【NLP】一文理解Self-attention和Transformer
一、自注意力机制
(一)序列与模型
哪些场景是用向量作为输入呢?
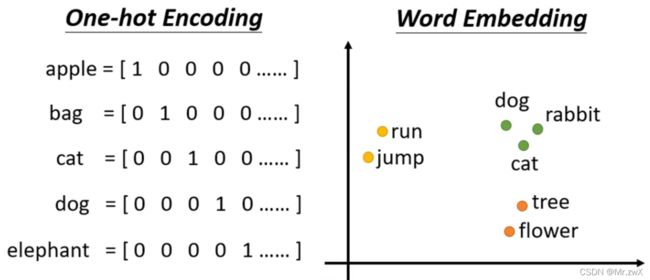
首先是词的表示,表示词的方式:One-hot Encoding(词向量很长,并且词之间相互独立)、Word Embedding。
然后是语音向量和图(Graph)也是由一堆向量组成。
输出可能是什么样的?
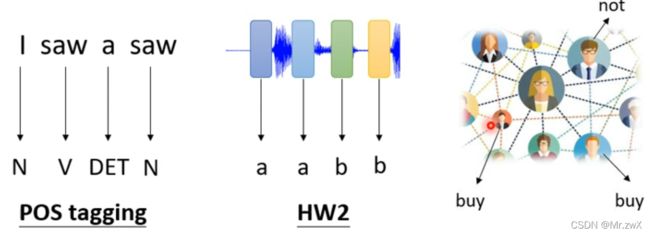
- 每个向量对应一个输出标签(一对一的情况,Sequence Labeling)

例子:词性标注(POS tagging)、语音、社交网络等等。
- 整个序列只有一个输出的标签

例子:文本情感分析(sentiment analysis)、识别语音来源、分析分子的性质等等。

- 模型自决定输出标签的数量
这种任务叫做Seq2Seq,输入一段话,输出一段文字。

Sequence Labeling
对于输入输出一对一的情况,最直接的想法是用很多全连接网络(FCN)来逐个击破输入向量,如下图。
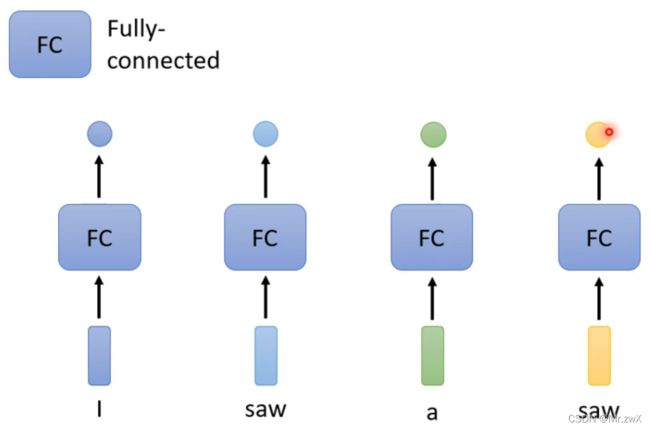
考虑这样做的缺陷,这样做没办法分析上下文关系(context),比如这里的第一个saw是动词“看见”,第二个saw是名词“锯子”,只用上图所示的FCN是没办法识别出两种不同的词性的(在网络中认为两个输入的词向量一模一样,学到的东西也会一样)。
于是,考虑到如下的交叉模型,这样每个词就能考虑到上下文了。
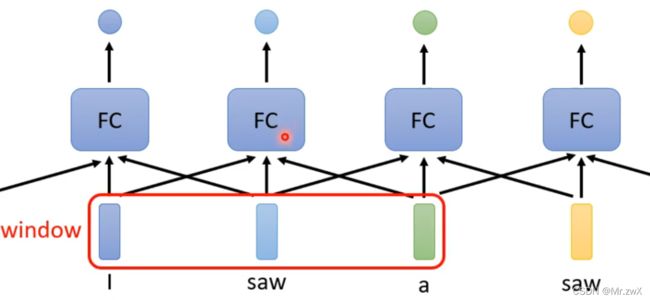
但是这样做有上限,我们如果不考虑一个window,而是考虑整个sequence,应该怎么做呢。可以很直接想到,那单纯把window开大点,不就考虑到了整个sequence吗,但是每次sequence的长度是不同的,这个window需要人为去设定,另外,开太大的window会导致FCN运算量太大并且过拟合(overfitting)。
为了利用好整个sequence的信息,就有了接下来要学习的Self-attention。
(二)Self-attention
1. 架构设计

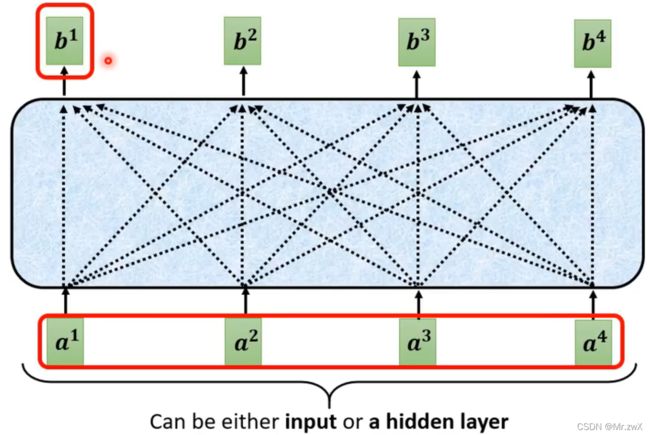
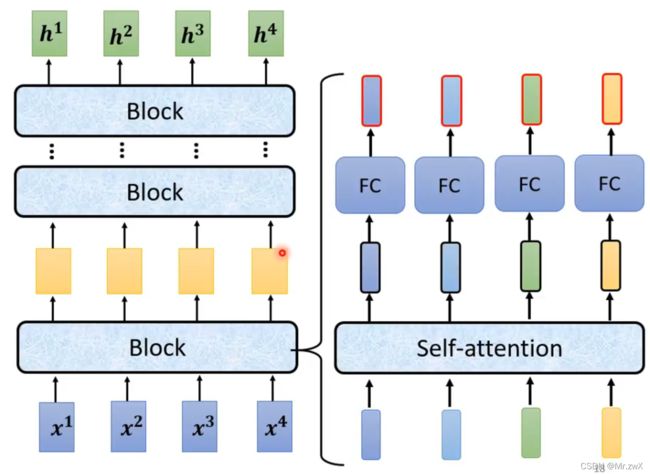
在如上的架构中,带黑框的向量是考虑了整个sequence的信息,再输入FCN中得到对应输出。
Self-attention可以堆叠很多次,再输入FCN得到输出。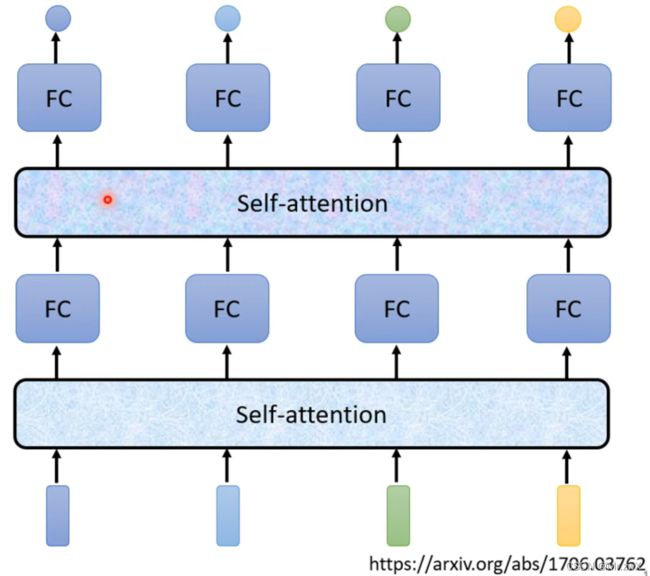
有关Self-attention最经典的论文就是Transformer,源于Google的模型:《Attention is all you need》。
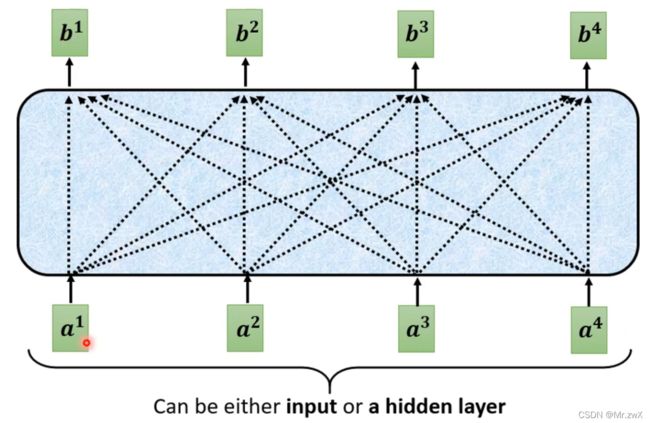
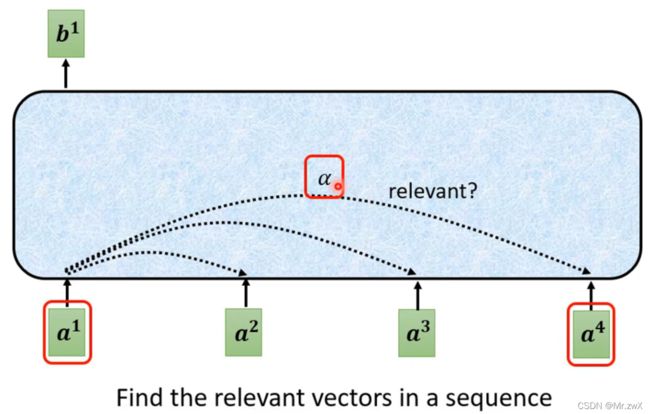
首先要找到每个输入向量与其他输入向量的关系,如下图。
2. Dot-product
现在考虑如何去计算这个相关系数,这里用到的方法是Dot-product,也就是点乘,计算过程如下。将两个向量分别乘上两个权重矩阵 W q W^q Wq和 W k W^k Wk得到 q q q和 k k k向量,然后将两者做dot-product(element-wise相乘求和)得到相关系数。

