技术解读 | TuGraph图分析引擎技术剖析
导语
图分析引擎又称图计算框架,主要用来进行复杂图分析,是一种能够全量数据集运行快速循环迭代的技术,适用场景包括社区发现、基因序列预测、重要性排名等,典型算法有PageRank、WCC、BFS、LPA、SSSP。
TuGraph图数据管理平台社区版已于2022年9月在Github开源,本文将对TuGraph图分析引擎的技术进行剖析。
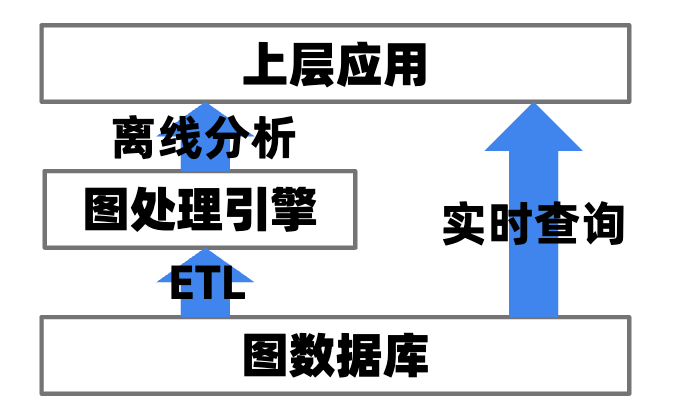
(图1.1 图分析引擎)
1 TuGraph图分析引擎概览
TuGraph的图分析引擎,面向的场景主要是全图/全量数据分析类的任务。借助TuGraph的 C++ 图分析引擎 API ,用户可以对不同数据来源的图数据快速导出一个待处理的复杂子图,然后在该子图上运行诸如BFS、PageRank、LPA、WCC等迭代式图算法,最后根据运行结果做出相应的对策。
在TuGraph中,导出和计算过程均可以通过在内存中并行处理的方式进行加速,从而达到近乎实时的处理分析,和传统方法相比,即避免了数据导出落盘的开销,又能使用紧凑的图数据结构获得计算的理想性能。
根据数据来源及实现不同,可分为Procedure、Embed和Standalone三种运行模式。其中Procedure模式和Embed模式的数据源是图存储中加载图数据,分别适用于Client/Server部署,以及服务端直接调用,后者多用于调试。
Standalone模式的数据源是TXT、二进制、ODPS文件等外部数据源,能够独立于图数据存储直接运行分析算法。

(图1.2 TuGraph图分析引擎模型图)
TuGraph图计算系统社区版内置6个基础算法,商业版内置了共34种算法。涵盖了图结构、社区发现、路径查询、重要性分析、模式挖掘和关联性分析的六大类常用方法,可以满足多种业务场景需要,因此用户几乎不需要自己实现具体的图计算过程。
| 算法类型 |
中文算法名 |
英文算法名 |
程序名 |
| 路径查询 |
广度优先搜索 |
Breadth-First Search |
bfs |
| 单源最短路径 |
Single-Source Shortest Path |
sssp |
|
| 全对最短路径 |
All-Pair Shortest Path |
apsp |
|
| 多源最短路径 |
Multiple-source Shortest Paths |
mssp |
|
| 两点间最短路径 |
Single-Pair Shortest Path |
spsp |
|
| 重要性分析 |
网页排序 |
Pagerank |
pagerank |
| 介数中心度 |
Betweenness Centrality |
bc |
|
| 置信度传播 |
Belief Propagation |
bp |
|
| 距离中心度 |
Closeness Centrality |
clce |
|
| 个性化网页排序 |
Personalized PageRank |
ppr |
|
| 带权重的网页排序 |
Weighted Pagerank Algorithm |
wpagerank |
|
| 信任指数排名 |
Trustrank |
trustrank |
|
| sybil检测算法 |
Sybil Rank |
sybilrank |
|
| 超链接主题搜索 |
Hyperlink-Induced Topic Search |
hits |
|
| 关联性分析 |
平均集聚系数 |
Local Clustering Coefficient |
lcc |
| 共同邻居 |
Common Neighborhood |
cn |
|
| 度数关联度 |
Degree Correlation |
dc |
|
| 杰卡德系数 |
Jaccard Index |
ji |
|
| 图结构 |
直径估计 |
Dimension Estimation |
de |
| K核算法 |
K-core |
kcore |
|
| k阶团计数算法 |
Kcliques |
kcliques |
|
| k阶桁架计数算法 |
Ktruss |
ktruss |
|
| 最大独立集算法 |
Maximal independent set |
mis |
|
| 社区发现 |
弱连通分量 |
Weakly Connected Components |
wcc |
| 标签传播 |
Label Propagation Algorithm |
lpa |
|
| EgoNet算法 |
EgoNet |
en |
|
| 鲁汶社区发现 |
Louvain |
louvain |
|
| 强连通分量 |
Strongly Connected Components |
scc |
|
| 监听标签传播 |
Speaker-listener Label Propagation Algorithm |
slpa |
|
| 莱顿算法 |
Leiden |
leiden |
|
| 带权重的标签传播 |
Weighted Label Propagation Algorithm |
wlpa |
|
| 模式挖掘 |
三角计数 |
Triangle Counting |
triangle |
| 子图匹配算法 |
Subgraph Isomorphism |
subgraph_isomorphism |
|
| 模式匹配算法 |
Motif |
motif |
(表1.1 TuGraph内置算法)
2 功能介绍
2.1 图分析框架
图分析框架作为图分析引擎的“骨架”,可以联合多种模块有效的耦合协同工作。一般分为预处理、算法过程、结果分析三个阶段。
预处理部分用于读入数据及参数进行图构建及相关信息的存储统计,并整理出算法过程所需的参数及数据。
算法过程会根据得到的数据通过特定的算法进行逻辑计算,并得到结果数据。
结果分析部分根据得到的结果数据进行个性化处理(如取最值等),并将重要的信息写回和打印输出操作。
2.2 点边筛选器
点边筛选器作用于图分析引擎中的Procedure和Embed模式。对于图存储数据源可根据用户需要和实际业务场景对图数据进行筛查,选择有效的点边进行图结构的构建。
2.3 一致性快照
TuGraph中的Procedure和Embed模式能够提供数据“快照”,即建立一个对指定数据集的完全可用拷贝,该拷贝包括相应数据在某个时间点(拷贝开始的时间点)的镜像。由于OLAP的操作仅涉及读操作而不涉及写操作,OlapOnDB会以一种更紧凑的方式对数据进行排布,在节省空间的同时,提高数据访问的局部性。
2.4 块状读写模块
块状读写模块作用于图分析引擎中的Standalone模式,用于对不同外部数据源的数据进行高效读入,同时也包含对内部算法处理后的图数据结果写回。
2.5 参数模块
参数模块作用于分析引擎中的Standalone模式,用于对图的一般信息(如数据来源,算法名称,数据输入、输出路径,顶点个数等)以及根据不同数据来源、不同算法所配置的不同信息参数进行接受和整理,传输给图算法及各个模块,同时将最终结果模块化展示。
3 使用示例
由前文所述可知,图分析引擎分为Standalone、Embed和Procedure模式,现在以bfs算法为例分别介绍他们的使用方式。
3.1 Procedure 模式
Procedure模式主要用于Client/Sever的TuGraph运行时,图算法的加载和调用。
在TuGraph/plugins目录下执行 bash make_so.sh bfs 即可在TuGraph/plugins目录下的到bfs.so文件,将该文件以插件形式上传至TuGraph-web,输入参数后即可执行。
示例:
在TuGraph/plugins编译.so算法文件
`bash make_so.sh bfs`
将bfs.so文件以插件形式加载至TuGraph-web后,输入如下json参数:

即可得到返回结果。
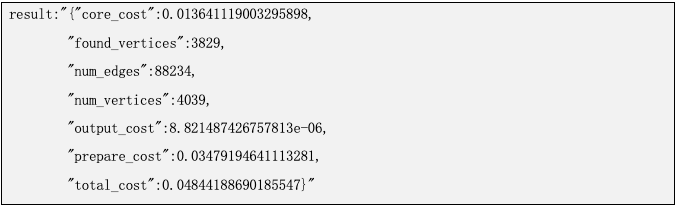
输出内容解释:
-
num_edges: 表示该图数据的边数量
-
num_vertices: 表示该图数据顶点的数量
-
prepare_cost: 表示预处理阶段所需要的时间。预处理阶段的工作:加载参数、图数据加载、索引初始化等。
-
core_cost: 表示算法运行所需要的时间。
-
found_vertices: 表示查找到顶点的个数。
-
output_cost: 表示算法结果写回db所需要的时间。
-
total_cost: 表示执行该算法整体运行时间。
3.2 Embed 模式
该种方式主要用于TuGraph在后台程序中对预加载的图存储数据进行算法分析,多用于快速调试。在TuGraph/plugins目录下对embed_main.cpp文件完善,补充数据名称、输入参数、数据路径等信息,示例如下:

保存后在TuGraph/plugins目录下执行 bash make_so.sh bfs 即可在TuGraph/plugins/cpp目录下的到bfs_procedure文件,bash make_embed.sh bfs
在TuGraph/plugins文件夹下执行./cpp/bfs_procedure即可得到返回结果。

3.3 Standalone 模式
Standalone模式可以独立于图存储运行,直接从文本文件或ODPS读取Edgelist形式的图数据。在TuGraph/build目录下执行 make bfs_standalone 即可得到bfs_standalone文件,该文件生成与TuGraph/build/output/algo文件夹下。运行:在TuGraph/build目录下执行./output/algo/bfs_standalone -–type [type] –-input_dir [input_dir] -–vertices [vertices] --root [root] –-output_dir [output_dir]
-
[type]:表示输入图文件的类型来源,包含text文本文件、BINARY_FILE二进制文件和ODPS源。
-
[input_dir]:表示输入图文件的文件夹路径,文件夹下可包含一个或多个输入文件。TuGraph在读取输入文件时会读取[input_dir]下的所有文件,要求[input_dir]下只能包含输入文件,不能包含其它文件。参数不可省略。
-
[vertices]:表示图的顶点个数,为0时表示用户希望系统自动识别顶点数量;为非零值时表示用户希望自定义顶点个数,要求用户自定义顶点个数需大于最大的顶点ID。参数可省略,默认值为0。
-
[root]:表示进行bfs的起始顶点id。参数不可省略。
-
[output_dir]:表示输出数据保存的文件夹路径,将输出内容保存至该文件中,参数不可省略。
示例:在TuGraph/build编译standalone算法程序

在TuGraph/build/output目录下运行text源文件

得到运行结果:

结果参数解释同上。
4 小结
综上,图分析引擎可以高效、快速的处理多种来源的数据,其并行的图构建方式保证了内存占用小的特点。此外,图分析引擎也具有易于安装部署、灵活性高、耦合程度低、易于上手等对用户友好特性,可以帮助用户结合具体业务解决问题。
访问 GitHub:
https://github.com/TuGraph-db