上篇文章简单的学习了tesseract-ocr识别图片中的英文(链接地址如下:https://www.cnblogs.com/wj-1314/p/9428909.html),看起来效果还不错,所以这篇文章继续深入学习tesseract-ocr识别图片中的中文。
一,准备中文字库
下载chi_sim.traindata字库。要有这个才能识别中文。下好后,放到Tesseract-OCR项目的tessdata文件夹里面。(注意下载字库,一定要看库对应的tesseract版本下载)
为什么强调版本呢 ,小编这里讲自己做的愚蠢的事情附上,希望大家别入坑了。
上一篇学习Tesseract-ocr中,识别的是英文,然后小编下载了中文库,如下
不知道是什么原因,总是报错。报错如下:
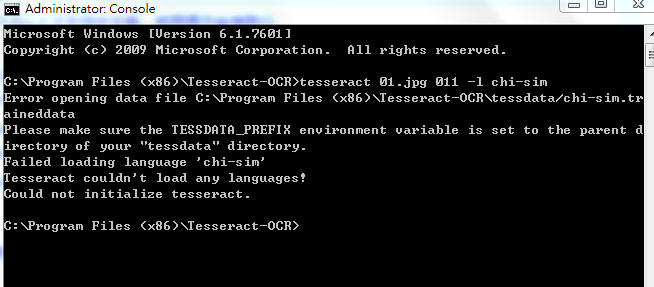
我找了多种方法,包括重新安装库,配置环境变量,仍然没有解决问题,所以在这里,我又考虑到Tesseract的版本问题,所以打算重新最新版 w64-v4.0.0,继续试试。附上下载链接地址
下载Tesseract的地址:https://digi.bib.uni-mannheim.de/tesseract/
下载Tesseract-ocr包的地址:https://github.com/tesseract-ocr/tesseract/wiki/Data-Files
下载Tesseract的Git地址:https://github.com/tesseract-ocr/tesseract/wiki
经过一天的折腾,在tesseract的GitHub中,我偶然发现了问题的所在,可以说自己是非常的蠢,请看下图
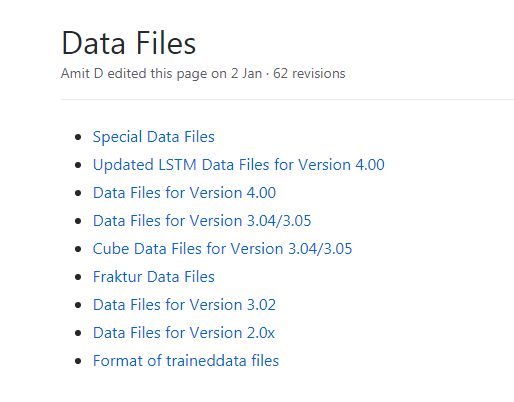
也就是不同的版本,安装的中文包是不同的,而我乱安装了包,所以一直报错,还没有解决问题,下次一定不能这么粗心。
二,准备训练字库
下载jTessBoxEditor,这个是用来训练字库的。
![]()
以上的在百度都能找到下载,就不详细讲了(要是找不到的,可以留言给我),下载好之后就是这样的。
三,下载Java虚拟机(Java大法好啊)
