研发分享 | StoneDB 如何给 Tianmu 引擎增加 delete 功能 #1 调研之旅
❝StoneDB 作为开源项目,一直秉持开源开放的基本原则,我们的社区版代码现在已经完全在 Github 上开源,并不断提高代码的可读友好性,同时,为了让大家更好地理解我们是如何打造一款一体化 HTAP 开源数据库的,我们会定期把一些核心技术的研发实现思路分享给大家,也算是抛砖引玉,如果读者有更好的实现思路,也欢迎与我们沟通,甚至可以参与到我们社区版的开发中~
❞
Tianmu 引擎是 StoneDB 团队自研的一款列式存储引擎,在6月初刚开源时,并不支持 delete 功能,对此很多用户都提出了需求的意见,所以我们当时也把 delete 功能列入到我们的年度 Roadmap 里了,预计在10月20号的 StoneDB_5.7_v1.0.1 正式版本中,上线此功能。第一期,我将分享一下对 delete 功能的调研情况。

前置知识:数据库中删除数据的三种方式
以 Mysql 5.7 为例,数据库删除数据的方式一共有三种:
-
delete
-
truncate
-
drop
以上三种方式都可以删除数据,但是使用场景是不同的。
对于整个表进行删除的执行速度来说:
drop > truncate >> delete
DELETE
delete 是属于数据库的 DML 操作语言,一般是根据条件逐行进行删除。
使用 delete 删除数据时,数据库只能删除数据不能删除表的结构,并且会触发数据库的事务机制。
delete 执行时,会先将所删除数据缓存到 rollback segment 中,事务 commit 之后生效。
在 InnoDB 中,使用 delete 其实并不会真正的把数据删除,是一种逻辑删,数据库底层实际上只是给删除的数据做了一个已删除的标记,因此,删除数据后的表占空间大小和删除前是一样的。
TRUNCATE
truncate 属于数据库 DDL 定义语言,不走事务,原数据不放到 rollback segment 中,操作不触发 trigger。执行后立即生效,无法找回(慎用 删除执行后,数据就没了,不可恢复)。
truncate 删除表会立刻释放磁盘空间。truncate table其实有点类似于drop table 然后 create,只不过这个 create table 的过程做了优化,比如表结构文件之前已经有了等等。所以速度上是接近 drop table 的速度;
DROP
drop 属于数据库 DDL 定义语言,同 truncate ,执行后立即生效,无法找回。
drop table table_name立刻释放磁盘空间 ,drop 语句将删除表的结构、被依赖的约束(constraint)、触发器(trigger)、索引(index); 依赖于该表的存储过程/函数将保留,但是变为 invalid 状态。

Tianmu 引擎对 delete 功能的调研
Tianmu 是一个列式存储引擎,列式存储的出现主要是为了方便快捷查询和高效存储大量同类型的数据而设计的,主要使用场景就是 OLAP。下面是 OLAP场景的部分关键特征:
-
绝大多数是读请求
-
数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
-
已添加到数据库的数据不能修改。
-
对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
-
列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
-
处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
-
事务不是必须的
-
对数据一致性要求低
而 OLAP 场景下,对于数据的 delete 的操作可以说没有或者频率很小。列式存储对比行式存储来说并不擅长数据的增删改,如果是为了极致的查询性能,完全可以舍弃 DML 操作(比如初期的 ClickHouse 也不支持 delete)。但是为了功能的完整性,我们初期就放开了 insert 和 update 的功能,不过没有对 delete 功能进行支持。
随着用户的呼声越来越多,我们开始对各个有列式存储的数据库进行了一个调研,如下表所示:
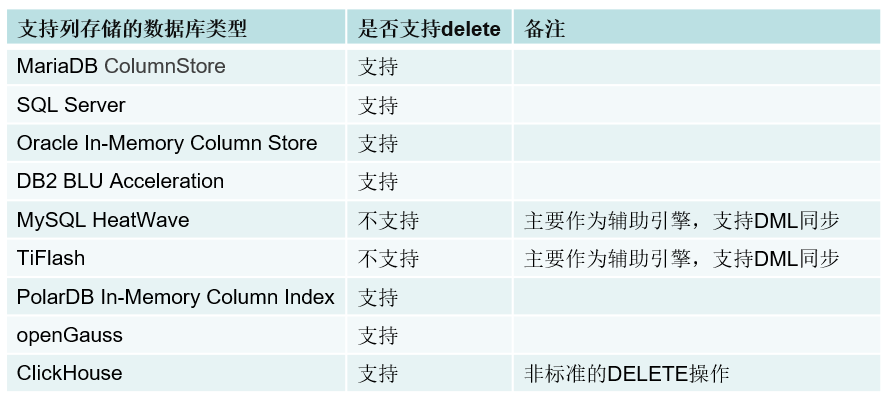
目前行业现状
通过分析目前行业内支持列式存储的主流数据库,大部分都是支持的,就算不支持直接 delete,也是支持 DML 同步的,所以 Tianmu 引擎的 delete 功能确实有必要进行开发支持。

