Tensorflow学习笔记:分类CIFAR10图像数据集来介绍CNN的原理
CNN来分类CIFAR10图像数据集
在 Tensorflow学习笔记:传统NN和CNN来分类MNIST手写数字数据集,我们研究了如何设计一个简单的Dense神经网络来分类手写数字的图像,然后简单介绍和设计了简单的CNN卷积神经网络结构,也简单说了一下这两个方法的区别。如果想自己练习,可以用tensorflow的keras.datasets.fashion_mnist数据集作分类,和MNIST手写的图像数据集类似。
这篇文章的目的是简单介绍一下卷积神经网络原理,然后和设计一个CNN和来分类CIFAR10图像数据集。
卷积神经网络原理
keras.datasets.mnist和keras.datasets.fashion_mnist两个数据集输入(图像)的维度为2,属于非常简单的数据。 现在我们将要处理通常由 3 个维度组成的图像数据。 这3个维度如下:
- 图像高度
- 图像宽度
- 颜色通道
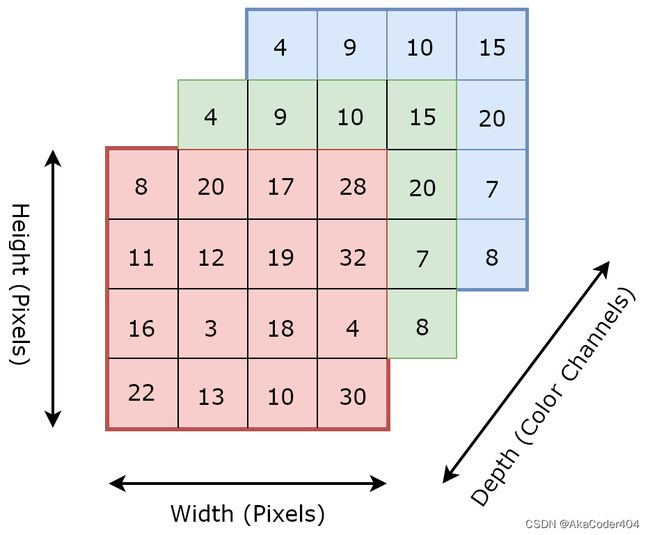
如果你只用过mnist数据集,可能不理解的唯一项目是颜色通道。 颜色通道的数量表示图像的深度,并与其中使用的颜色相关。 例如,具有三个通道的图像可能由 rgb(红、绿、蓝)像素组成。 因此,对于每个像素,我们都有 0-255 范围内的三个数值来定义其颜色。 对于颜色深度为 1 的图像(比如mnist),我们可能会得到一个灰度图像,其中每个像素定义一个值,同样在 0-255 的范围内。
每个卷积神经网络都由一个或多个卷积层(convolutional layers)组成。 这些层与我们之前看到的密集层不同。 他们的目标是从图像中找到可用于对图像或其部分进行分类的模式。 但这对我们在上一节中密集连接的神经网络所做的事情可能听起来很熟悉,那是因为它是。
密集层和卷积层之间的根本区别在于,密集层全局检测模式,而卷积层局部检测模式。 当我们有一个密集连接层时,该层中的每个节点都会看到前一层的所有数据。 这意味着该层正在查看所有信息,并且只能以全局容量分析数据。 然而,我们的卷积层不会密集连接,这意味着它可以使用该层的部分输入数据检测局部模式。
让我们看看密集连接层如何看待图像与卷积层如何。这是我们的形象; 我们网络的目标是确定这张图片是否是一只猫。

密集层:密集层将考虑整个图像。 它将查看所有像素并使用该信息生成一些输出。
卷积层:卷积层将查看图像的特定部分。 在此示例中,假设它分析下面突出显示的部分并在那里检测模式。
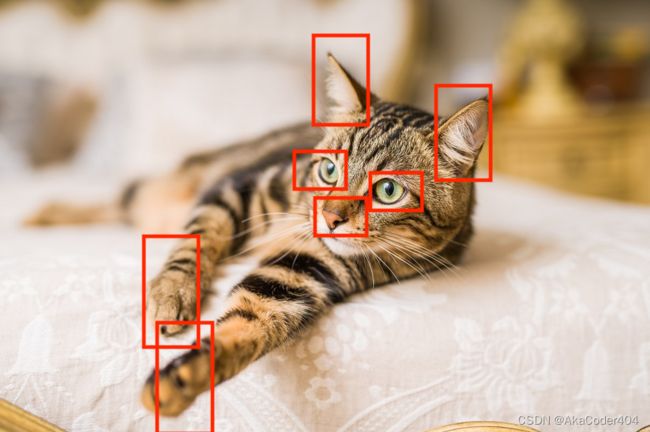
你能明白为什么这会使这些网络更有用吗?