如果你刚刚接触Java语言,并且对它兴趣很大,想继续研究。那么这节就来给你说说怎么安装Java工具JDK,它是你进行Java的第一步。
首先你要下载Java的JDK(JDK的全称是:Java Development Kit即Java语言软件工具开发包),目前最新的JDK版本是1.8,Java最初是SUN公司,因后来被oracle公司收购,故你需要到oracle官网上下载JDK网址是:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html。输入这个网址你就可以看到下面图片
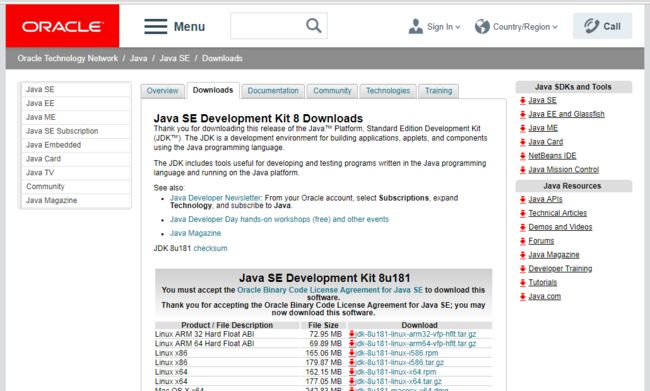
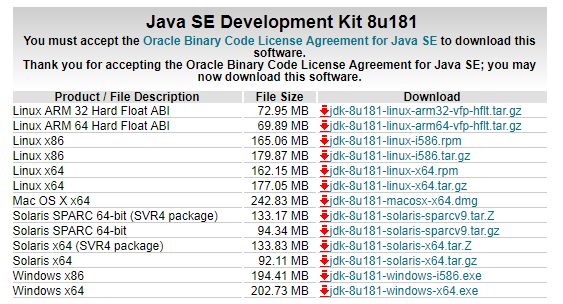
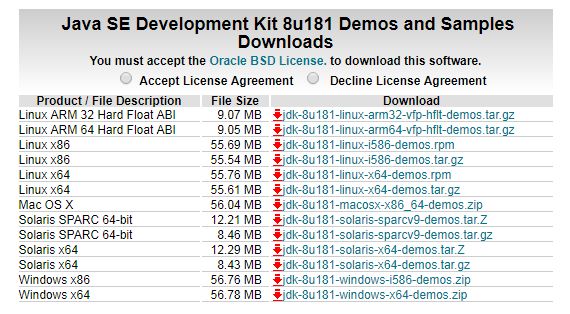
其中图片中现实的上面是oracle公司提供的Java JDK,上面有两个按钮,默认是不接受License,你需要接受以后就可以下载Java的JDK,这里你需要根据自己电脑的类型,以及操作系统的位数,下载对应的JDK。下面的一个是oracle公司对JDK提供的demos和Samples即简单的例子,可以供我们学习,感兴趣的可以下载下来学习。
这里我选择下载JDK的Windows的64位JDK,下面图片是下载的JDK的安装包。
![]()
双击JDK安装包,点击下一步。
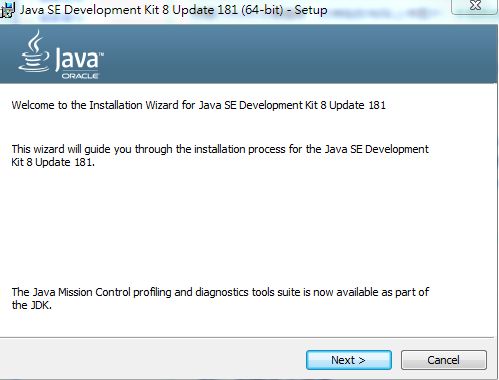
这里选择不安装公共JRE,因为公共JRE是一个独立的JRE系统,它是单独的安装在windows系统下的其他路径下。公用的JRE会向浏览器和系统中注册Java运行时的环境。通过向浏览器和系统中注册运行时的环境,系统中的任何应用程序都可以使用公用JRE。但是现在在浏览器网页上执行applet的机会几乎没有,并且JDK目录下JRE完全可以胜任,所以一般选择不安装公用JRE。这里如果你不想安装在默认路径下,可以选择更改目录。
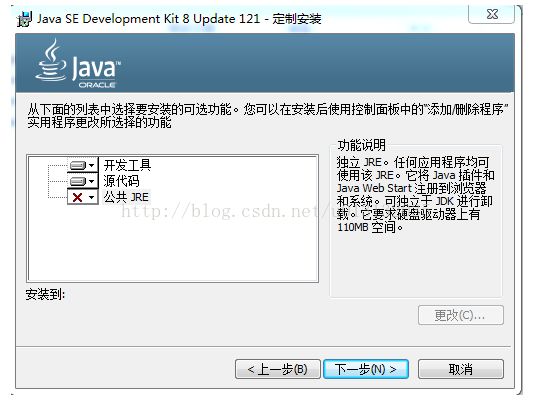
单击下一步,会出现如下安装条。
输入Java -version可以查看自己的Java版本。这样你的JDK就安装成功了。