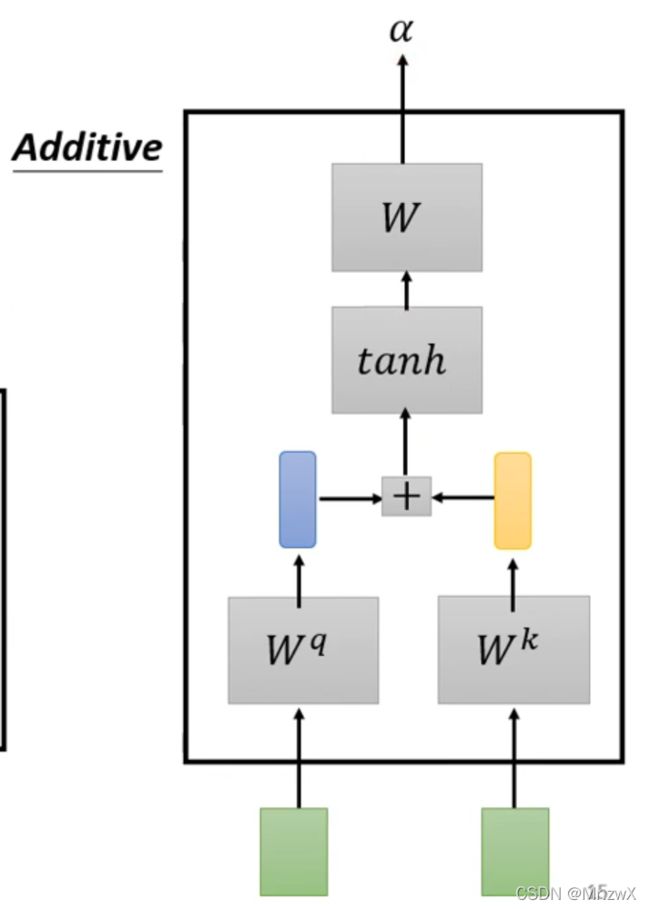
除此之外,还有Additive的方式计算相关系数,不同点在于 q q q和 k k k做加性运算,然后通过activation function(tanh)。
3. Self-attention计算原理
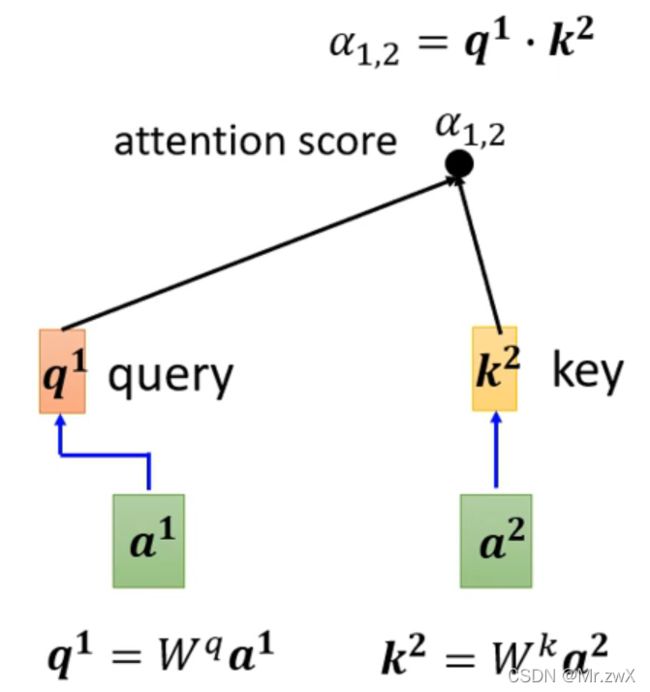
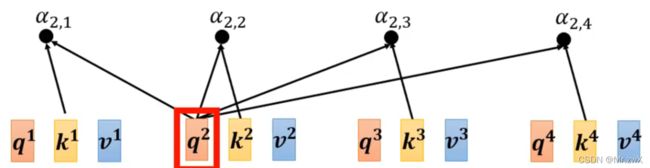
在后面的学习中,采用的是常见的Dot-product方法计算相关性。接下来学习如何计算两两向量之间的相关系数。 如下图,将需要查询的向量 a 1 a^1 a1乘上 W q W^q Wq得到 q 1 q^1 q1,待查询的向量 a 2 a^2 a2乘上 W k W^k Wk得到 k 2 k^2 k2,然后两者做dot-product(element-wise相乘求和)得到attention score α 1 , 2 \alpha_{1, 2} α1,2。
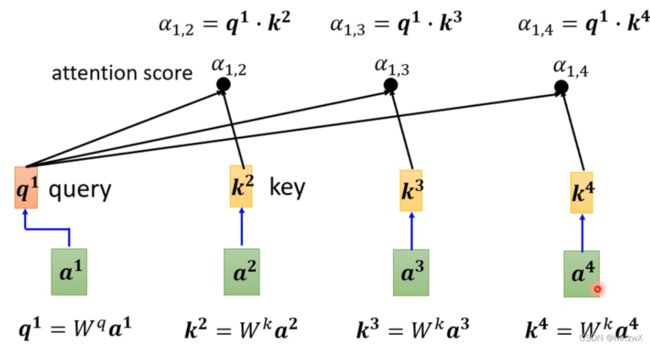
同理,可以计算另外两个向量与第一个向量的相关系数,当然,每个向量也会和自己计算相关系数,如下所示。
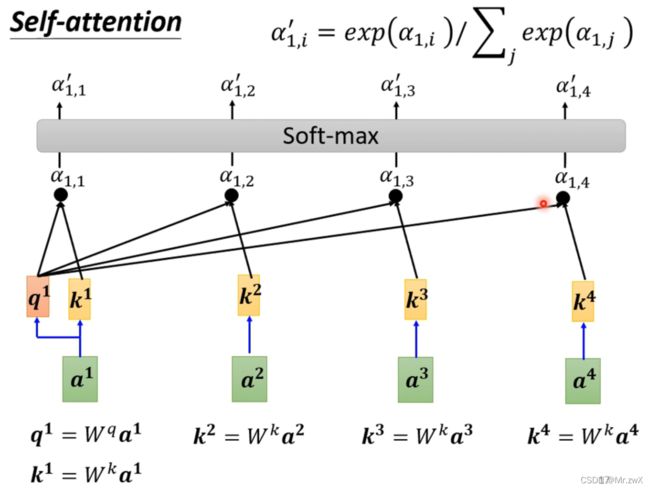
计算出向量与向量之间的相关系数后,通过Softmax函数计算出归一化(normalization)后的相关系数,作为每一个向量对该向量的重要程度(权重)。
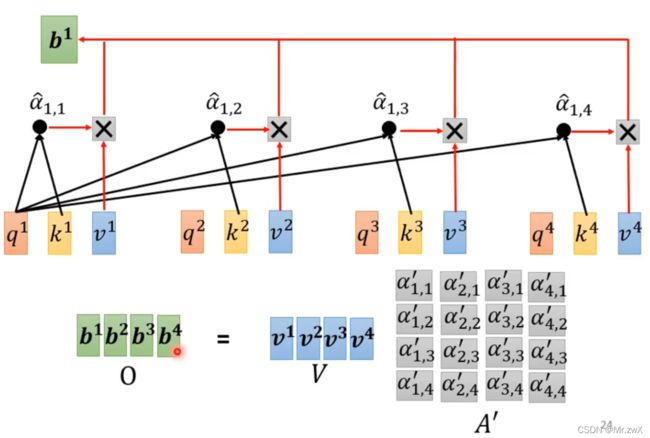
下一步,基于计算出的attention score(前文的相关系数)来抽取信息。用每个输入向量乘上 W v W^v Wv权重矩阵得到 v v v,然后用每个归一化后的相关系数( a 1 , 1 ′ , a 1 , 2 ′ . . . a'_{1, 1}, a'_{1, 2}... a1,1′,a1,2′...)乘上 v v v的值,最后全部求和得到 b 1 b^1 b1,作为 a 1 a^1 a1在考虑了整个sequence的情况下经过self-attention模块得到的输出值。
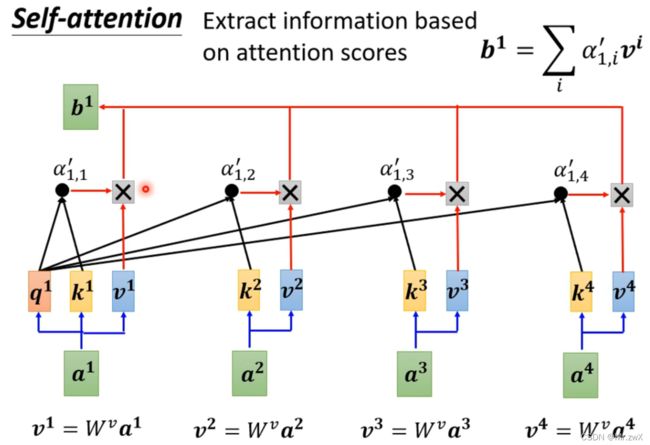
回顾一眼, a 1 a^1 a1在考虑了所有输入的情况下,经过self-attention机制计算得到输出 b 1 b^1 b1的过程。
4. 并行化处理——矩阵乘法角度(向量化)
值得注意的是,计算每个向量的输出时,不需要一个一个顺序执行,而是并行处理的(parallel)。
现在从矩阵乘法的角度来看,是将多个输入向量拼起来成为一个大的输入矩阵,乘上 W W W后得到 Q Q Q,后面同理,用这种矩阵乘法的思想实现了多输入的并行计算,最终得到所有输出值和attention score矩阵(就是吴恩达老师讲的“向量化”)。
下面是得到q、k、v的计算过程:
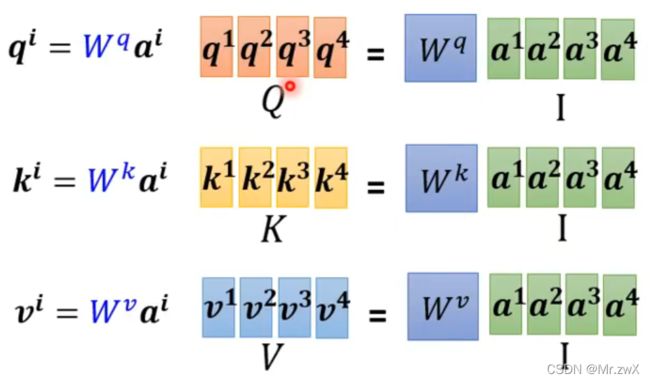
下面是得到相关系数的计算过程:
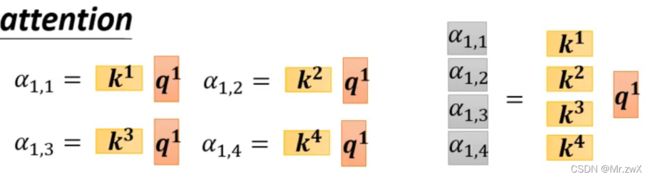

