吴恩达神经网络和深度学习课程自学笔记(十一)之目标检测
目标检测
一、目标定位
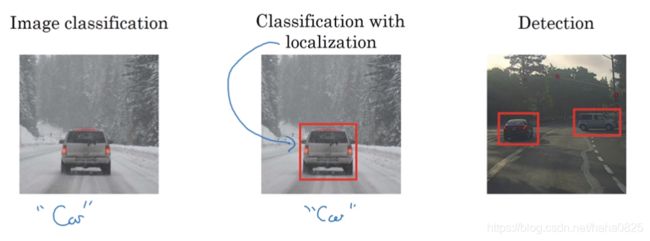
不仅是识别出汽车,还要判断他的在图中的具体位置。

一个输入图片,我们先通过卷积判断了它是汽车,而要定位,我们可以让神经网络多输出几个单元,输出一个边界框,也就是4个数字(bx,by,bh,bw),即被检测对象的参数化表示。
约定一些符号表示:
左上角坐标为(0,0),右下角为(1,1 ),物体中心点坐标为(bx,by),边框高度为bh,宽度为bw。
(本例子中,bx=0.5,by=0.7,bh=0.3,bw=0.4)

假设有四个分类,分别为:行人、汽车、摩托车、背景(没有移动的物体),神经网络输出的是bx,by,bh,bw和标签(或者是标签的概率)。而目标函数为:
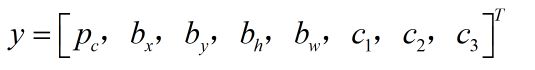
pc代表图中是否有目标(行人/汽车/摩托车),若有则值为1,否则为0;c1/c2/c3代表行人/汽车/摩托车这3个标签,是哪个哪个值为1,其他两个为0.(我们假设图片中最多只有一个对象出现)。
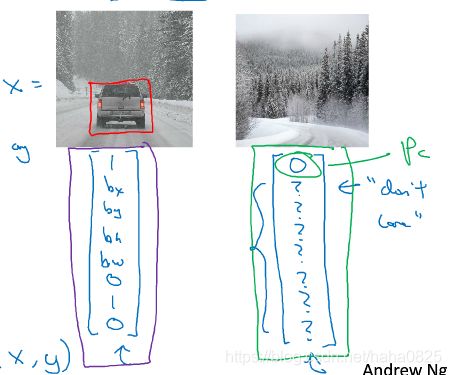
左图中有汽车,则
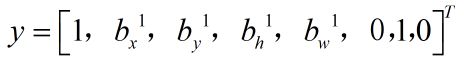
右图这三个目标都没有,所以
![]()
损失函数为:

二、特征点检测
2.1人脸识别
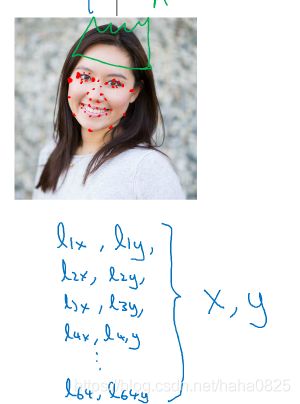
想检测眼角的位置,我们可以让神经网络的最后一层,多输出2个坐标值Lx和Ly作为眼角的坐标值。同理,其他特征点也可以这样,即L1x,L1y;
L2x,L2y;L3x,L3y;L4x,L4y 。这样4个脸特征点位置可以通过神经网络输出了。
我们假设人脸部有64个特征点,识别人脸具体做法如下:
一个卷积网络和一些特征值,人脸图片输入卷积网络,输出(x,64个特征点)(x代表是否有人脸,有人脸值为1,否则为0),接着全连接层展开为64×2+1=129个单元,接着识别人脸,通过softmax函数输出标签。
2.2 人体姿态检测

可以定义一些关键特征点,如胸部的中心,右肩,左肘,腰等,通过神经网络标注人物姿态的关键特征点再进行输出,这就得到了人物的姿态动作。
需要注意的一点是,特征点在每个图片中要保持一致,例如第一张图片特征点1是眼睛,在其他图片中特征点1也必须是眼睛,随意更改会变得非常混乱。
三、目标检测
采用的是基于滑动窗口的目标检测算法。
假设构建汽车目标检测:

训练集使用适当裁剪的图片(使汽车位于图像中间并布满图像)。
目标检测算法具体如下:

首先选择一个窗口,然后将这框中的图像输入卷积网络,然后网络会判断有没有车,接下来往右走处理第二个图像,判断有没有车,依次这样处理第三个,第四个…直到窗口滑过图像的每一个角落。

即以固定步幅滑动窗口,遍历图像的每个区域,把这些裁剪后的小图像输入卷积网络,对每个位置按“0”或“1”进行分类,接着选择更大的窗口进行同样的操作。

这样做不论汽车在什么位置总会被窗口检测到。
这个算法也有明显的缺点,也就是计算成本比较大。选择的窗口小导致窗口数多,计算量大,但是窗口太大会影响性能。
四、卷积的滑动窗口实现
4.1 把全连接层转化为卷积层
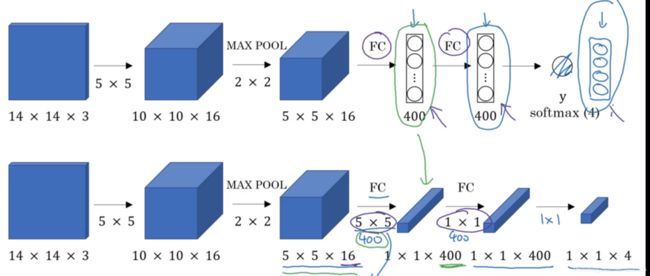
将softmax层改为4个输出,即4个种类的概率。第一个全连接层用400个5×5过滤器实现,输出1×1×400的图像,即不把它看作是一个含有400节点的集合而是一个1×1×400的输出层。接着用400个1×1卷积处理得到一个1×1×400的输出,接着通过softmax输出4个标签。
4.2 通过卷积实现滑动窗口目标检测算法
借鉴了下面这个论文
![]()

最初是在14×14×3添加像素使之成为16×16×3,然后分别截取左上、右上、左下、右下四部分,实际上这四个卷积有很多计算都是共享的。

移动步长较小的情况。
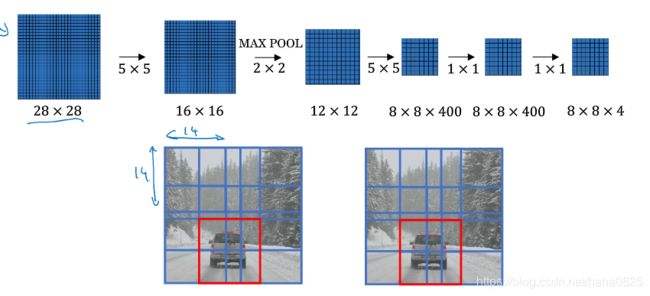
最终仍有缺点:边界框的位置不够准确,不能保证很好的使汽车完整的在窗口中。
五、边界框预测(更精准的边界框)
使用的是YOLO算法,基本思路是:使用图像分类和定位算法,逐一应用在9个框中,对9个格子中的每一个指定一个标签。

这个图中有2个目标,取两个目标的中点,然后将这个目标分配给包含对象中点的格子。即使有一个占据了2个框,也是按中点那个框算。
对每个框都会得到一个8维输出向量,目标输出为3×3×8.
优点在于神经网络可以输出精确的边框,缺点是仅适用于一个框中最多只有一个目标的情况。
这个算法类似于前面的图像定位,输出框的坐标的,并且可以有任意的宽高比,所以能输出更精确的坐标,而不受滑动窗口步长大小的限制。
其次,这是一个卷积运算,在处理3×3计算中很多步骤是共享的,效率较高。
YOLO实际上运行速度很快,可以达到实时识别。
而如何编码bx,by,bh,bw?
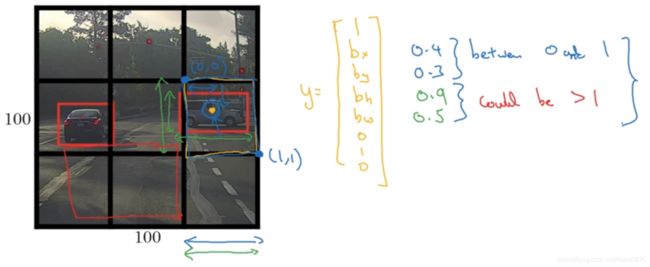
bx,by,bh,bw是相对格子尺度的比例。bx,by在0和1之间,bh,bw可能大于1.通常sigmoid函数确保bx,by位于0与1之间;指数函数确保bh,bw为非负数。
六、交并比(IOU)
判断目标检测算法运作效果。