四,识别中文效果
1,随便制作一张有汉字的图片,小编做的图片如下:

2,使用中文字库训练,程序如下:
import pytesseract
from PIL import Image
#打开验证码图片
image = Image.open('07.jpg')
#加载一下图片防止报错,此处可以省略
image.load()
#调用show来展示图片,调试用此处可以省略
image.show()
text = pytesseract.image_to_string(Image.open('07.jpg'),lang ='chi_sim')
print(text)
3,使用中文字库训练的结果如下:

从结果来看,效果不太理想,所以我们要想得到更好的结果,那么就需要训练自己的字库,下面小编开始训练自己的字库。
五,训练自己的文库
1、将图片转换成tif格式,用于后面生成box文件。可以通过画图,然后另存为tif即可
更改图片名字,这个是有要求的
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库myfontlab 字体名normal
那么我们把图片文件重命名 myfontlab.normal.exp0.jpg在转tif。
2、生成box文件
tesseract myfontlab.normal.exp0.jpg myfontlab.normal.exp0 -l chi_sim batch.nochop makebox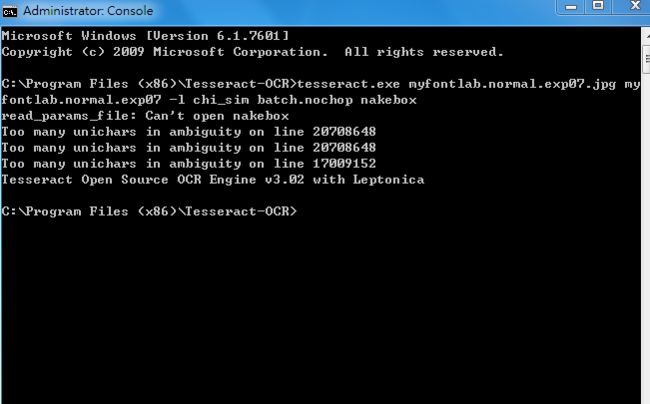
box文件和对应的tif一定要在相同的目录下,不然后面打不开。

3、打开jTessBoxEditor矫正错误并训练
打开train.bat
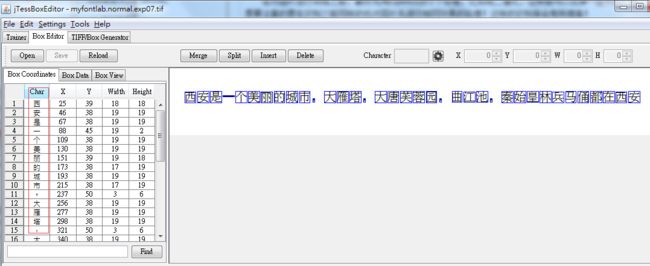
用jTessBoxEditor.jar打开tif文件,然后根据实际情况修改box文件
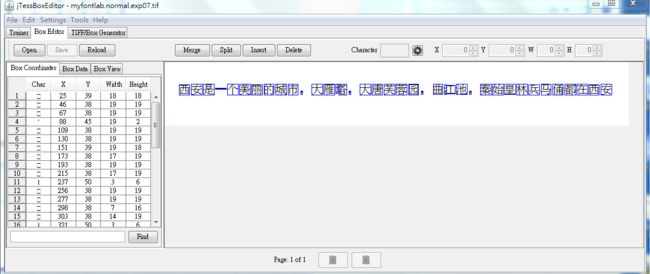
找到tif图,打开,并校正。
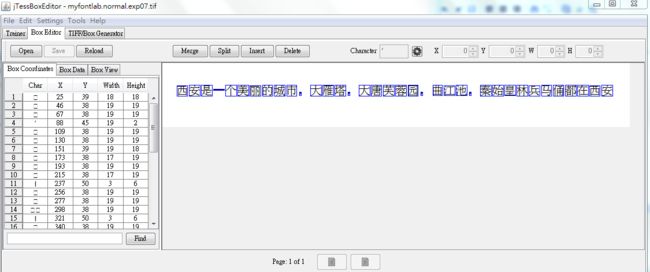
4、训练,生成.tr文件。
只要在命令行输入命令即可。
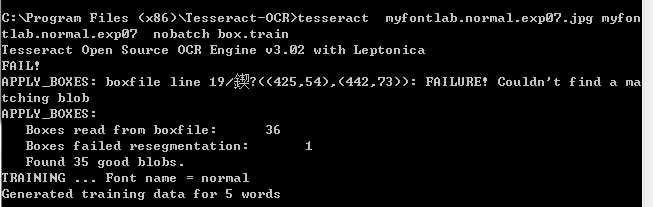
tesseract myfontlab.normal.exp07.jpg myfontlab.normal.exp07 nobatch box.train
生成一个unicharset文件
unicharset_extractor myfontlab.normal.exp07.box