下面是得到输出的计算过程:
总结一下上面self-attention机制的矩阵乘法的计算过程:

其中,只有三个W是需要学习的矩阵。
5. Multi-head Self-attention
多头注意力是现在广泛应用的自注意力方式。用多个不同的 W q W^{q} Wq, W k W^k Wk, W v W^v Wv可学习矩阵去学习不同的相关系数(可能关注点不同,所以更全面地考虑了相关性)。
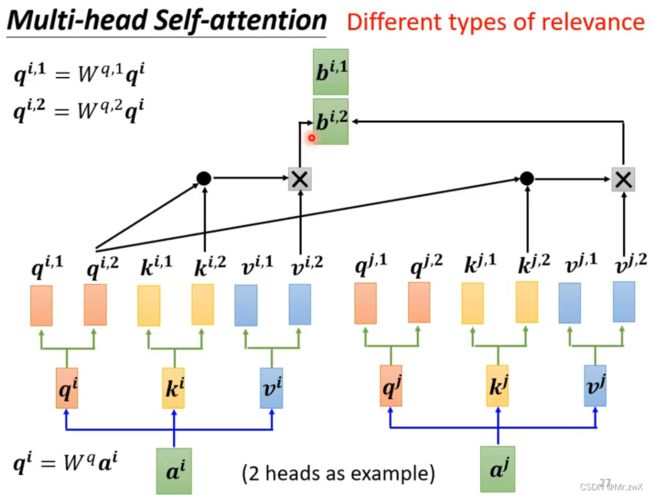
得到多个head的输出后,再通过一次线性计算,得到最终的输出。

6. Positional Encoding
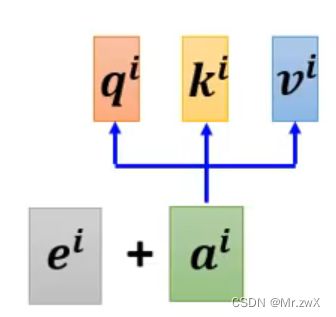
前面学会了self-attention的原理,但是存在一个问题——没有考虑词之间的位置关系,比如第一个向量和第二个向量并没有近,第一个向量和第四个向量并没有远(天涯若比邻),每个向量计算相关系数时是等价的、位置无关的。
在不同的位置加上一个唯一的位置向量(positional vector) e i e^i ei,如下所示:
在Transformer中,人为(hand-crafted)地设定位置向量如下,每一列就是一个位置向量的表示。
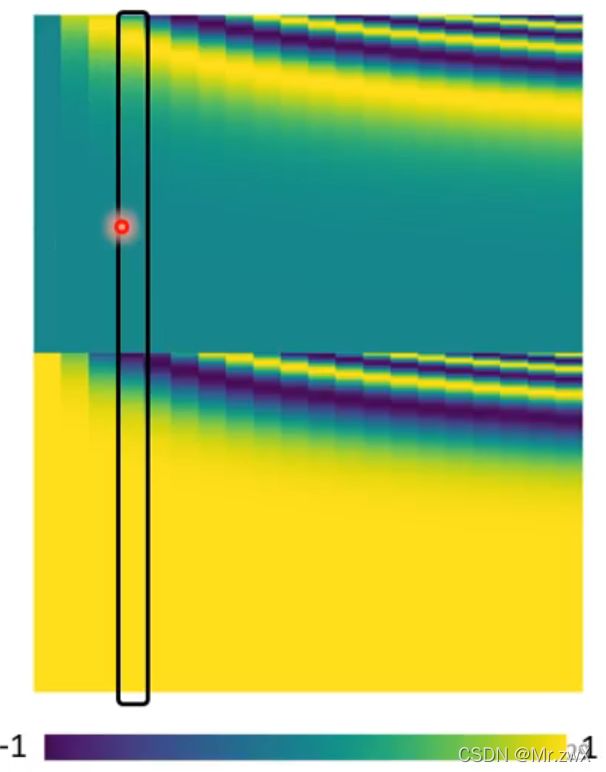
这个positional encoding实际上还是有待研究的问题,可以hand-crafted,也可以生成,可以learn from data。
7. 应用
Transformer和BERT类似的NLP模型广泛应用self-attention机制,还有语音领域、图像领域、Graph…