交并比函数做的是计算两个边界框交集的并集的比值。即图中:黄色区域大小/绿色区域大小。
一般约定IOU大于或等于0.5说检测正确。IOU越高,边界越准确。0.5为人为约定,并无理论基础,所以想更严格可以设为0.6或0.7甚至更高。
七、非最大值抑制
前面介绍的一般都是对同一目标检测多次,而最大值抑制确保算法对每个目标只检测一次。
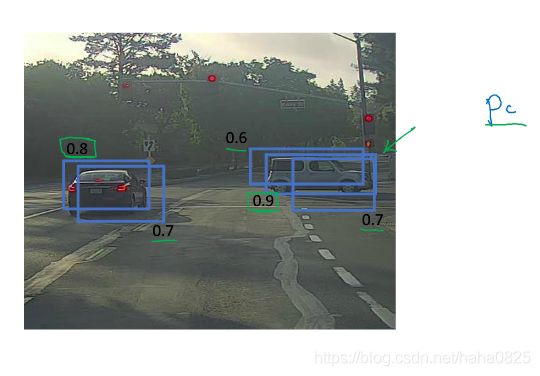
假设有19×19个框,在检测时,每个框被检测多次,非最大值抑制所做的是清除多余的,
具体如下:
首先查看每个检测结果相关的概率Pc(即框中有车的概率),找出最大的那个,接着搜寻所有和这个框有很高交并比的,即高重叠的框,然后将这些框抑制(去掉),最后留下的就是要找的边界框。
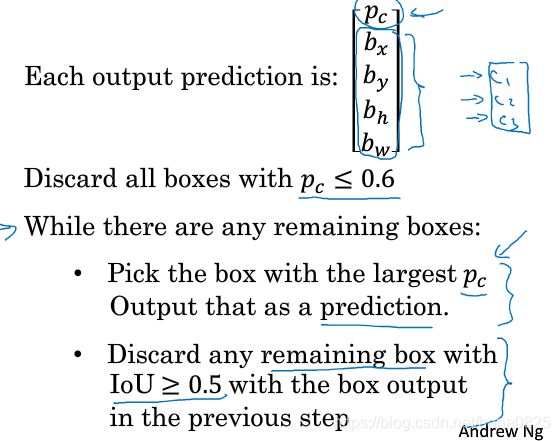
细节:
每个输出预测为:
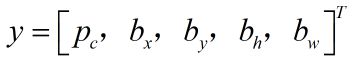
没有c1,c2,c3,假设只检测车。
接着抛弃所有Pc小于等于0.6的边界框。
然后在while循环中:
在剩下的框中选择Pc最高的那个,把他预测为输出,去掉剩余的所有IOU大于等于0.5的框,直到所有的框被判断过,while循环结束。
若还同时检测行人和摩托车,则对每个分类都做一遍非最大值抑制。
八、Anchor Boxes
现在为止,介绍的都是每个格子只能检测出一个对象。同一个框内有2个目标就不适用了。Anchor Boxes就是解决这个问题。
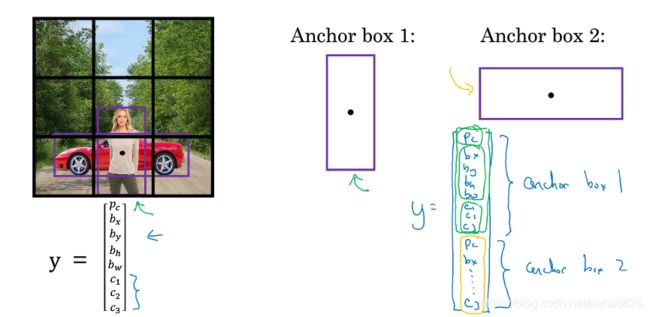
行人和汽车中点几乎在同一个地方,两者在同一个格子内。
思路:
预先定义两个不同形状的anchor box,把预测结果和anchor box关联起来。
![]()
前半部分用于anchor box1,形状匹配了行人,用于识别行人;后半部分用于anchor box2,形状匹配了汽车,用于识别汽车。
总结:
以前的:训练集中的每个目标,根据中点分配框,输出3×3×8;
现在的:除上面的操作外,他还分配一个和目标形状交并比最高的anchor box,输出是3×3×8×2(2个anchor box)。
下面看一个具体的例子:
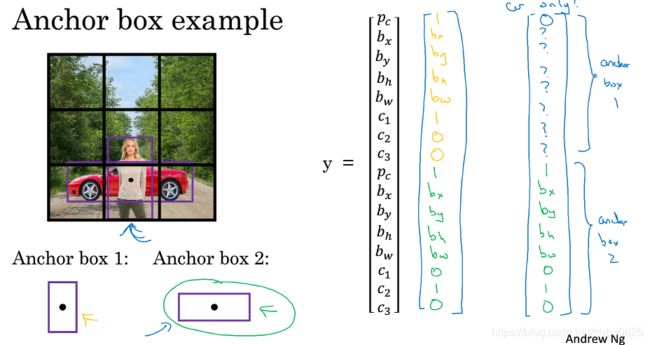
anchor box1—>行人,anchor box2—>汽车
图中有人有汽车,则