主流列式数据库的 delete 方案
openGauss
存储结构
openGauss 列存储引擎的底层存储结构与 Tianmu 引擎类似 ,存储基本单位是CU(Compression Unit,压缩单元),即表中一列的一部分数据组成的压缩数据块。行存引擎中是以行作为单位来管理,而当使用列存储时,整个表整体被按照不同列划分为若干个 CU。


每个 CU 对应一个 CUDesc 的记录,在 CUDesc 里记录了整个 CU 的事务时间戳信息、CU 的大小、存储位置、magic 校验码、min/max 等信息。

每张列存表还配有张 Delta 表,Delta 表自身为行存储表。当有少量的数据插入到一张列存表时,数据会被暂时放入 Delta 表,等到达阈值或满足一定条件或操作时再行整合为 CU 文件。Delta 表可以避免单点数据操作带来的很重的 CU 操作与开销。
delete 策略
CU 中数据的删除,实际上是标记删除。删除操作,相当于是更新了 CUDesc 表中 CU 对应 CUDesc 记录的 delete bitmap(删除位图)结构,标记列中某行对应数据已被删除,而 CU 文件数据不会被更改。这样可以避免删除操作带来的 IO 放大以及解压、压缩的高额 CPU 开销。这样的设计,也可以使得对于同一个 CU 的 select(查询)和 delete(删除)互不阻塞,提升并发能力。列存储 CU 中数据更新,则是遵循 append-only(仅允许追加)原则的,即 CU 文件仅会向后进行延展扩充,亦或是启用新的 CU 文件,而不是在对应行在 CU 中的位置就地更新。

ClickHouse
存储结构
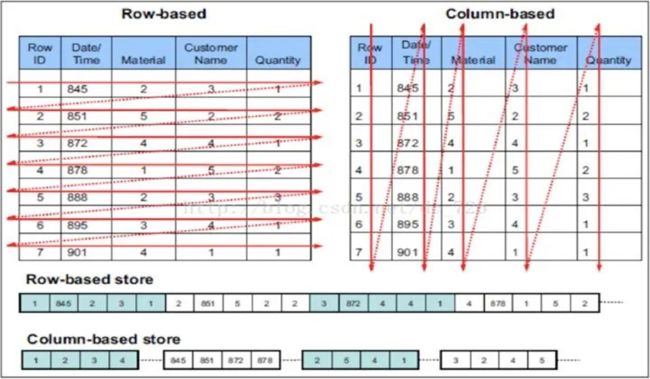
ClickHouse 支持在建表时,指定将数据按照某些列进行 sort by。排序后,保证了相同 sort key 的数据在磁盘上连续存储,且有序摆放。在进行等值、范围查询时,where 条件命中的数据都紧密存储在一个或若干个连续的 Block 中,而不是分散的存储在任意多个 Block, 大幅减少需要 IO 的 block 数量。另外,连续 IO 也能够充分利用操作系统 page cache的预取能力,减少 page fault。
delete 策略
特点:缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据。
ClickHouse是个分析型数据库。OLAP场景下,数据一般是不变的,因此 ClickHouse 对 update、delete 的支持是比较弱的,实际上并不支持标准的 update、delete 操作。
ClickHouse 通过 alter 方式实现更新、删除,它把 update、delete 操作叫做 mutation(突变)。
标准SQL的更新、删除操作是同步的,即客户端要等服务端返回执行结果(通常是int值),而ClickHouse的update、delete是通过异步方式实现的,当执行update语句时,服务端立即返回,但是实际上此时数据还没变,而是排队等着。
Mutation具体过程
首先,使用where条件找到需要修改的分区;然后,重建每个分区,用新的分区替换旧的,分区一旦被替换,就不可回退;对于单独一个分区,是原子性的;但对于整个 mutation,如果涉及多个分区,则不是原子性的。
PolarDB In-Memory Column Index
存储结构
特点:PolarDB 将列存实现为 InnoDB 的二级索引。
在 PolarDB 中所有 Primary Index 和 Secondary Index 都实现为一个 B+Tree。列索引在定义上是一个 Index,但其实是一个虚拟的索引,用于捕获对该索引覆盖列的增删改操作。
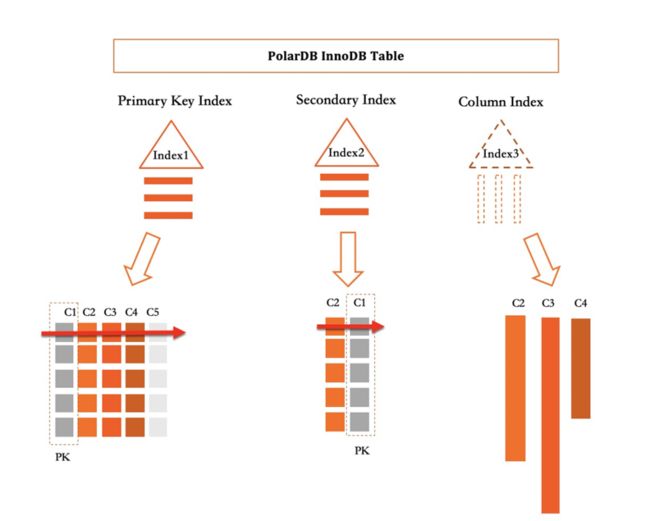
实现为 InnoDB 二级索引方案的优点:
-
查询执行器的工程实现非常简单
-
可以复用 InnoDB 的事务处理框架
-
可以复用 InnoDB 的数据编码格式
-
DDL 语句操作非常灵活
-
可以复用 InnoDB 的 Redo 事务日志模块
-
二级索引与主表有一样的生命周期,方便管理
PolarDB In-Memory Column Index 的存储使用了无序且追加写的格式。
列索引中记录按 RowGroup 进行组织,每个 RowGroup 中不同的列会各自打包形成 DataPack。
每个 RowGroup 都采用追加写,分属每个列的 DataPack 也是采用追加写模式。
对于一个列索引,只有个 Active RowGroup 负责接受新的写入。
当该 RowGroup 写满之后即冻结,其包含的所有 DataPack 会转为压缩格保存到磁盘上,同时记录每个数据块的统计信息便于过滤。
列存 RowGroup 中每新写入一行都会分配一个 RowID 用作定位,属于一行的所有列都可以用该 RowID 计算定位,同时系统维护 PK 到 RowID 的映射索引,以支持后续的删除和修改操作。

