Java实现C4.5决策树
1.定义数据结构
根据决策树的形状,我将决策树的数据结构定义如下。lastFeatureValue表示经过某个特征值的筛选到达的节点,featureName表示答案或者信息增益最大的特征。childrenNodeList表示经过这个特征的若干个值分类后得到的几个节点。
public class Node
{
/**
* 到达此节点的特征值
*/
public String lastFeatureValue;
/**
* 此节点的特征名称或答案
*/
public String featureName;
/**
* 此节点的分类子节点
*/
public List childrenNodeList = new ArrayList();
} 2.定义输入数据格式
@feature
outlook,temperature,humidity,windy,play
@data
sunny,hot,high,FALSE,no
sunny,hot,high,TRUE,no
overcast,hot,high,FALSE,yes
rainy,mild,high,FALSE,yes
rainy,cool,normal,FALSE,yes
rainy,cool,normal,TRUE,no
overcast,cool,normal,TRUE,yes
sunny,mild,high,FALSE,no
sunny,cool,normal,FALSE,yes
rainy,mild,normal,FALSE,yes
sunny,mild,normal,TRUE,yes
overcast,mild,high,TRUE,yes
overcast,hot,normal,FALSE,yes
rainy,mild,high,TRUE,no3.存储输入数据
在代码中,特征和特征值用List来存储,数据用Map来存储。
//特征列表
public static List featureList = new ArrayList();
// 特征值列表
public static List> featureValueTableList = new ArrayList>();
//得到全局数据
public static Map> tableMap = new HashMap>(); 4.初始化输入数据
/**
* 初始化数据
*
* @param file
*/
public static void readOriginalData(File file)
{
int index = 0;
try
{
FileReader fr = new FileReader(file);
BufferedReader br = new BufferedReader(fr);
String line;
while ((line = br.readLine()) != null)
{
// 得到特征名称
if (line.startsWith("@feature"))
{
line = br.readLine();
String[] row = line.split(",");
for (String s : row)
{
featureList.add(s.trim());
}
}
else if (line.startsWith("@data"))
{
while ((line = br.readLine()) != null)
{
if (line.equals(""))
{
continue;
}
String[] row = line.split(",");
if (row.length != featureList.size())
{
throw new Exception("列表数据和特征数目不一致");
}
List tempList = new ArrayList();
for (String s : row)
{
if (s.trim().equals(""))
{
throw new Exception("列表数据不能为空");
}
tempList.add(s.trim());
}
tableMap.put(index++, tempList);
}
// 遍历tableMap得到属性值列表
Map> valueSetMap = new HashMap>();
for (int i = 0; i < featureList.size(); i++)
{
valueSetMap.put(i, new HashSet());
}
for (Map.Entry> entry : tableMap.entrySet())
{
List dataList = entry.getValue();
for (int i = 0; i < dataList.size(); i++)
{
valueSetMap.get(i).add(dataList.get(i));
}
}
for (Map.Entry> entry : valueSetMap.entrySet())
{
List valueList = new ArrayList();
for (String s : entry.getValue())
{
valueList.add(s);
}
featureValueTableList.add(valueList);
}
}
else
{
continue;
}
}
br.close();
}
catch (IOException e1)
{
e1.printStackTrace();
}
catch (Exception e)
{
e.printStackTrace();
}
} 5.计算给定数据集的香农熵
/**
* 计算熵
*
* @param dataSetList
* @return
*/
public static double calculateEntropy(List dataSetList)
{
if (dataSetList == null || dataSetList.size() <= 0)
{
return 0;
}
// 得到结果
int resultIndex = tableMap.get(dataSetList.get(0)).size() - 1;
Map valueMap = new HashMap();
for (Integer id : dataSetList)
{
String value = tableMap.get(id).get(resultIndex);
Integer num = valueMap.get(value);