密集的神经网络学习存在于图像的一个特定区域中的模式。这意味着如果网络知道的模式存在于图像的不同区域中,它将必须在该新区域中再次学习该模式才能检测到它。让我们考虑上面的猫的图像。
我们将考虑我们有一个密集的神经网络,它已经从猫图像样本中学习了眼睛的样子。假设如果方框中的位置存在眼睛,则确定图像很可能是猫。然后假设我们翻转图像。
由于我们密集连接的网络仅在全球范围内识别出模式,因此它将查看它认为眼睛应该出现的位置。显然它没有在那里找到它们,因此很可能会确定这张图片不是猫。即使存在眼睛的图案,它只是在不同的位置。
由于卷积层从图像的不同区域学习和检测模式,因此它们与我们刚刚说明的示例没有问题。他们知道眼睛的样子,并通过分析图像的不同部分可以找到它的存在位置。
多个卷积层 Multiple Convolutional Layers
在卷积神经网络模型中,具有多个卷积层是很常见的。 即使我们将基本示例也将由 3 个卷积层组成。 这些层通过增加每个后续层的复杂性和抽象性来协同工作。 第一层可能负责拾取边缘和短线,而第二层将这些线作为输入并开始形成形状或多边形。 最后,最后一层可能会采用这些形状并确定哪些组合构成特定图像。