在这我明明已经矫正好了,但是还是有1个字符不能识别出来,报的错跟实际上完全没有相关性,不知道是不是bug,到后面的结果就是“一”字没有识别出来。
5,新建一个font_properties文件
里面内容写入 normal 0 0 0 0 0 表示默认普通字体
![]()
运行命令
shapeclustering -F font_properties.txt -U unicharset myfontlab.normal.exp07.tr
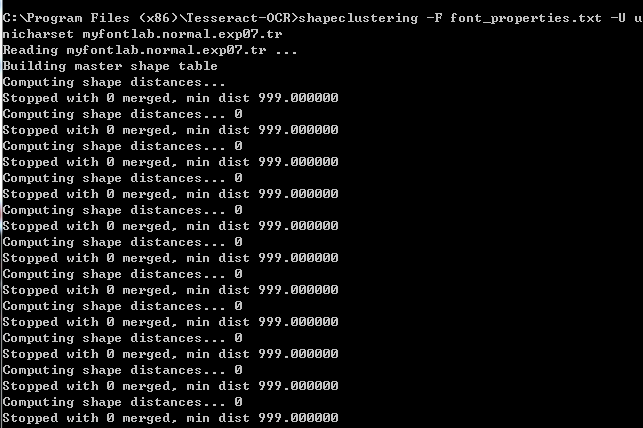
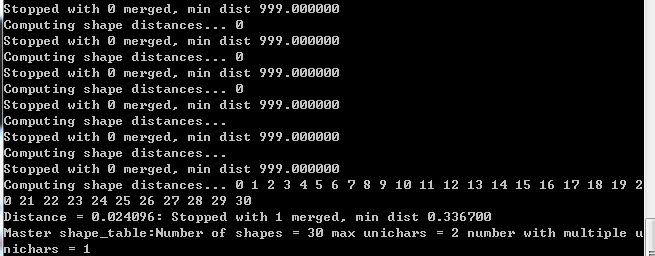
mftraining -F font_properties.txt -U unicharset -O unicharset myfontlab.normal.exp07.tr

cntraining myfontlab.normal.exp07.tr

目录下会生成对应下列五个文件,在这五个文件前加上normal.进行重命名
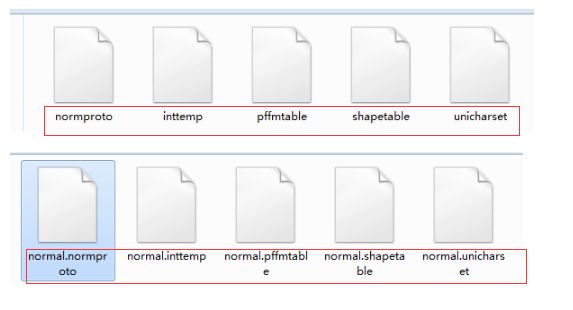
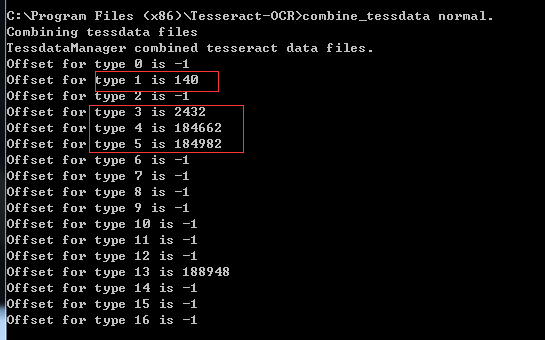
6 执行 combine_tessdata normal.
合并五个文件,此时目录下的normal.traineddata 就是训练好的字库文件
combine_tessdata normal.
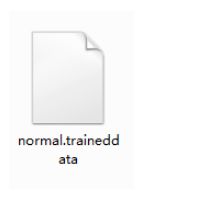
得到训练好的字库如下:
六 测试字库
1,把normal.traineddata 复制到Tesseract-OCRt程序目录下的“tessdata”目录,
2,在Tesseract-OCRt程序目录下执行
tesseract.exe myfontlab.normal.exp07.jpg out –l normal


下面文件中会保存你识别到的数据;
这个其实网上资料很多,但大都描述的不够详细和完整,这里我一步一步把使用tesseract-ocr 训练字库的方法和步骤进行了描述,亲测是没有问题。