由于语音问题的向量非常长,所以采用truncated self-attention来关注小范围的相关系数。
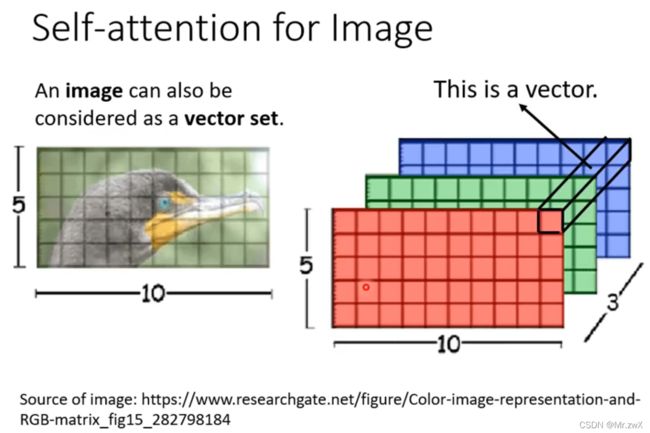
图像问题同样可以看作是长向量问题,如图的1x1x3三维向量就可以作为每个像素点的向量表示,然后用self-attention来处理图片。
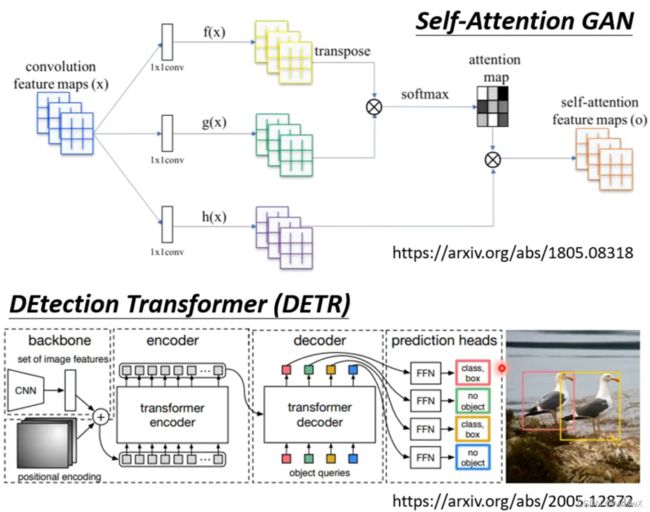
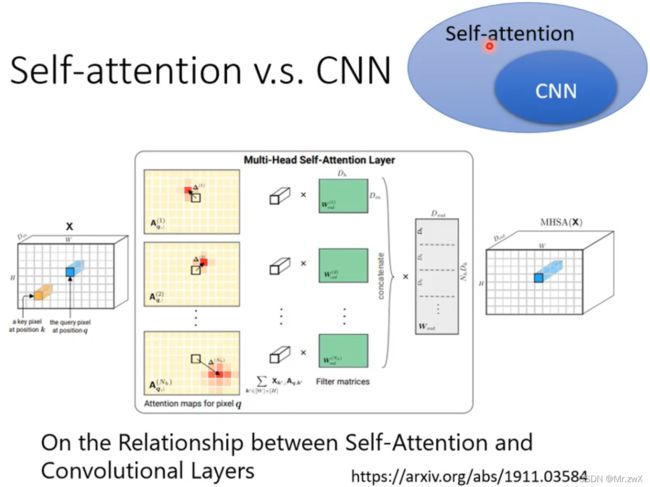
要比较self-attention和CNN,那么CNN实际上是简化版的self-attention,因为只考虑到了局部视野(receptive field)。self-attention可以看作是可学视野的CNN(全局性)。
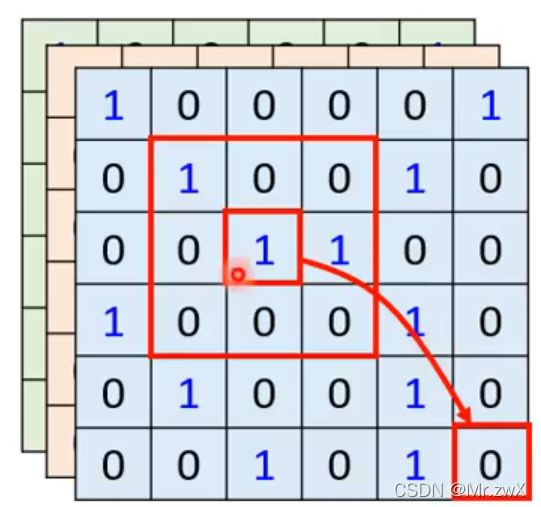
在下面这篇论文中,详细阐述了CNN是self-attention的特例这一观点,如果参数设置合适,self-attention可以做到和CNN完全一样的效果。
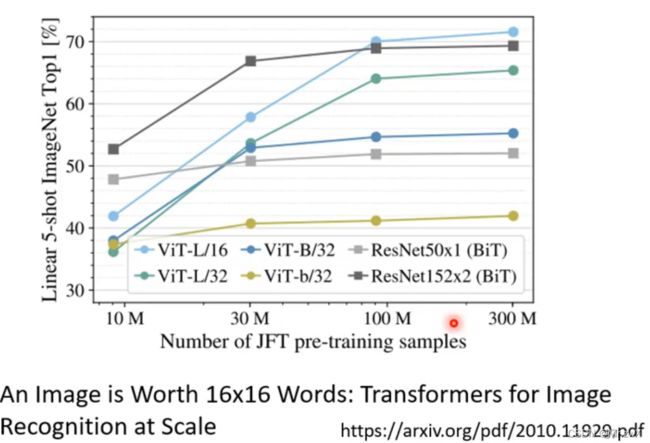
上面的实验结果可以说明,训练数据少的时候,self-attention容易过拟合,而CNN效果好,数据多的时候,self-attention利用了更多的信息,而CNN效果相对差一些。
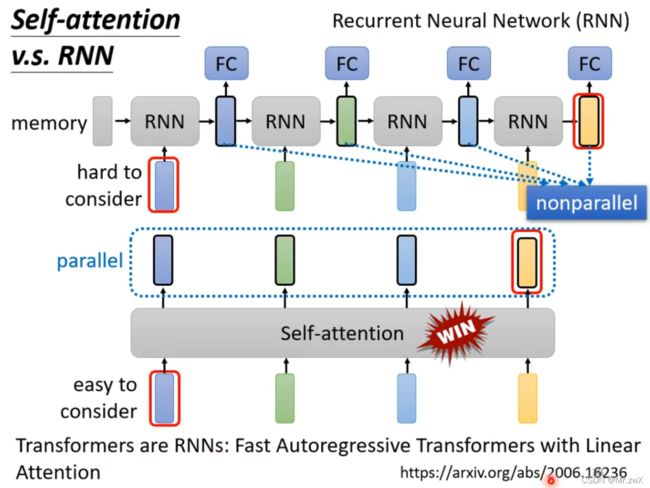
要比较self-attention和RNN(当然是可以双向Bi-RNN,所以RNN是可以考虑到左右侧的上下文关系),self-attention的主要优势是可以考虑到很远很远的输入向量(只需要KQV的矩阵运算,而RNN需要将memory依次计算推进),并且能做到并行处理,同时计算所有向量之间的相关系数。
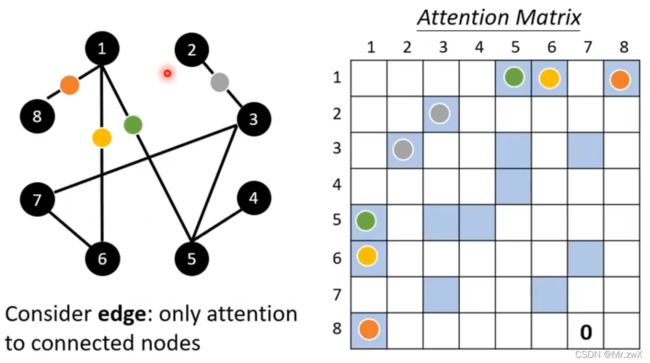
在Graph上可以用self-attention,计算出节点之间边的权重值,其实就是GAT。
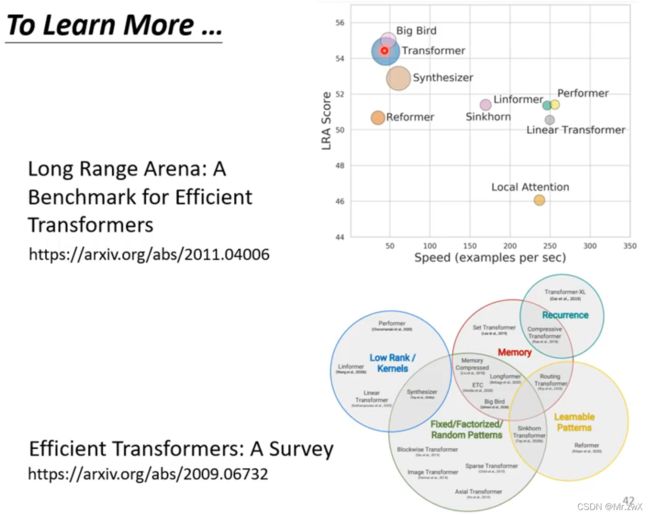
二、Transformer
(一)Sequence to sequence (Seq2seq) 相关应用
序列到序列的模型特点是输入一个序列,输出一个序列,并且输出的长度由模型所决定。