特征图 Feature Maps
您可能会看到我在本文章中使用术语特征图。 该术语仅代表具有两个空间轴(宽度和高度)和一个深度轴的 3D 张量。 我们的卷积层将特征图作为其输入,并返回一个新的特征图,该特征图表示来自先前特征图的特定过滤器的存在。 这些就是我们所说的响应图。
层的参数
卷积层有两个重要参数
Filters
过滤器是我们在图像中寻找的 m x n 像素模式。 卷积层中的过滤器数量表示每层正在寻找多少模式以及我们的响应图的深度是多少。 如果我们正在寻找 32 种不同的模式/过滤器,那么我们的输出特征图(也称为响应图)的深度将为 32。32 层深度中的每一层都将是一个具有一定大小的矩阵,其中包含指示过滤器是否为 是否出现在那个位置。
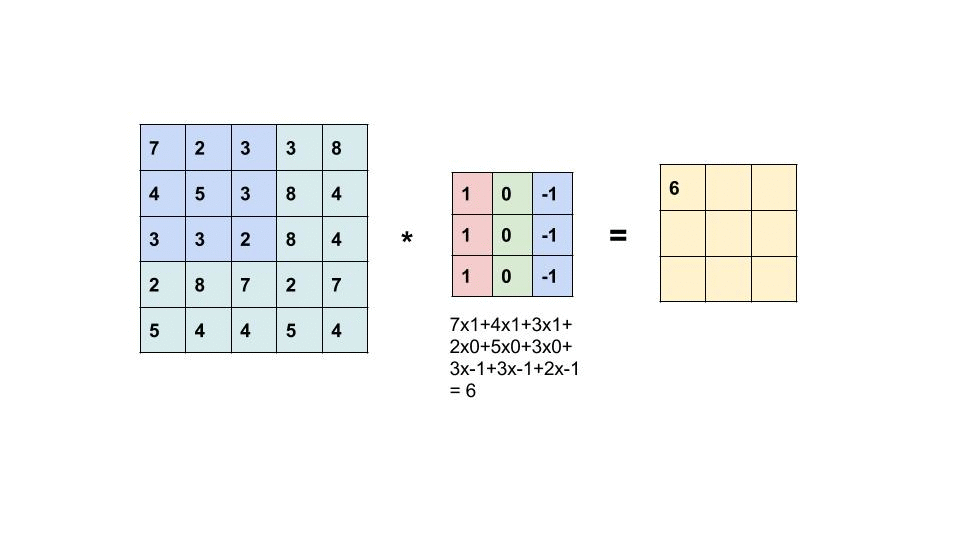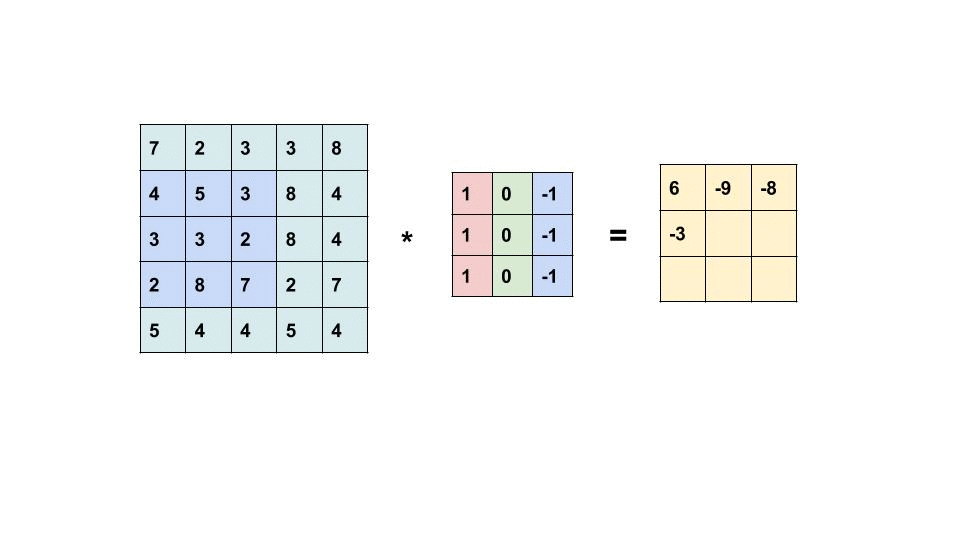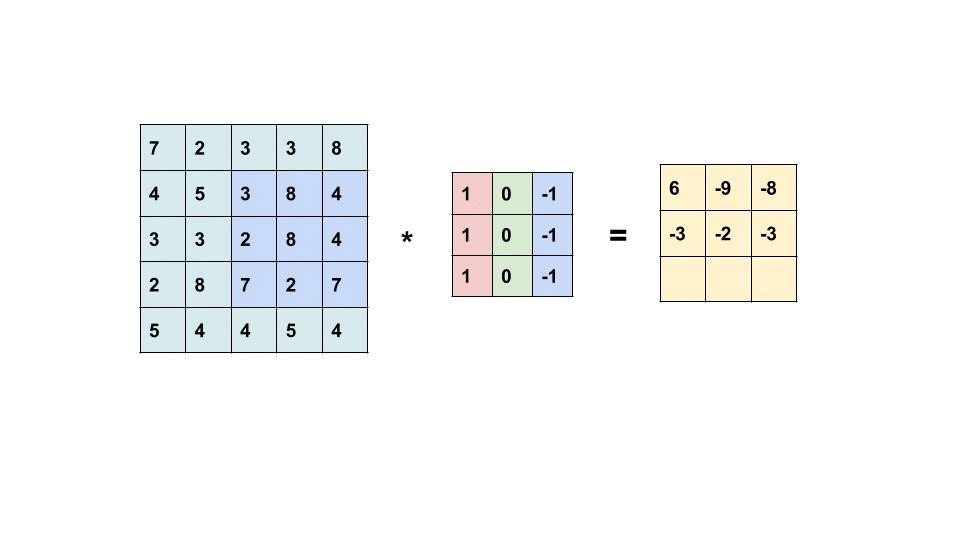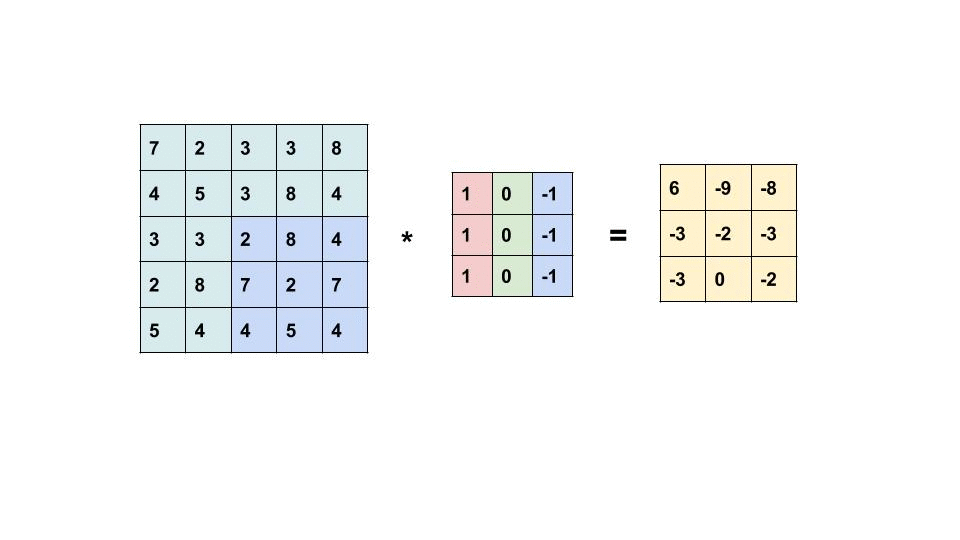
左边的矩阵是你的输入,中间的矩阵是我们的过滤器,右边的矩阵是我们的特征图