七,如何通过jTessBoxEditor进行Tesseract3.02.02样本训练
Tesseract生成.box文件后,需要用到jTessBoxEditor工具对其进行纠正,以下是jTessBoxEditor的使用步骤。
1 加载要纠正的.tif文件
box文件的内容也同时会加载到jTessBoxEditor,如果这部分的内容为空,则是没有生成.box文件的!如下图:
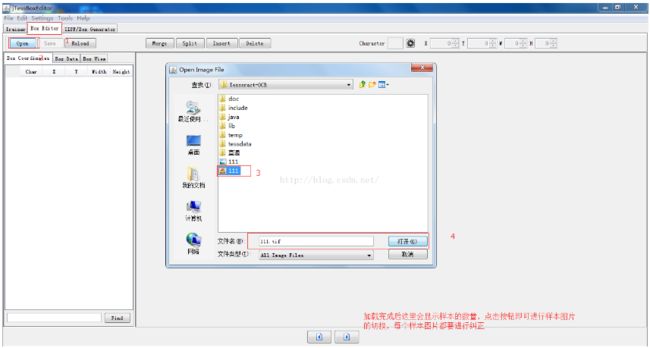
2 加载步骤如下:
此处借用的是网友的图片,方便,如有侵权,请联系小编及时删除。
3 矫正文字
当一个字被识别为两个时,按住Ctrl键选中两个,然后点击Merge,即可进行合并!
进行矫正 主要就是坐标 位置的调整,注意 添加需要选择上一个文字才能分离
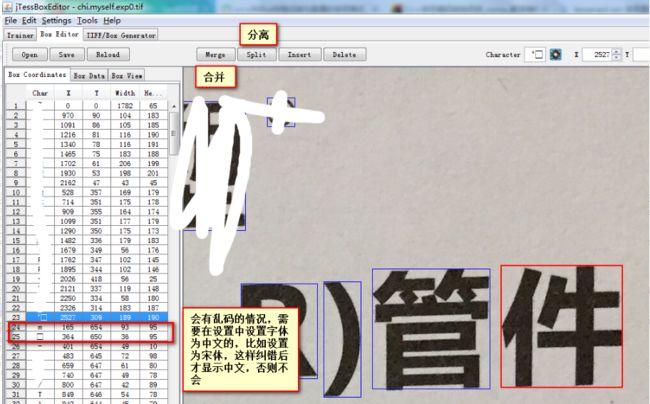
4.删除空白的方法
有些空白处可能也会被jTessBoxEditor误认为是字体,用蓝色框框住,
这个可以直接选中,delete掉就好了!

5.总结
正常情况下是每个字体都会有蓝色框框住,如果说有其中的两个相邻的字都没有被框住,这时候即使采用insert后加上蓝色框,但是最后识别还是有问题,这个不懂是不是我操作不对! 最后发现原来是两个字体挨的太近的,导致区别不开了,在老大的建议下,把两个字的距离隔开点来,就可以正常的框出来了!(如果有更好的方法,请指出,谢谢)
修改完成后保存即可!这里我是一张张样本图片进行修改的,但是我这样做每张都有做同样的纠正,不知道有没有批量修改的方法呢?
在对图片进行训练之前,最好先用Opencv进行下处理,比如说二值化,这样就可以去掉一些干扰!但是要注意的是在识别之前同样的也对图片先进行相同效果的处理!这样的识别率会有所提高!
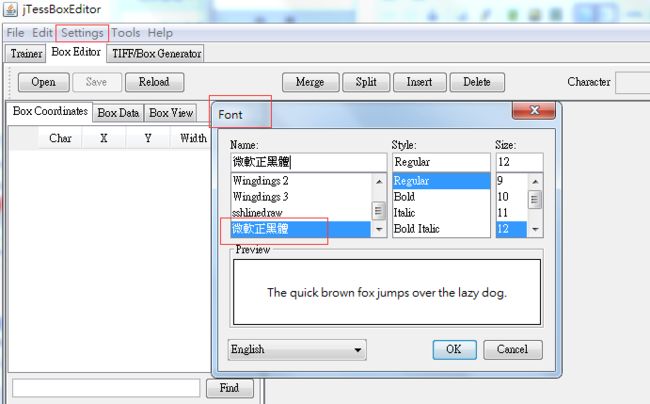
八 软件设置字体的方法
在setting>font 设置中文字体