudoukh, Peter Izsak, Moshe Wasserblat, Q8BERT: Quantized 8Bit BERT, NeurIPS workshop 2019
• [Houlsby, et al., ICML’19] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly, Parameter-Efficient Transfer Learning for NLP, ICML, 2019
• [Hao, et al., EMNLP’19] Yaru Hao, Li Dong, Furu Wei, Ke Xu, Visualizing and Understanding the Effectiveness of BERT, EMNLP, 2019
• [Liu, et al., arXiv’19] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov, RoBERTa: A Robustly Optimized BERT Pretraining Approach, arXiv, 2019
• [Sanh, et al., NeurIPS workshop’s] Victor Sanh, Lysandre Debut, Julien Chaumond, Thomas Wolf, DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, NeurIPS workshop, 2019
• [Jian, et al., arXiv’19] Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, Qun Liu, TinyBERT: Distilling BERT for Natural Language Understanding, arXiv, 2019
• [Shoeybi, et al., arXiv’19]Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, Bryan Catanzaro, Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, arXiv, 2019
• [Lan, et al., ICLR’20]Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut, ALBERT: A Lite BERT for Self-supervised Learning of Language Representations, ICLR, 2020
• [Kitaev, et al., ICLR’20] Nikita Kitaev, Lukasz Kaiser, Anselm Levskaya, Reformer: The Efficient Transformer, ICLR, 2020
• [Beltagy, et al., arXiv’20] Iz Beltagy, Matthew E. Peters, Arman Cohan, Longformer: The Long-Document Transformer, arXiv, 2020
• [Dai, et al., ACL’19] Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov, Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, ACL, 2019
• [Peters, et al., NAACL’18] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer, Deep contextualized word representations, NAACL, 2018
• [Sanh, et al., NeurIPS workshop’s] Victor Sanh, Lysandre Debut, Julien Chaumond, Thomas Wolf, DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, NeurIPS workshop, 2019
• [Jian, et al., arXiv’19] Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, Qun Liu, TinyBERT: Distilling BERT for Natural Language Understanding, arXiv, 2019
• [Sun, et al., ACL’20] Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou, MobileBERT: a Compact Task-Agnostic BERT for ResourceLimited Devices, ACL, 2020
• [Zafrir, et al., NeurIPS workshop 2019] Ofir Zafrir, Guy Boudoukh, Peter Izsak, Moshe Wasserblat, Q8BERT: Quantized 8Bit BERT, NeurIPS workshop 2019
• [Sun, et al., ACL’20] Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou, MobileBERT: a Compact Task-Agnostic BERT for ResourceLimited Devices, ACL, 2020
• [Pennington, et al., EMNLP’14] Jeffrey Pennington, Richard Socher, Christopher Manning, Glove: Global Vectors for Word Representation, EMNLP, 2014
• [Mikolov, et al., NIPS’13] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S. Corrado, Jeff Dean, Distributed Representations of Words and Phrases and their Compositionality, NIPS, 2013
• [Bojanowski, et al., TACL’17] Piotr Bojanowski, Edouard Grave, Armand Joulin, Tomas Mikolov, Enriching Word Vectors with Subword Information, TACL, 2017
• [Su, et al., EMNLP’17] Tzu-Ray Su, Hung-Yi Lee, Learning Chinese Word Representations From Glyphs Of Characters, EMNLP, 2017
• [Liu, et al., ACL’19] Xiaodong Liu, Pengcheng He, Weizhu Chen, Jianfeng Gao, Multi-Task Deep Neural Networks for Natural Language Understanding, ACL, 2019
• [Stickland, et al., ICML’19] Asa Cooper Stickland, Iain Murray, BERT and PALs: Projected Attention Layers for Efficient Adaptation in Multi-Task Learning, ICML, 2019
• [Howard, et al., ACL’18] Jeremy Howard, Sebastian Ruder, Universal Language Model Fine-tuning for Text Classification, ACL, 2018
• [Alec, et al., 2018] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, Improving Language Understanding by Generative Pre-Training, 2018
• [Devlin, et al., NAACL’19] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL, 2019
• [Alec, et al., 2019] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, Language Models are Unsupervised Multitask Learners, 2019
• [Want, et al., ICLR’20] Wei Wang, Bin Bi, Ming Yan, Chen Wu, Zuyi Bao, Jiangnan Xia, Liwei Peng, Luo Si, StructBERT: Incorporating Language Structures into Pretraining for Deep Language Understanding, ICLR, 2020
• [Yang, et al., NeurIPS’19] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le, XLNet: Generalized Autoregressive Pretraining for Language Understanding, NeurIPS, 2019
• [Cui, et al., arXiv’19] Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu, Pre-Training with Whole Word Masking for Chinese BERT, arXiv, 2019
• [Sun, et al., ACL’19] Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu, ERNIE: Enhanced Representation through Knowledge Integration, ACL, 2019
• [Dong, et al., NeurIPS’19] Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, Hsiao-Wuen Hon, Unified Language Model Pre-training for Natural Language Understanding and Generation, NeurIPS, 2019