样本容量 Sample Size
每个卷积层将检查每个图像中的 n × m n\times m n×m 个像素块。 在上图中,我们使用 3x3 的样本容量。 这个大小将与我们过滤器的大小相同。 我们的层通过在图像中每个可能的位置上滑动这些 n × m n \times m n×m 像素的过滤器并填充新的特征图/响应图来指示过滤器是否存在于每个位置。
填充 Padding
您可能已经意识到,如果我们在图像上滑动一个 3x3 大小的过滤器,那么我们的过滤器位置应该比输入中的像素少。
这意味着我们的响应图的宽度和高度将比我们的原始图像略小。 这很好,但有时我们希望我们的响应图具有相同的维度。 我们可以通过使用一种叫做填充的东西来实现这一点。 填充只是将适当数量的行和/或列添加到您的输入数据中,以便每个像素可以由过滤器居中。 填充函数中的值不应影响输出。 因此,在某些情况下,它们可以用零填充。
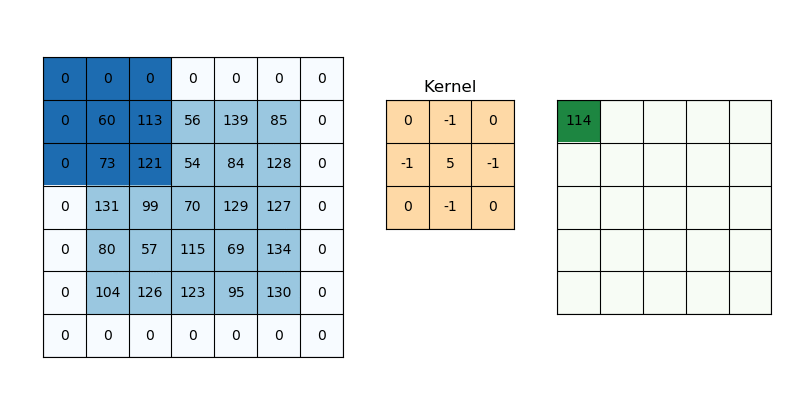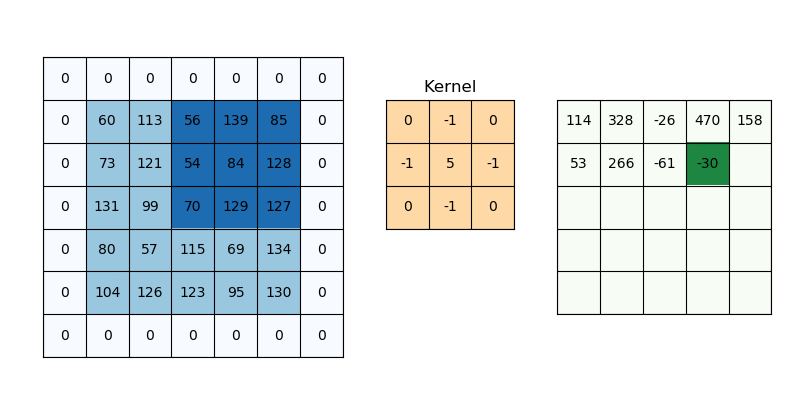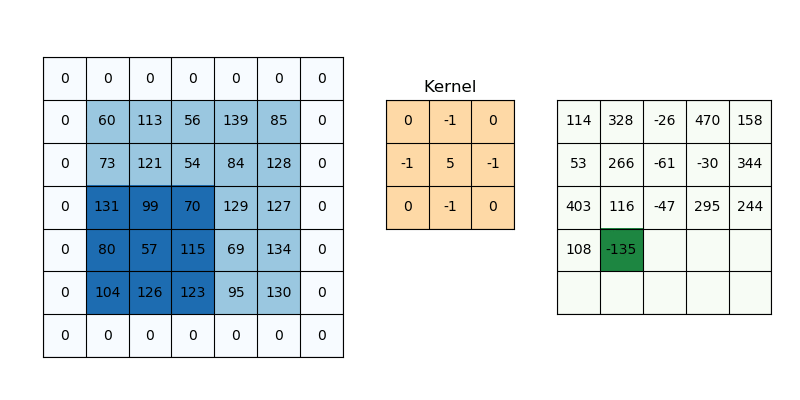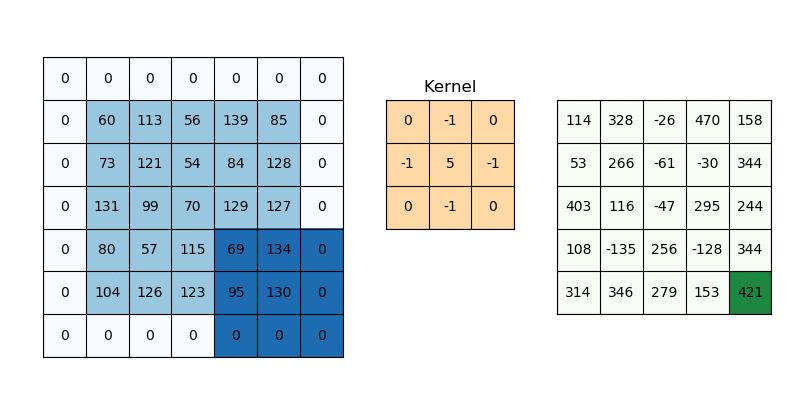