既然语音翻译可以转换为语音识别+机器翻译,为什么要要做语音翻译呢?因为世界上很多语言是没有文字的。
语音翻译(Speech Translation)
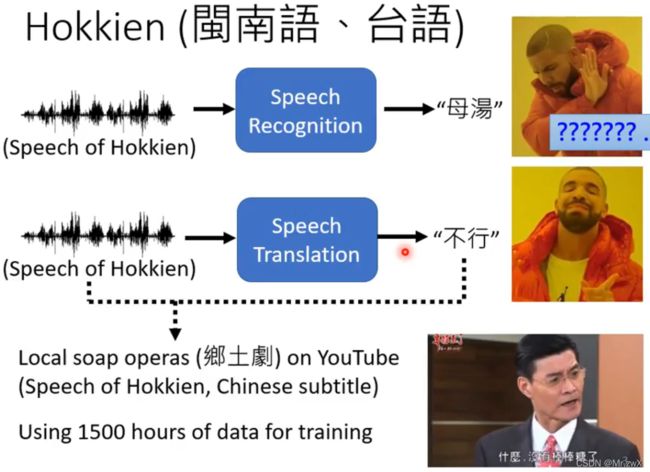
不用去关心背景音乐或噪声、音频和字幕不对应,这种直接倒入数据训练的方式叫“硬 train 一 发”。
语音合成(Text-to-Speech(TTS) Synthesis)

聊天机器人(Seq2seq for Chatbot)

Question Answering(QA)
各式各样的NLP问题可以看作QA问题,QA问题可以用Seq2seq模型解决。


句法分析(Syntactic Parsing)
一定要用seq2seq模型来做句法分析也是可行的,输入输出如下,输出是树状结构。
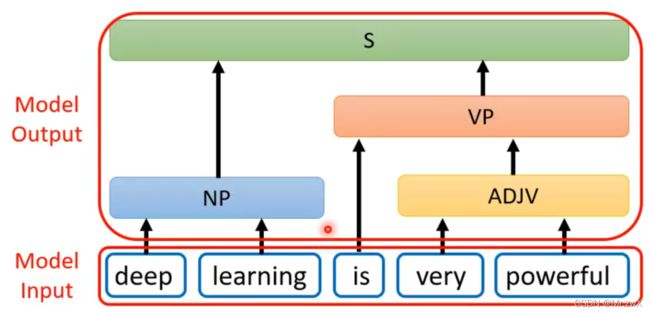
这个树状结构的输出可以看作是一个sequence,然后用seq2seq模型去训练。
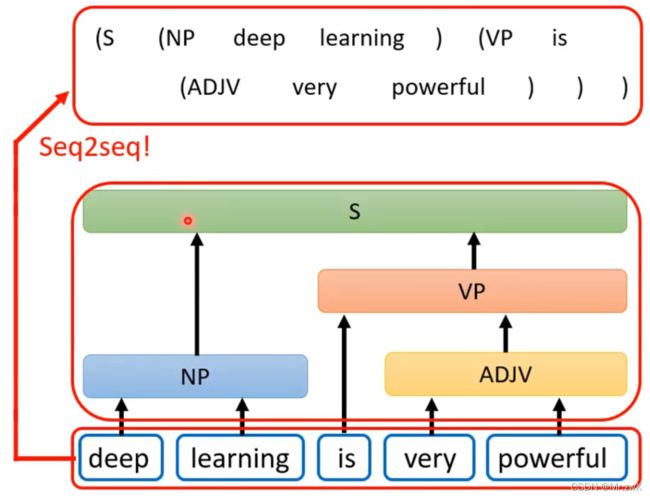
这种做法来源于《Grammar as a Foreign Language》这篇论文。
多标签分类(Multi-label Classification)
同一种物体同时属于不同的类别。

如果用传统分类的想法去做,输入数据,输出得到分类概率前三的类别,作为分类结果。存在一个问题,不同的输入可能有不同数目的类别,如上图。这种问题同样可以seq2seq模型解决,如下图。

目标检测(Object Detection)
介绍了上面这么多seq2seq模型的应用,就是为了说明seq2seq模型实际上是非常强大的模型,可以做很多从序列到序列(尤其是不确定序列长度)的问题。
(二)Transformer原理
首先给出Transformer的架构:
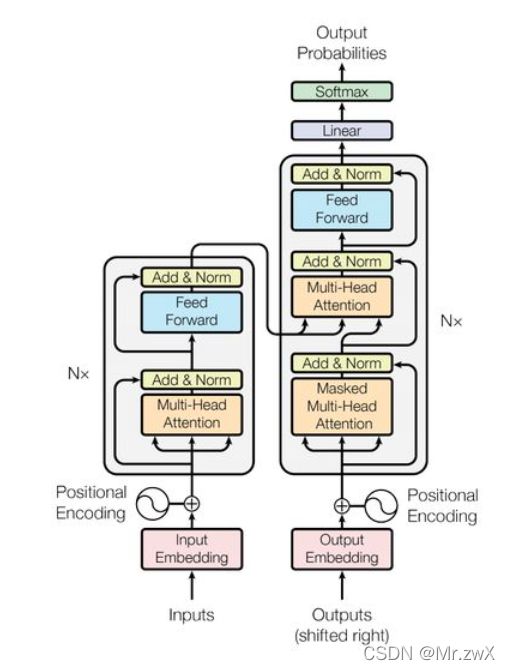
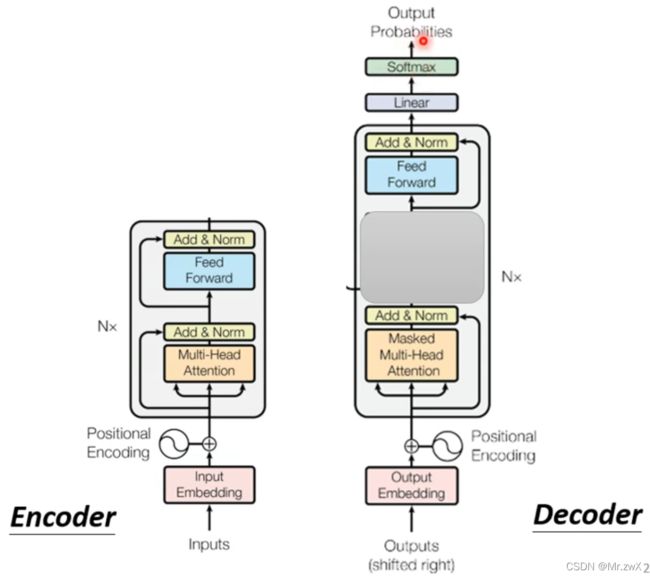
上图中,整个左边部分为encoder,右边部分为decoder。
所以模型主要分为Encoder和Decoder两个部分,后面将从这两部分进行学习。
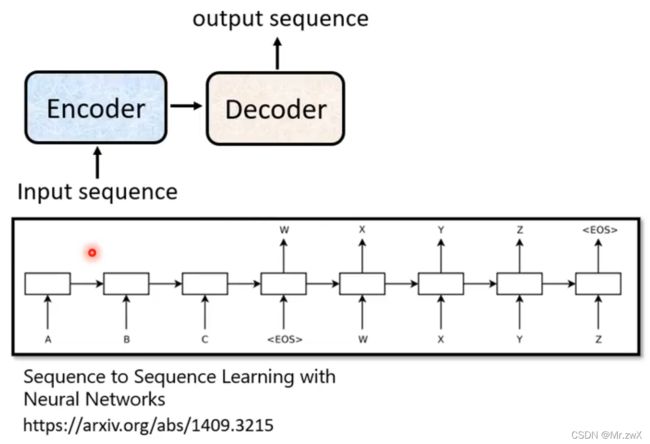
1. Encoder
从输入向量得到输出向量的过程,可以用前面讲的self-attention去做,也可以用RNN和CNN去做 (self-attention可以感知到全局的信息,而不至于计算效率低)。
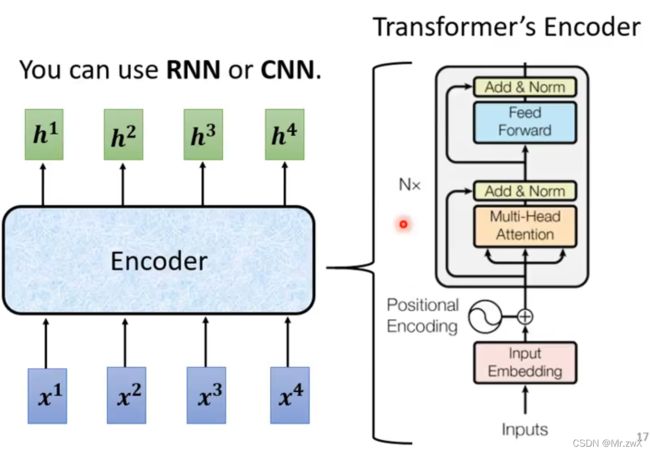
在 Add&Norm 模块中,首先将经过了self-attention后的输出向量与原本的输入向量相加(residual),然后将求和的结果进行layer normalization。
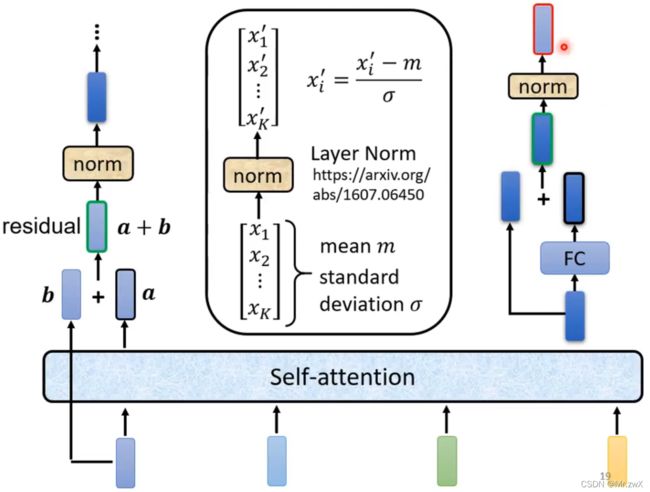
如下图所示,Add步骤即residual,Norm步骤即layer norm。
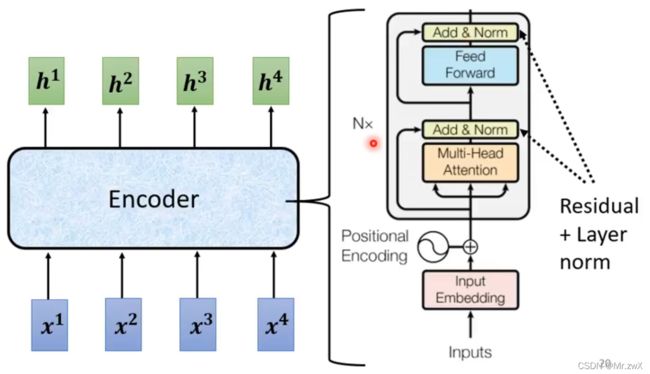
BERT模型就是Transformer的encoder。需要注意的是,Transformer的设计不代表它是最好的,包括不同组件的顺序、Layer Normalization等方面。
对比layer norm和batch norm
首先假设现在有一个batch,batch size = 4,如下:

batch norm对同一个batch中不同data的同一维度做标准化;
layer norm是不考虑batch的,只考虑某一data中各个不同维度做标准化。这种方式通常搭配RNN模型使用,这也是为什么Transformer搭配了layer norm。
2. Decoder——Autoregressive(AT)
通过decoder,输入BOS(Begin of Sequence),输出第一个词的分布,取最大概率对应的词为输出值。
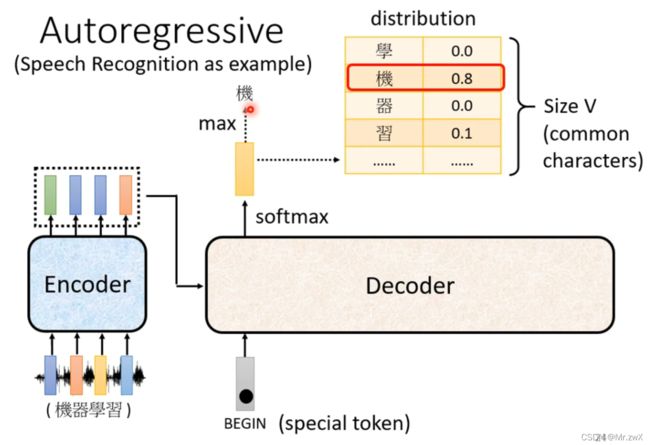
然后将得到的输出和BOS一起作为输入,得到第二个词的分布,并取最大概率值对应的词为输出。
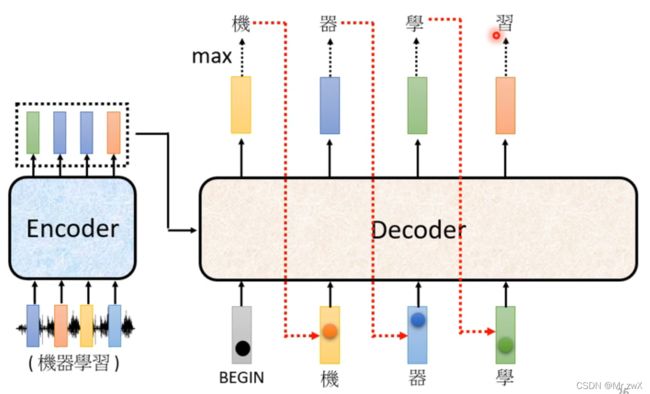
Decoder将自己的输出当作自己的输入,这可能会导致error propagation的问题,一步错,步步错。
下图则是encoder的完整架构,看起来非常复杂。
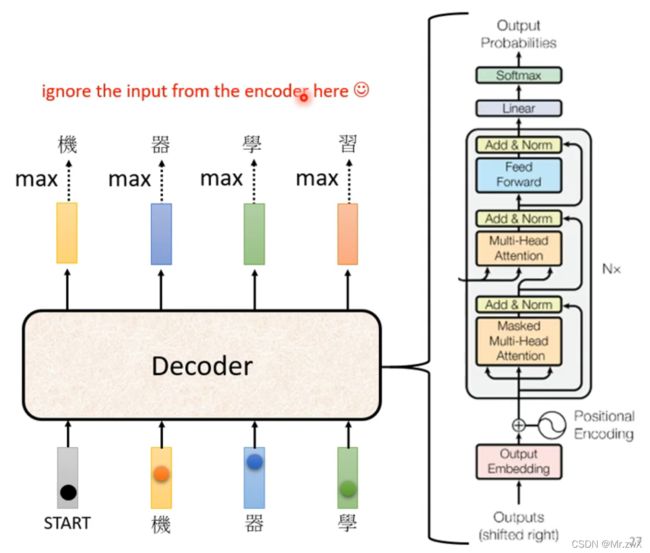
下面先来对比一下encoder和decoder的区别,实际上去掉中间两个组件后,decoder和encoder架构一模一样。
在做decoder的时候,和encoder中的self-attention有什么不同?这个很关键!Decoder中的self-attention也称masked self-attention,计算每个向量与其他向量的相关系数时,只能考虑前面的,不能考虑后面的。 放在下图中,就是断开了与后面部分向量的连接。
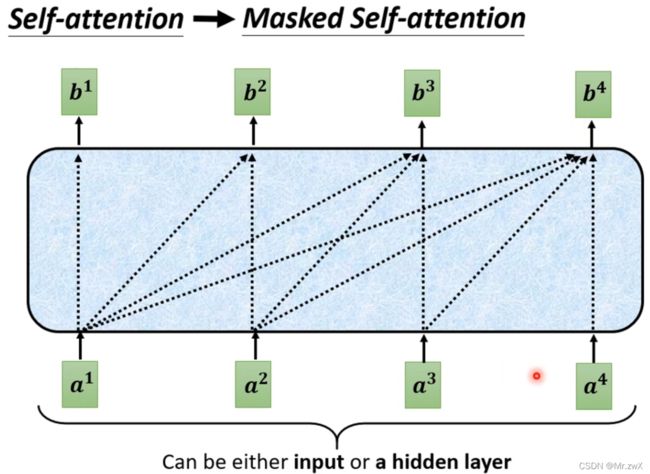
为什么会加这样一种mask?在decoder中,后面的输入实际上还没有到来,所以只能考虑前面部分的输入向量,去做self-attention计算相关系数。
Decoder会面临无止尽的词生成这个问题(如:推特接龙),我们规定遇到END就停止下来。
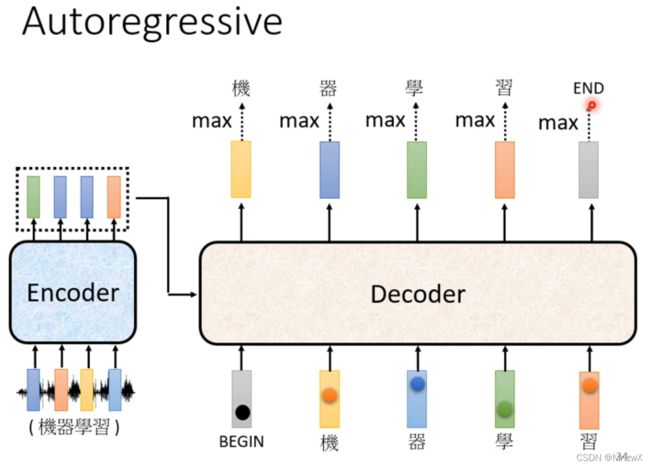
上面就是autoregressive的decoder算法了。下面介绍另一种decoder——Non-autoregressive(NAT)。
3. Decoder——Non-autoregressive(NAT)
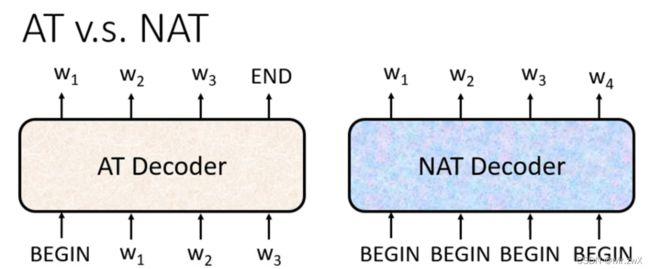
不同于AT将输出作为新的输入,NAT一次性输入并一次性输出。但是,这样会遇到一个问题,我们不明确输出的长度到底是多少,那模型应该如何去确定呢?常用的方法:用另一个预测器去计算输出的长度(一个数值);或输出一个非常长的序列,忽略掉END之后的词。
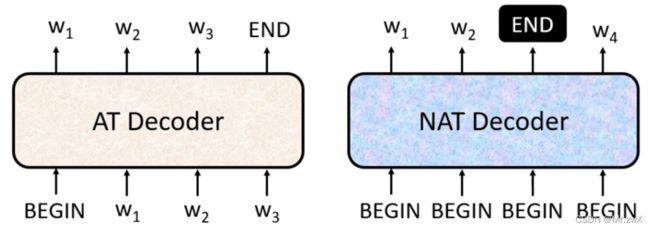
NAT也有其优势,它可以并行化(一次性的输入输出)、可控的输出长度(做语音合成的时候,如果想讲话快一点,就把output长度除以2,讲慢一点就把输出长度乘以2)。NAT通常效果不如AT,原因是multi-modality。
3. Transformer
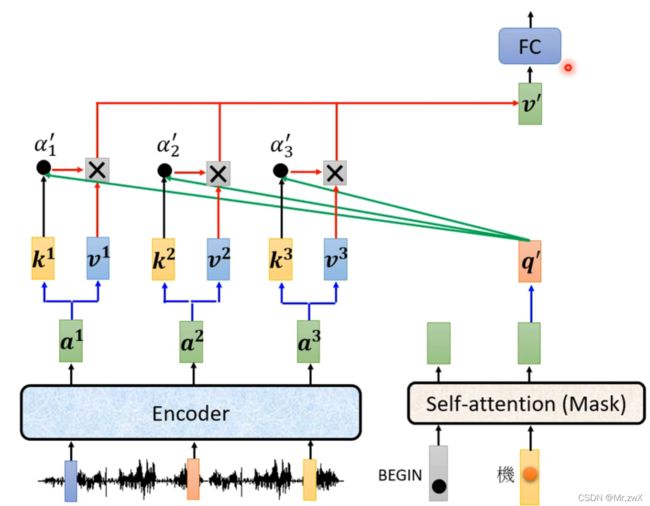
来看一下Transformer的架构中,刚刚被盖住的部分,这部分叫做Cross-attention,两个输入来源于encoder,另一个输入来源于decoder,这个cross-attention部分作为encoder和decoder的连接。
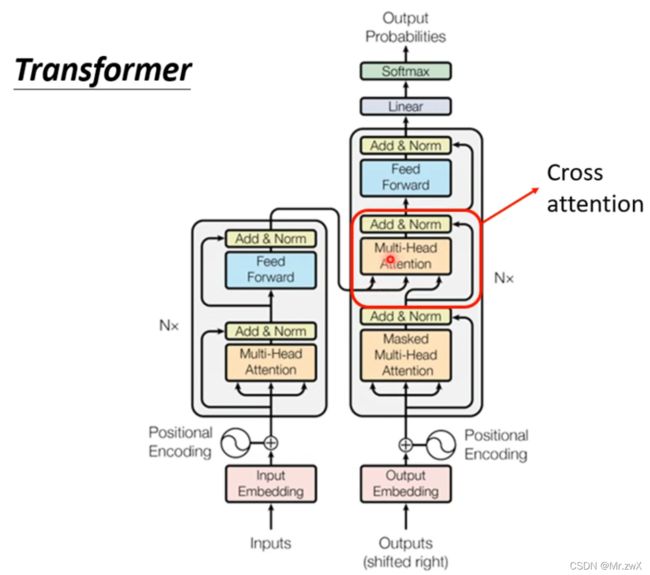
展开看看cross-attention这部分的原理。用encoder产生的 k k k和 v v v与decoder中masked self-attention所产生的 q q q去计算。
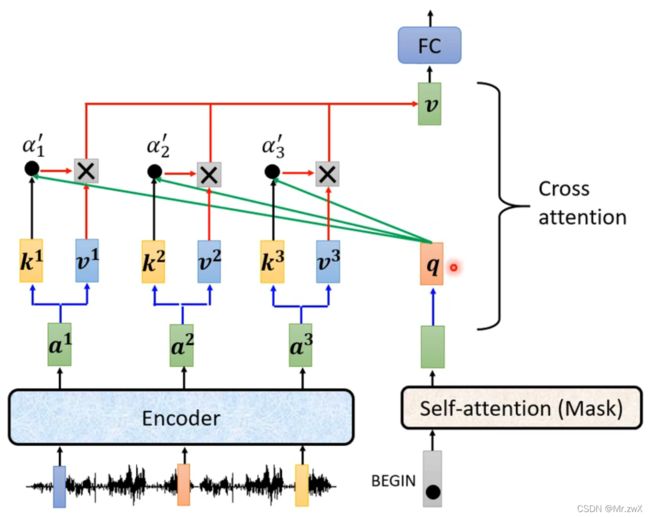
后面的也是同样的原理。
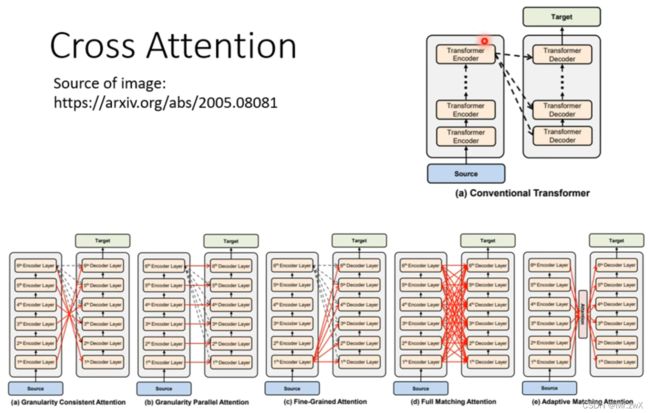
有关cross-attention,可以参考下面这篇论文。