if (num == null || num == 0)
{
num = 0;
}
valueMap.put(value, num + 1);
}
double entropy = 0;
for (Map.Entry entry : valueMap.entrySet())
{
double prob = entry.getValue() * 1.0 / dataSetList.size();
entropy -= prob * Math.log10(prob) / Math.log10(2);
}
return entropy;
} 6.按照给定特征划分数据集
/**
* 对一个数据集进行划分
*
* @param dataSetList
* 待划分的数据集
* @param featureIndex
* 第几个特征(特征下标,从0开始)
* @param value
* 得到某个特征值的数据集
* @return
*/
public static List splitDataSet(List dataSetList, int featureIndex, String value)
{
List resultList = new ArrayList();
for (Integer id : dataSetList)
{
if (tableMap.get(id).get(featureIndex).equals(value))
{
resultList.add(id);
}
}
return resultList;
} 7.选择最好的数据集划分方式
/**
* 在指定的几个特征中选择一个最佳特征(信息增益最大)用于划分数据集
*
* @param dataSetList
* @return 返回最佳特征的下标
*/
public static int chooseBestFeatureToSplit(List dataSetList, List featureIndexList)
{
double baseEntropy = calculateEntropy(dataSetList);
double bestInformationGain = 0;
int bestFeature = -1;
// 循环遍历所有特征
for (int temp = 0; temp < featureIndexList.size() - 1; temp++)
{
int i = featureIndexList.get(temp);
// 得到特征集合
List featureValueList = new ArrayList();
for (Integer id : dataSetList)
{
String value = tableMap.get(id).get(i);
featureValueList.add(value);
}
Set featureValueSet = new HashSet();
featureValueSet.addAll(featureValueList);
// 得到此分类下的熵
double newEntropy = 0;
for (String featureValue : featureValueSet)
{
List subDataSetList = splitDataSet(dataSetList, i, featureValue);
double probability = subDataSetList.size() * 1.0 / dataSetList.size();
newEntropy += probability * calculateEntropy(subDataSetList);
}
// 得到信息增益
double informationGain = baseEntropy - newEntropy;
// 得到信息增益最大的特征下标
if (informationGain > bestInformationGain)
{
bestInformationGain = informationGain;
bestFeature = temp;
}
}
return bestFeature;
} 8.多数表决不确定结果
/**
* 多数表决得到出现次数最多的那个值
*
* @param dataSetList
* @return
*/
public static String majorityVote(List dataSetList)
{
// 得到结果
int resultIndex = tableMap.get(dataSetList.get(0)).size() - 1;
Map valueMap = new HashMap();
for (Integer id : dataSetList)
{
String value = tableMap.get(id).get(resultIndex);
Integer num = valueMap.get(value);
if (num == null || num == 0)
{
num = 0;
}
valueMap.put(value, num + 1);
}
int maxNum = 0;
String value = "";
for (Map.Entry entry : valueMap.entrySet())
{
if (entry.getValue() > maxNum)
{
maxNum = entry.getValue();
value = entry.getKey();
}
}
return value;
} 9.创建决策树
/**
* 创建决策树
*
* @param dataSetList
* 数据集
* @param featureIndexList
* 可用的特征列表
* @param lastFeatureValue
* 到达此节点的上一个特征值
* @return
*/
public static Node createDecisionTree(List dataSetList, List featureIndexList, String lastFeatureValue)
{
// 如果只有一个值的话,则直接返回叶子节点
int valueIndex = featureIndexList.get(featureIndexList.size() - 1);//标签索引
// 选择第一个值
String firstValue = tableMap.get(dataSetList.get(0)).get(valueIndex);//标签值