delete 策略
在 PolarDB In-Memory Column Index 中,删除操作只需要设置一个删除标记位。更新操作采用标记删除的方式来支持,对于更新操作,首先根据 RowID 计算出其原始位置并设置删除标记,然后在 ActiveRowGroup 中写入新的数据版本。
当一个 RowGroup 中的无效记录超过一定阈值,则会触发后台异步 compaction 操作,其作用一方面是回收空间,另一方面可以让有效数据存储更加紧凑,提升分析型查询的效率。

各列式存储的delete方案汇总
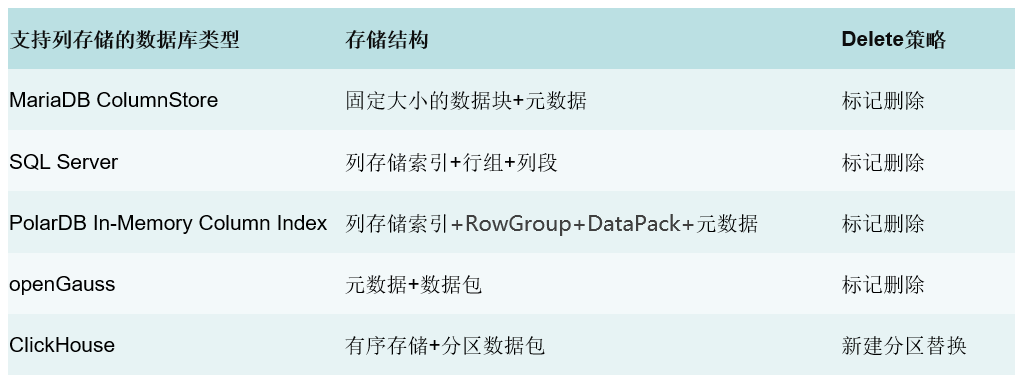
好了,以上就是我对 delete 功能的一个调研情况,下一期我将分享一下,Tinamu 引擎实现 delete 的具体思路。
作者:李红建(空海)
编辑:宇亭
StoneDB 代码已完全在 Github 开源,欢迎关注:
https://github.com/stoneatom/stonedb
StoneDB 官网:
https://stonedb.io/

StoneDB 团队成员与 MySQL 之父 Monty 会面,共话未来数据库形态
爆肝整理5000字!HTAP的关键技术有哪些?| StoneDB学术分享会
解读《Benchmarking Hybrid OLTP&OLAP Database Systems》| StoneDB学术分享会