既然decoder有很多层,encoder有很多层,为什么每一层decoder都要去看encoder的最后一层输出呢?其实不一定,下面这篇论文就研究了各式各样的cross attention。
4. Training
收集一系列的声音讯号以及其标签,最终评估效果时需要计算预测结果和真实标签的误差,并不断减小这个误差,实际上也就是在做分类任务中的minimize cross entropy。

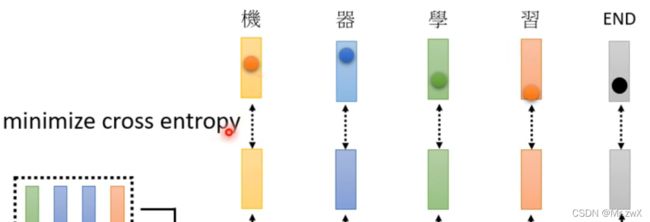
还要记得sequence的末尾是END,所以最后预测出的词也要和END越接近越好。
有一件非常值得注意的事,decoder的输入是真实的标签,如下图。也就是说在有BEGIN的时候,期望decoder输出“机”,在有BEGIN和“机”的情况下输出“器”…以此类推。这个过程叫做Teacher Forcing:用真实标签作为输入。 这个方式一定只是在训练的时候做,测试的时候不能“偷看”到真实的标签!
5. Tips
Copy Mechanism(复制机制)
例如聊天机器人,有一些词可以直接复制出来作为输出,而不需要做过多的理解。