int firstValueNum = 0;
for (Integer id : dataSetList)
{
if (firstValue.equals(tableMap.get(id).get(valueIndex)))
{
firstValueNum++;
}
}
if (firstValueNum == dataSetList.size())//所有数据属于同一类
{
Node node = new Node();
node.lastFeatureValue = lastFeatureValue;
node.featureName = firstValue;
node.childrenNodeList = null;
return node;
}
// 遍历完所有特征时特征值还没有完全相同,返回多数表决的结果
if (featureIndexList.size() == 1)//就剩下标签了
{
Node node = new Node();
node.lastFeatureValue = lastFeatureValue;
node.featureName = majorityVote(dataSetList);
node.childrenNodeList = null;
return node;
}
// 获得信息增益最大的特征
int bestFeatureIndex = chooseBestFeatureToSplit(dataSetList, featureIndexList);
// 得到此特征在全局的下标
int realFeatureIndex = featureIndexList.get(bestFeatureIndex);
String bestFeatureName = featureList.get(realFeatureIndex);
// 构造决策树
Node node = new Node();
node.lastFeatureValue = lastFeatureValue;
node.featureName = bestFeatureName;
// 得到所有特征值的集合
List featureValueList = featureValueTableList.get(realFeatureIndex);
// 删除此特征
featureIndexList.remove(bestFeatureIndex);
// 遍历特征所有值,划分数据集,然后递归得到子节点
for (String fv : featureValueList)
{
// 得到子数据集
List subDataSetList = splitDataSet(dataSetList, realFeatureIndex, fv);
// 如果子数据集为空,则使用多数表决给一个答案。
if (subDataSetList == null || subDataSetList.size() <= 0)
{
Node childNode = new Node();
childNode.lastFeatureValue = fv;
childNode.featureName = majorityVote(dataSetList);
childNode.childrenNodeList = null;
node.childrenNodeList.add(childNode);
break;
}
// 添加子节点
Node childNode = createDecisionTree(subDataSetList, featureIndexList, fv);
node.childrenNodeList.add(childNode);
}
return node;
} 10.使用决策树对测试数据进行预测
/**
* 输入测试数据得到决策树的预测结果
* @param decisionTree 决策树
* @param featureList 特征列表
* @param testDataList 测试数据
* @return
*/
public static String getDTAnswer(Node decisionTree, List featureList, List testDataList)
{
if (featureList.size() - 1 != testDataList.size())
{
System.out.println("输入数据不完整");
return "ERROR";
}
while (decisionTree != null)
{
// 如果孩子节点为空,则返回此节点答案.
if (decisionTree.childrenNodeList == null || decisionTree.childrenNodeList.size() <= 0)
{
return decisionTree.featureName;
}
// 孩子节点不为空,则判断特征值找到子节点
for (int i = 0; i < featureList.size() - 1; i++)
{
// 找到当前特征下标
if (featureList.get(i).equals(decisionTree.featureName))
{
// 得到测试数据特征值
String featureValue = testDataList.get(i);
// 在子节点中找到含有此特征值的节点
Node childNode = null;
for (Node cn : decisionTree.childrenNodeList)
{
if (cn.lastFeatureValue.equals(featureValue))
{
childNode = cn;
break;
}
}
// 如果没有找到此节点,则说明训练集中没有到这个节点的特征值
if (childNode == null)
{
System.out.println("没有找到此特征值的数据");
return "ERROR";
}
decisionTree = childNode;
break;
}
}
}
return "ERROR";
} 11.测试结果
outlook
rainy
windy
FALSE
yes
TRUE
no
sunny
humidity
normal
yes
high
no
overcast
yes
转换成图是这样的。
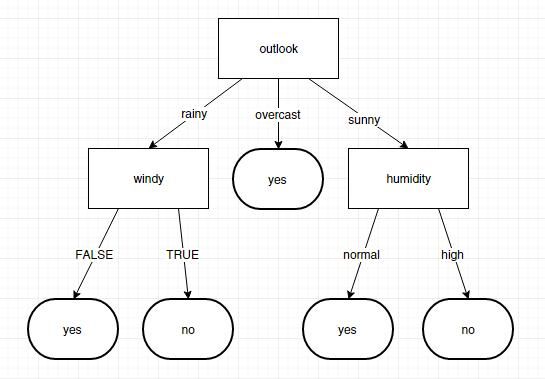
此时输入数据进行测试。
rainy,cool,high,TRUE- 1
得到结果为:
判断结果:no