若图中只有汽车,人走了,则

不适用于:
1)图中有三个目标
2)图中有两个目标,但是他们的anchor box形状一样或相似
不过实践中以上两个情况很少见,特别是在用19×19的框的情况下。
这样做可以使我们的学习更有针对性(anchor box的形状可以自己设置),很瘦的人或者比较宽的车子。
一般都是手工设定形状,但是有更好的方法,使用k-means算法,可以将两类目标形状聚类,选择最具代表性的形状。
九、YOLO算法
9.1 构建训练
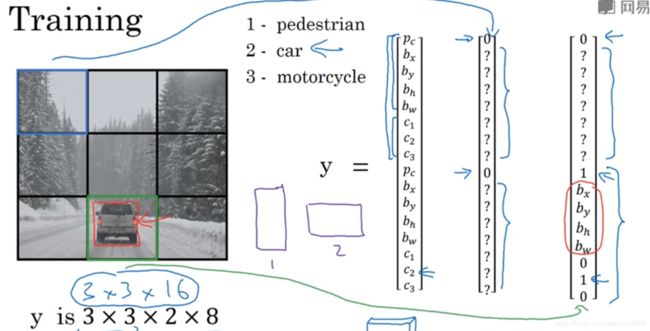
遍历9个格子,然后构成对应的目标向量y:
第1个

第8个
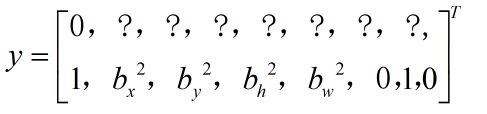
输出是3×3×2×8,分别是框数、anchor box数、参数数量。
9.2 做训练
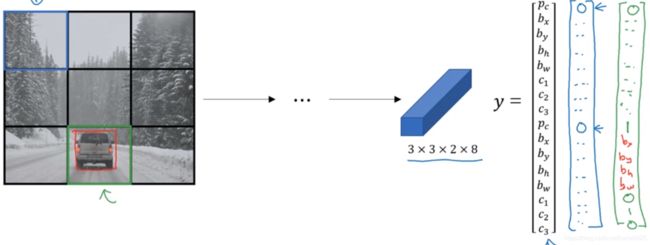
输入图像—>…–>3×3×2×8
对于无车的框,输出Pc=0,其他的随便一个数字,无关紧要;
有车的框,anchor box1参数为0,其他一些无关紧要的数字,anchor box2参数为1,以及一些参数的值。
9.3 非最大值抑制

十、候选区域(RPN网络)
带区域的卷积网络

有一些滑动窗口的框中啥也没有,而R-CNN尝试选出一些区域,在这些区域下运行卷积是有意义的。即不对所有窗口而是选择一些窗口运行卷积网络分类。

选出候选区域的方法是运行图像分割算法,找到一些色块并在上面跑卷积分类,看看有没有东西,是什么东西,有东西就输出边界框以及标签。
这样可以减少在一些框上运行卷积从而减少总体的运算时间。

R-CNN一个缺点,虽然减少了运算,但还是很慢。接着就有一个改进:Fast-RCNN,用卷积实现滑动窗口法。而Fast-RCNN也有一个缺点:得到候选区域的聚类步骤仍然很慢。于是又有了个Faster-RCNN,使用卷积网络而不是图像分割去选出候选区域。
这些都是两步:选出候选区域—>处理,而YOLO(you only look once)一步到位,更快。