2022年 APMCM 亚太杯数学建模竞赛C题完整代码分享
C 题 全球变暖与否——思路数据分析与代码实现
对于第一问,首先要考虑的是如此庞大且粗糙的数据我们应该如何处理。
首先,很常见的想法,控制变量法,固定城市,做趋势对比(等会讲如何趋势对比)。但是看很多城市的数据,都是残次不全的,我们需要处理一下,数据缺失,当然首选插值或者拟合,这里都可以使用,在分析趋势的时候,这两者带来的误差并不大。(这里建议抽取同一个城市同一个月不同年的数据进行修补,也就是用一月的数据修正一月的数据,二月的数据修正二月的数据)(插值和拟合 MATLAB、python 都有特定的函数,上网搜一下如何使用即可,当然下个 SPSS找个教程点点鼠标也行),完整的代码:

各地区每月平均温度(1899——2022)

如何趋势对比,最好的方法就是对数据做移动平均线模型,显露出长期趋势,在回看今年 3 月的变化较之前 10 年的变化趋势是否明显增高。
如果想做的更精细一点,耗点功夫给往年 3 月的温度抽取出来,只看三月的往期趋势,再进行对比(相当于再多控制一个变量)

LSTM部分代码
%% 训练 LSTM 网络
%使用 trainNetwork 以指定的训练选项训练 LSTM 网络。
net = trainNetwork(XTrain,YTrain,layers,options);
%% 预测将来时间步
%要预测将来多个时间步的值,请使用 predictAndUpdateState 函数一次预测一个时间步,并在每次预测时更新网络状态。对于每次预测,使用前一次预测作为函数的输入。
%使用与训练数据相同的参数来标准化测试数据。
dataTestStandardized = (dataTest - mu) / sig;
XTest = dataTestStandardized(1:end-1);
%要初始化网络状态,请先对训练数据 XTrain 进行预测。
%接下来,使用训练响应的最后一个时间步 YTrain(end) 进行第一次预测。
%循环其余预测并将前一次预测输入到 predictAndUpdateState。
%对于大型数据集合、长序列或大型网络,在 GPU 上进行预测计算通常比在 CPU 上快。
%其他情况下,在 CPU 上进行预测计算通常更快。
%对于单时间步预测,请使用 CPU。
%使用 CPU 进行预测,请将 predictAndUpdateState 的 'ExecutionEnvironment' 选项设置为 'cpu'。
% net = predictAndUpdateState(net,XTrain);
% [net,YPred] = predictAndUpdateState(net,YTrain(1:end));
%
% numTimeStepsTest = numel(XTest);
% for i = 2:numTimeStepsTest+24
% [net,YPred(:,i)] = predictAndUpdateState(net,YPred(:,i-1),'ExecutionEnvironment','cpu');
% end
% %使用先前计算的参数对预测去标准化。
% YPred = sig*YPred + mu;
%
%print("有需要的同学可以进行参考https://mbd.pub/o/bread/Y5yYmppr");
C题是一个比较常见的题型,很多比赛中都出过,首先是温度预测,气候模型的求解以及分析的机器学习算法主要有:RNN神经网络;LSTM神经网络;时间序列;线性回归等等。
上述模型及算法在不同程度上可量化分析全球气候时空数据及其趋势,预测未来全球气候变化,反映全球气候变化态势。然后构建一个温度与时间和位置的关系曲线,可以用到线性回归分析模型构建相应的关系曲线。我们也完成了比较完整的代码,包含中间的所有结果和画图

本文用到的数据较多,大家进行数据分析的时候要先进行数据的预处理,总体来说难度较低,适合学习数学建模的小白和新手进行选择,我们对目前网络上的思路和代码都进行了汇总

温度检测部分Python代码:
import os
from matplotlib import pyplot as plt
import numpy as np
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
data_dir = './jena_climate_2009_2016.csv/jena_climate_2009_2016.csv' #数据存放位置
f = open(data_dir) #打开文件
data = f.read() #读取文件
f.close() #关闭
lines = data.split('\n') #按行切分
header = lines[0].split(',') #每行按,切分
lines = lines[1:] #去除第0行,第0行为标记
print(header)
print(len(lines))
#将所有的数据转为float型数组
float_data = np.zeros((len(lines), len(header)-1))
for i, line in enumerate(lines):
values = [float(x) for x in line.split(',')[1:]]
float_data[i, :] = values
'''
temp = float_data[:, 1]
plt.figure()
plt.plot(range(len(temp)), temp)
plt.legend()
plt.figure()
plt.plot(range(1440), temp[:1440])
plt.show()
'''
#数据标准化,减去平均值,除以标准值
mean = float_data[:200000].mean(axis = 0)
float_data -= mean
std = float_data[:200000].std(axis = 0)
float_data /= std1900-2022全球月与年平均温度

各维度平均温度(到2012)

二氧化碳排放数据

温度检测部分Python代码:
#数据生成器
def generator(data, lookback, delay, min_index, max_index, shuffle=False, batch_size=128, step=6):
if max_index is None:
max_index = len(data) - delay - 1
i = min_index = lookback
while 1:
if shuffle: #打乱顺序
rows = np.random.randint(min_index + lookback, max_index, size=batch_size)
else:
if i + batch_size >= max_index:
i = min_index + lookback #超过记录序号时,从头开始
rows = np.arange(i, min(i+batch_size, max_index))
i += len(rows)
samples = np.zeros((len(rows), lookback // step, data.shape[-1]))
targets = np.zeros((len(rows), ))
for j, row in enumerate(rows):
indices = range(rows[j] - lookback, rows[j], step)
samples[j] = data[indices]
targets[j] = data[rows[j] + delay][1]
yield samples, targets
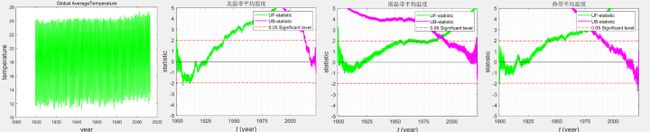
%% 计算每个月的全球平均气温
YearStart = min(Data_int(:,1));
YearEnd = max(Data_int(:,1));
GlobalAverage = zeros((YearEnd-YearStart+1)*12,5);
for i = 1:N
if ~isnan(Data_int(i,3))
startIdx = (Data_int(i,1)-YearStart)*12+Data_int(i,2);
GlobalAverage(startIdx,1) = Data_int(i,1);
GlobalAverage(startIdx,2) = Data_int(i,2);
GlobalAverage(startIdx,3) = GlobalAverage(startIdx,3) + 1;
GlobalAverage(startIdx,4) = GlobalAverage(startIdx,4) + Data_int(i,3);
GlobalAverage(startIdx,5) = GlobalAverage(startIdx,5) + Data_int(i,4);
end
end
for i = 1:size(GlobalAverage,1)
if GlobalAverage(i,3)>0
GlobalAverage(i,4) = GlobalAverage(i,4)/GlobalAverage(i,3);
GlobalAverage(i,5) = GlobalAverage(i,5)/GlobalAverage(i,3);
end
end