摘要生成(summarization)也是这样一个过程,很多内容直接从原文中复制出来效果更好,需要注意数据集的数量级需要是百万级别的文章数。
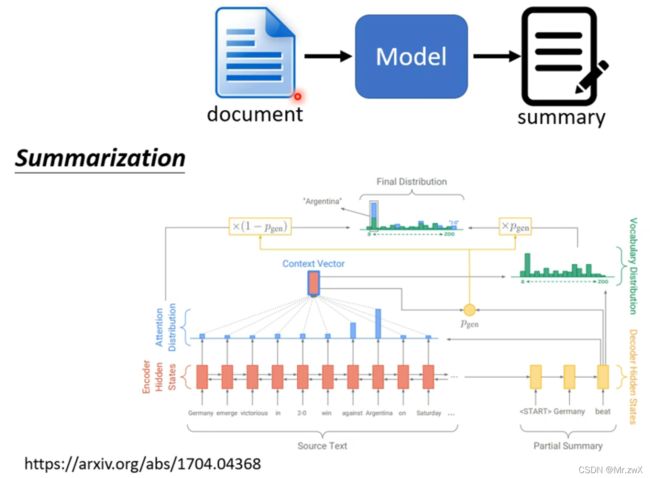
这种Copy Mechanism有其对应的网络,叫做Pointer Network。
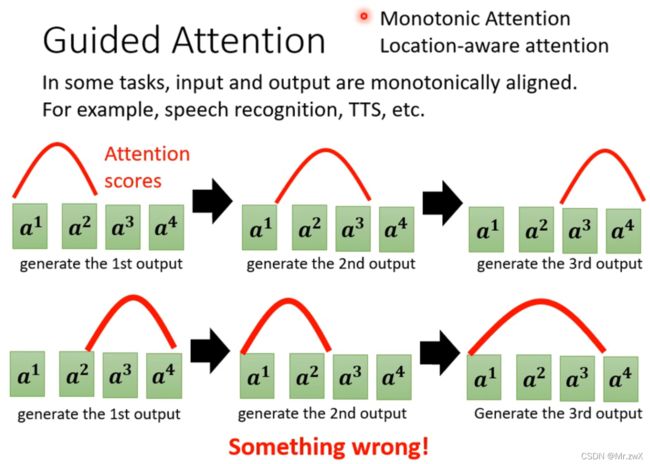
Guided Attention
在一些任务中,输入输出是单调对齐(monotonically aligned)的,比如语音识别和语音合成(TTS),可能会出现计算attention score的顺序时混乱的情况,无法很好得到结果。Guided attention就是强迫attention有一个固定的形式,比如TTS问题需要从左往右计算attention,可以参考Monotonic Attention Location-aware attention。
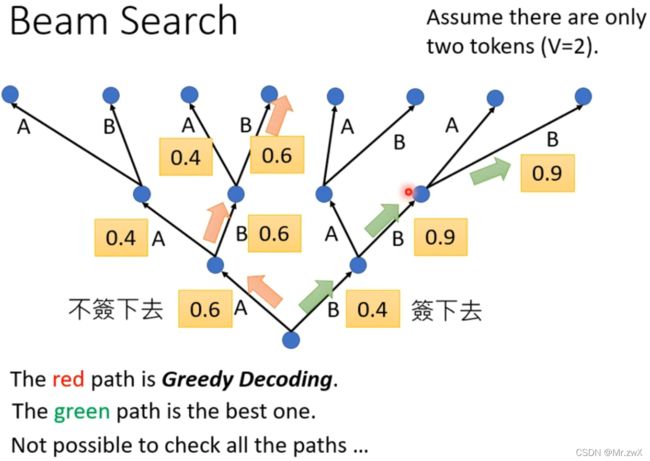
Beam Search

生成序列任务(如完形填空、语音合成)这种有创造性的工作,需要在decoder中加入随机性。 在一般情况下,训练加入noise会带来更强的robustness,而测试的时候不加noise,很有趣的是,在测试时往decoder中加入noise,会带来更好的语音合成效果。
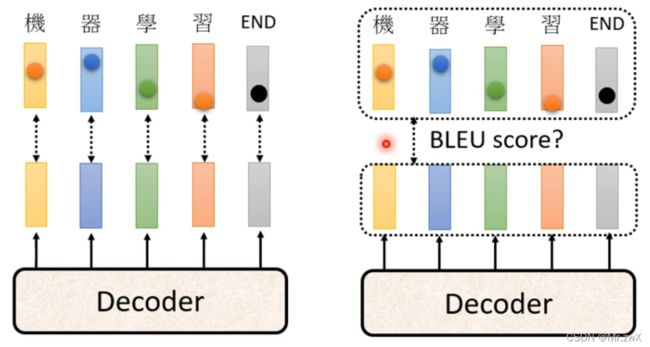
6. 评估指标——BLEU score
在训练的时候,采用minimize cross entropy的方式来优化模型参数,但是最终测试时,是去选择BLEU score最高的模型。为什么不能在训练的时候maximize BLEU呢?BLUE score没有办法做微分!
口诀:如果一定要用无法优化的式子作为指标,用强化学习(reinforcement learning, RL)!
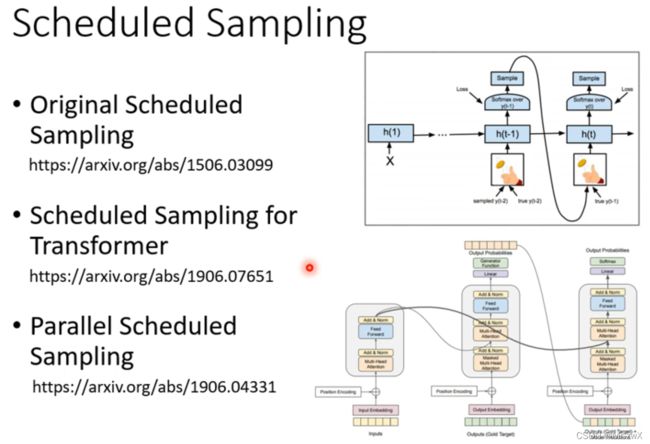
7. Scheduled Sampling——Solve exposure bias
当decoder的输出是错误结果时,这个错误结果会作为接下来的输入,然后导致一步错、步步错。可以考虑的解决方案是给decoder一些错误的词去训练。
8. Self-attention可视化
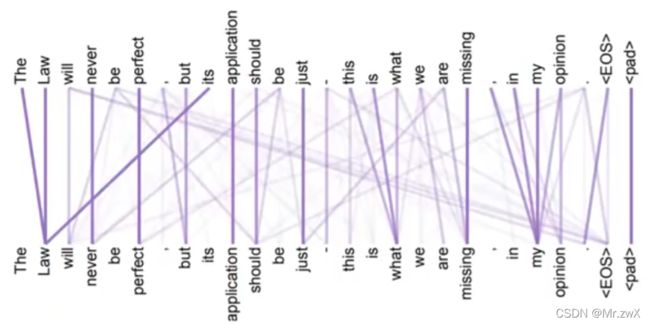

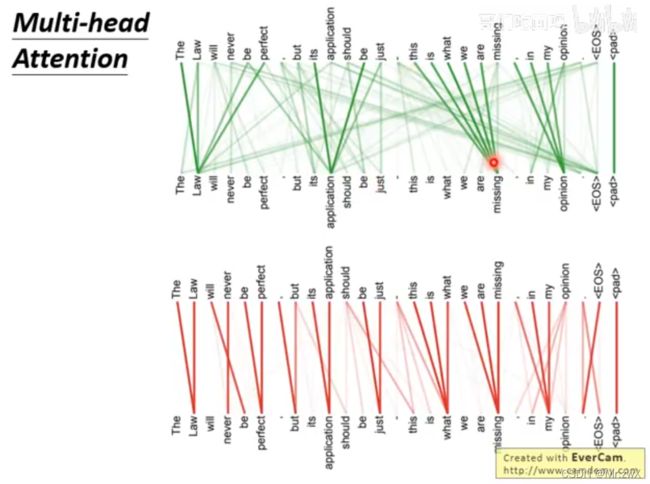
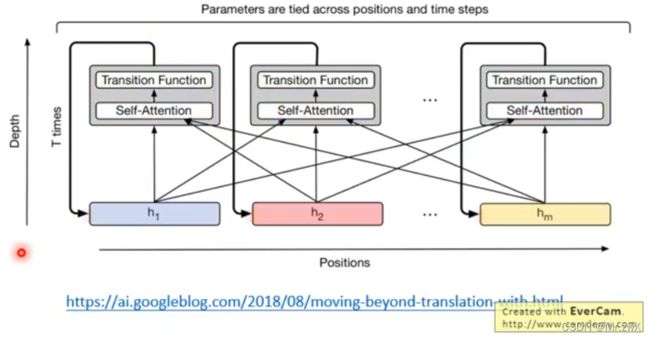
9. Universal Transformer
在深度上,没有用很多不同的Transoformer结构,而是用同一个结构在不同的时间步上使用(RNN)。