在上图中,如果没有填充,则特征图将为 3x3。
长步 Strides
在前面的部分中,我们假设过滤器将在图像中连续滑动,以覆盖所有可能的位置。 这很常见,但有时我们会在卷积层中引入步幅的概念。 步幅大小表示我们每次将移动过滤器的行数/列数。 在下面的示例中,步长为 2。
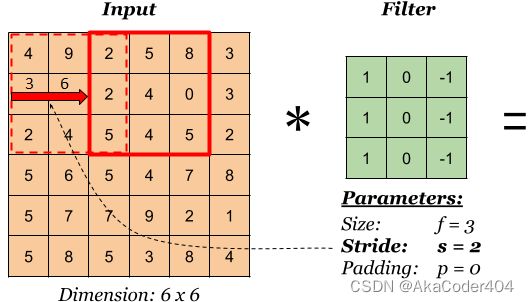
池化 Pooling
您可能还记得我们的卷积网络是由一堆卷积和池化层组成的。池化层背后的想法是对我们的特征图进行下采样并减小它们的维度。 它们的工作方式类似于卷积层,它们从特征图中提取窗口并返回每个通道的最大值、最小值或平均值的响应图。 池化通常使用大小为 2x2 且步幅为 2 的窗口来完成。这会将特征图的大小减少两倍,并返回一个小 2 倍的响应图。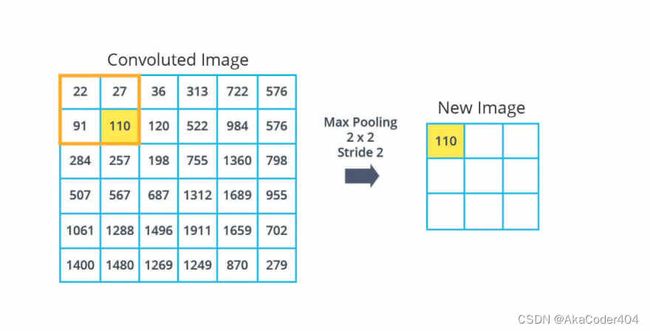
这是卷积神经网络的基础。 我们不会了解这一切是如何在更低级别发生的。下面我们来设计CNN神经网络!
CIFAR10 数据集
首先我们倒入相关的数据
# imports
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
import visualkeras # visualize our cnn
# constants
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
这个数据集有60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images
这个数据集有有60000 张 32x32 彩色图像和 10 个类,每类 6000 张图像。 有50000张训练图像和10000张测试图像
加载数据
# load and preprocess dataset
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
再看看数据集中的一些图像
| Frog | Truck | Truck | Deer | Automobile |
|---|---|---|---|---|
 |
 |
 |
 |
 |
CNN结构
CNN 的常见架构是一堆 Conv2D 和 MaxPooling2D 层,然后是一些密集连接的层。 想法是卷积层和 maxPooling 层的堆栈从图像中提取特征。 然后这些特征被展平并馈送到密集连接的层,这些层根据特征的存在确定图像的类别。
# cnn architecture
# convolutional base
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
然后加密集层
# dense layer
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
model.summary()
visualkeras.layered_view(model, legend=True)
总体结构为
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
visualkeras来形象化我们的神经网络结构
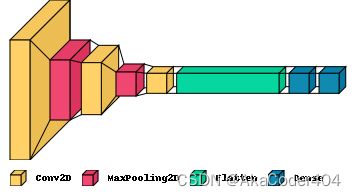
NN-SVG来形象化我们的神经网络结构
绿色框里描述我们的CNN的base,蓝色描述我们的dense层。
编译和训练
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
Epoch 1/10
1563/1563 [==============================] - 14s 8ms/step - loss: 0.8310 - accuracy: 0.7100 - val_loss: 0.9042 - val_accuracy: 0.6903
Epoch 2/10
1563/1563 [==============================] - 12s 8ms/step - loss: 0.7677 - accuracy: 0.7333 - val_loss: 0.9140 - val_accuracy: 0.6910
Epoch 3/10
1563/1563 [==============================] - 12s 8ms/step - loss: 0.7182 - accuracy: 0.7485 - val_loss: 0.8631 - val_accuracy: 0.7077
Epoch 4/10
1563/1563 [==============================] - 13s 8ms/step - loss: 0.6694 - accuracy: 0.7649 - val_loss: 0.8990 - val_accuracy: 0.6961
Epoch 5/10
1563/1563 [==============================] - 13s 8ms/step - loss: 0.6294 - accuracy: 0.7802 - val_loss: 0.8842 - val_accuracy: 0.7057
Epoch 6/10
1563/1563 [==============================] - 13s 8ms/step - loss: 0.5848 - accuracy: 0.7946 - val_loss: 0.8962 - val_accuracy: 0.7065
Epoch 7/10
1563/1563 [==============================] - 13s 8ms/step - loss: 0.5490 - accuracy: 0.8067 - val_loss: 0.9036 - val_accuracy: 0.7046
Epoch 8/10
1563/1563 [==============================] - 12s 8ms/step - loss: 0.5108 - accuracy: 0.8191 - val_loss: 0.9041 - val_accuracy: 0.7139
Epoch 9/10
1563/1563 [==============================] - 12s 8ms/step - loss: 0.4794 - accuracy: 0.8306 - val_loss: 0.9870 - val_accuracy: 0.7002
Epoch 10/10
1563/1563 [==============================] - 12s 8ms/step - loss: 0.4395 - accuracy: 0.8441 - val_loss: 1.0093 - val_accuracy: 0.7033
loss, accuracy, 和val_loss的具体定义可以先自己了解一下。下次我会更彻底地解释这些概念。
评估模型
# evaluating the model
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(test_acc)
313/313 - 1s - loss: 1.0093 - accuracy: 0.7033 - 1s/epoch - 4ms/step
0.7033000588417053
可以看出这个模型的准确率有70%,也不是很高。
结论
我们先简单解了一下卷积网络的原理和关键词,然后设计了一个简单的CNN模型。这个模型的正确率挺差的,现在的模型都能得到99%的正确率。以后在了解如何提升我们的模型和研究有名的图像分类模型(AlexNet,Resnet,MobileVNet)。